Notice
Accélération d'un algorithme de feature engineering en Python sur un cluster HPC avec Dask
- document 1 document 2 document 3
- niveau 1 niveau 2 niveau 3
Descriptif
Dans un contexte industriel, lorsqu'un processus d'intelligence artificielle (IA) est mis en production, celui-ci repose toujours sur les cinq étapes suivantes :
1. collecte de données primaires,
2. nettoyage et enrichissement des données (étape dite de feature engineering),
3. apprentissage,
4. prédiction,
5. visualisation.
Il est communément admis que la qualité prédictive d'un algorithme d'IA dépend principalement de la qualité et de la diversité des données utilisées lors de l'apprentissage du modèle. La génération de données dites dérivées (moyennes et écarts types glissants, corrélation entre plusieurs variables, variations, etc.) constitue un moyen efficace d'enrichir et de diversifier les données primaires collectées et représente donc une étape clé dans tout processus industriel reposant sur l'IA.
Il est important de remarquer que l'étape de feature engineering peut produire une quantité arbitrairement grande de variables dérivées. Les avis des experts métier permettent certes de filtrer cet ensemble de variables en ne retenant que les plus pertinentes, mais le nombre de variables retenues est souvent très supérieur au nombre de données primaires. Il est également à noter que la complexité du processus est accrue du fait que certaines données dérivées peuvent elles-mêmes dépendre d'autres données dérivées dans leur construction. C'est pourquoi la génération de ces données nécessite le développement d'un code flexible capable de prendre en entrée des données primaires ou dérivées, et de spécifier des opérations de transformation sur ces données. La dépendance entre certaines données dérivées impose de penser l'exécution des calculs comme le parcours d'un graphe de calcul acyclique.
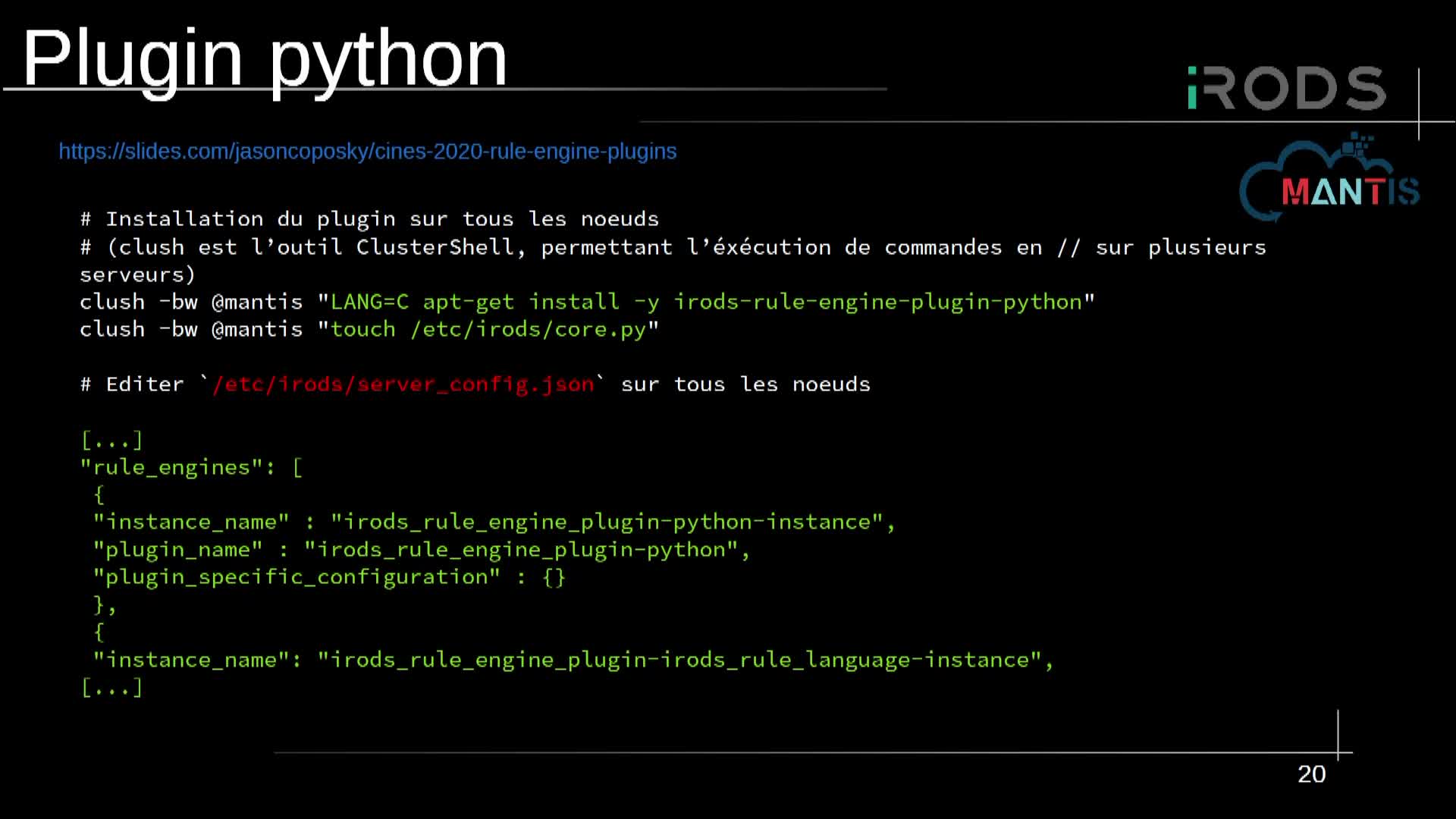
Le challenge que nous nous sommes donné est d'optimiser la performance de ce code en utilisant le calcul distribué. Nous avons ainsi développé un code de feature engineering, implémenté en Python et utilisant Dask pour définir le graphe de calcul et gérer la distribution. Ce code permet d'effectuer des milliers d'opérations de complexité variable sur une grosse masse de données primaires, sans faire exploser la mémoire vive et en un temps raisonnable.
Dask est une bibliothèque gratuite et open-source de calcul parallèle orienté analyse de données. Dask se base sur différentes approches pour la parallélisation des tâches : multiprocessing, cluster Kubernetes, ordonnanceur de tâches (PBS, Slurm, ...) et supporte l'environnement MPI.
Pour cette étude, le code a été exécuté avec sur un cluster sur GCP géré via Kubernetes, ainsi que sur le cluster Myria du CRIANN en MPI, où il a été porté en utilisant l'approche dask_mpi d'une part et l'approche dask_jobqueue, qui utilise l'ordonnanceur Slurm, d'autre part. L'objectif est de comparer les performances et les coûts de ces deux approches à celle de l'exécution de l'algorithme sur GCP via Kubernetes. De plus, un retour d'expérience sera fait sur le portage du code, initialement développé pour Kubernetes, sur le Myria.
Thème
Documentation
Dans la même collection
-
-
-
-
-
-
-
-
Recherche Data Gouv : un écosystème au service du partage et de l'ouverture des données de recherche
Un écosystème au service du partage et de l’ouverture des données de recherche
-
-
-
Refroidissement par immersion de serveurs : premiers retours opérationnels
Le refroidissement par immersion n'est pas une nouveauté, de l'IT en général au HPC en particulier. Il y a 35 ans, les Cray-2 et successeurs avaient leur assemblage de tours immergées dans un fluide
-