Notice
Glitter makes SPARQL : glitter, un package R pour explorer et collecter des données du web sémantique - PANELS
- document 1 document 2 document 3
- niveau 1 niveau 2 niveau 3
Descriptif
La collecte de données du web sémantique, qui sont formalisées selon le modèle RDF, nécessite l’élaboration de requêtes dans le langage dédié SPARQL. Ce langage, qui est aux données du web sémantique ce que SQL est aux bases de données relationnelles, a ainsi un objectif très spécifique et demeure assez méconnu des utilisateurs de données.
Au contraire, R est un langage de programmation assez généraliste puisqu’il permet de gérer de nombreux aspects de la chaîne de traitements de données, depuis leur recueil jusqu’à leur valorisation (par des modèles, graphiques, cartes, rapports, applications, etc.).
Le package glitter permet aux utilisateurs de R sans connaissance préalable de SPARQL (analystes de données, chercheurs, étudiants) d’explorer et collecter les données du web sémantique. Par des commandes R, l’utilisateur peut générer des requêtes SPARQL, les envoyer aux points d’accès de son choix, et recueillir les données correspondantes. Ces étapes sont ainsi intégrées à l’environnement R dans lequel l’utilisateur peut également réaliser les étapes d’analyse et de valorisation des données, dans une chaîne de traitement reproductible.
Lors de cette présentation, Lise Vaudor montrera les principales fonctionnalités du package glitter à partir d’exemples. Le package est toujours en développement mais il est fonctionnel, documenté et peut être installé par les participants qui souhaitent le tester en suivant les instructions décrites sur cette page.
Sur le même thème
-
-
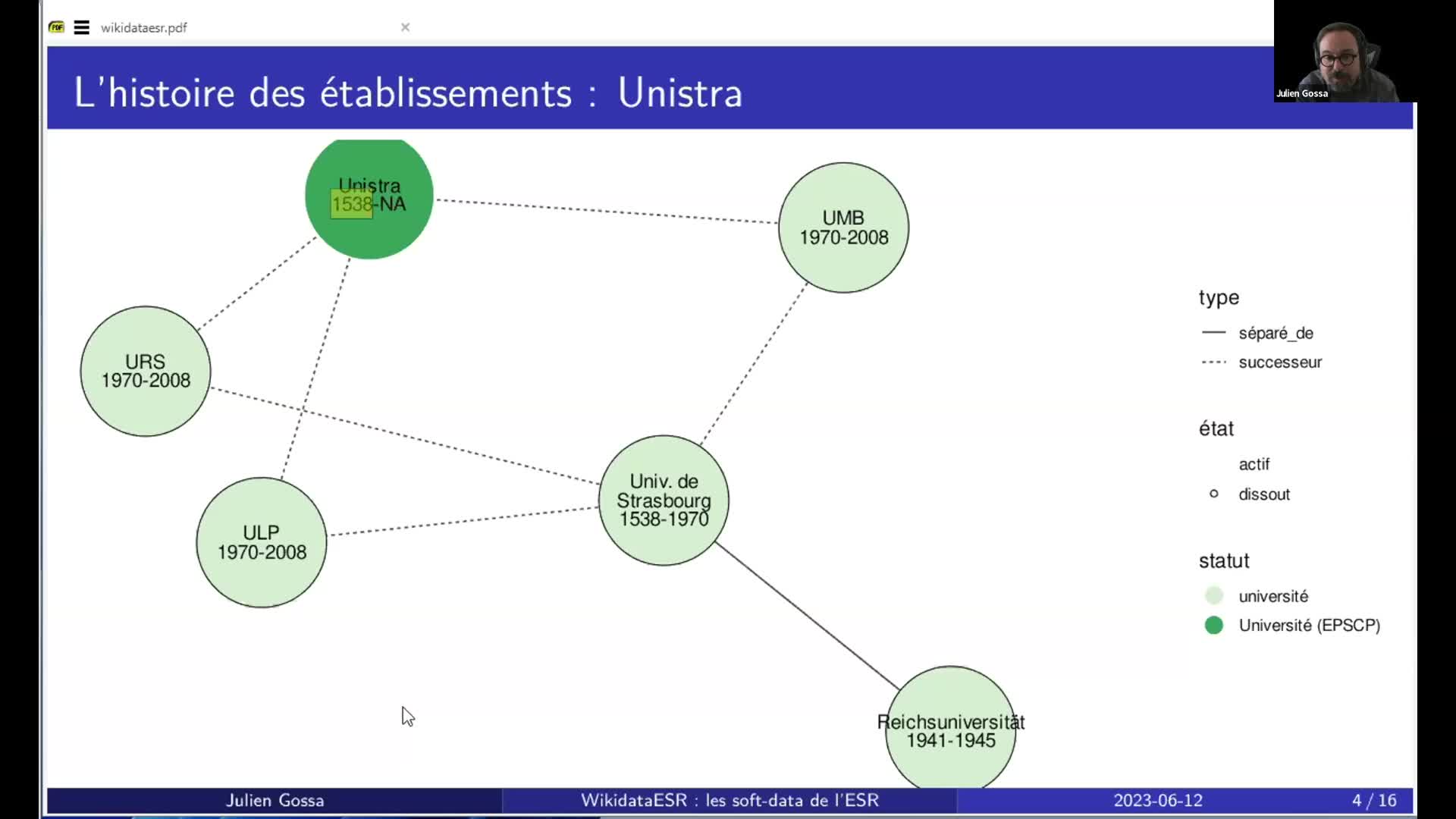
Données de la recherche et Wikidata
GodefroidCélianGossaJulienBeaudouinPierre YvesWikidata est une base de données structurées, libre, collaborative et exploitable pour de nombreux projets numériques et web.
-
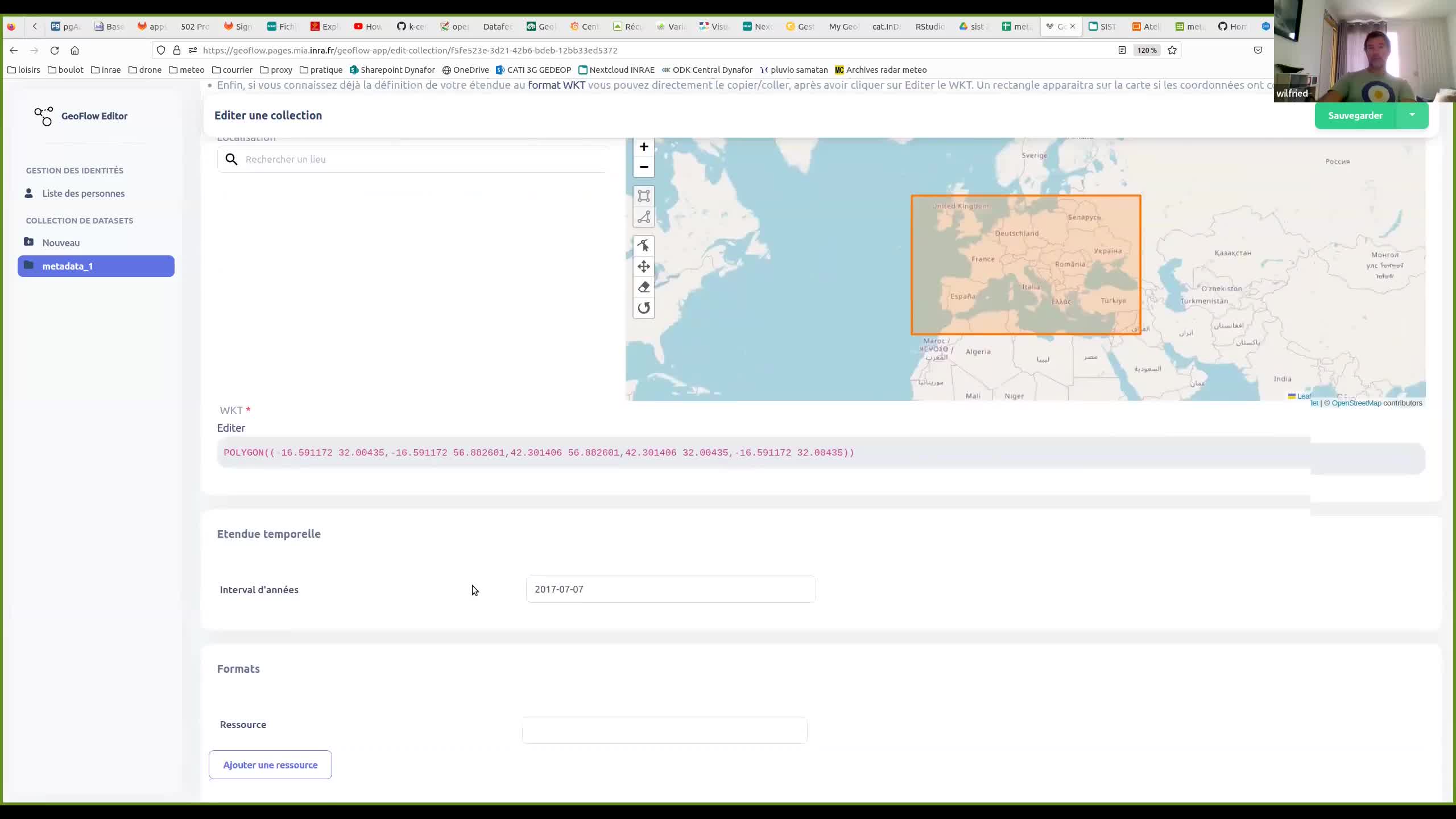
Formation SIST R geoflow 19/06/23
HeintzWilfriedFormation à distance à l'outil R geoflow d'orchestration de flux de (méta)données
-
Publication de jeux de données dans le projet HiperBorea
OrgogozoLaurentHiperBorea est l'acronyme pour High Performance computing for quantifying climate chnage impacts on Boreal Areas.
-
-
Panorama des formations au droit des données et des logiciels
BarrioAmélieAmélie BARRIO (co-responsable de l'URFIST Occitanie)
-
Semaine Numérique des Urfist - Corpus, Données et Métadonnées
BatsRaphaëlleDésos-WarnierCatherineGaultier-VoituriezOdileBougonPaulineDetchemendySylvaineFormaglioCécileHalczukAgnieszkaAbelaCarolineCette session s'inscrit dans le cadre de la Semaine Numérique des Urfist #SNU2023 organisée intégralement en ligne du 27 au 31 mars 2023 par le Réseau URFIST.
-
Introduction to research data
BatsRaphaëlleIntroduction aux données de la recherche : présentation en anglais auprès des doctorants.
-
Formation webinaire R geoflow - Démo et TP (2/2)
HeintzWilfriedDémonstration de l'exécution de geoflow dans R shiny, explication des tableaux de métadonnées et TP
-
Formation webinaire R geoflow - Topo introductif (1/2)
HeintzWilfriedTopo introductif de Wilfried Heintz (INRAE - UMR Dynafor Toulouse) sur R geoflow (support PDF produit par Emmanuel Blondel)
-
Présentation de netCDF (teaser)
LibesMauriceJeannaudVietQu'est-ce que netCDF et pourquoi l'utiliser dans ses travaux de recherche ? Quelques éléments de réponse dans cette courte présentation.
-
Introduction aux données de la recherche
BatsRaphaëlleCette formation d'introduction aux données de la recherche, animée par Raphaëlle Bats, a eu lieu le 22 septembre 2022 à Pau. Elle a été organisée par l'Urfist de Bordeaux et l'Université de Pau et