Notice
Deux nouvelles plateformes de stockage et de calcul au CNES pour rapprocher les traitements des données
- document 1 document 2 document 3
- niveau 1 niveau 2 niveau 3
Descriptif
Deux nouvelles infrastructures de stockage et de traitement ont été mises en production entre fin 2022 et mi-2023 au sein du Centre de Calcul du CNES avec les objectifs suivants :
- Améliorer le partage des données scientifiques et spatiales et répondre au besoin de passage à l'échelle avec les nouvelles missions spatiales (Volume à la mise en place = 75PO)
- Mettre à disposition des utilisateur du "Système d'information Scientifique" du CNES une interface de stockage interopérable avec des partenaires externes (Centre de Calcul, Plateforme de Cloud)
- Rapprocher les moyens de stockage et de traitement au sein d'un réseau unique et haute performance (100Gbs)
Les éléments mis en œuvre pour répondre à ces nouveaux besoins sont basés sur deux services (Datalake et HPC) travaillant de concert.
Le Datalake :
- Mise en place d'une solution de stockage globale pour les données du CNES en mode Object Storage (Changement de paradigme par rapport à l'historique POSIX pour préparer l'interopérabilité avec les approches Cloud / ESA)
- Volume de stockage important à travers deux classes de stockage Disque et Bandes via une API conforme au standard AWS S3 et Glacier (35PO Disque et 35PO Glacier)
- Répondre aux besoins de performances des projets et des enjeux de maîtrise de l'impact environnemental (Stockage Froid à faible consommation électrique)
- Intégration de la solution dans l'écosystème de traitement (Calcul) et diffusion
Le nouveau supercalculateur (Trex - HPC6G) :
- Supercalculateur orienté HTC avec un volume de 10PO de stockage GPFS (ESS3500 pour les metadatas et le burst, NL-SAS pour le stockage des données projets)
- Nouveaux services : Kubernetes et métrologie accessible aux utilisateurs (heures CPU, volumétrie des données et kW consommés)
- Amélioration du service Datalabs existant (Jupyter + Virtual Research Environnement)
- Une gamme d'installations mutualisées et adaptées à l'architecture du cluster et une automatisation de ces installations mise en place avec Spack
- Une interface avec les outils de la forge logicielle : GitLab, jenkins, GitLab-CI, Artifactory et SonarQube
- Une documentation détaillée de nombreux cas d'usage (calcul parallèle, IA, embarrassingly parallel) adaptée à des utilisateurs aux compétences "variées" (du débutant à l'expert)
L'originalité de la solution proposée est le choix d'un stockage Objet sur le Datalake versus POSIX sur la plateforme de calcul, une fonction Glacier (sur une installation "On Premise" du CNES) et un accompagnement fort des utilisateurs pour changer leur pratique.
Les premiers résultats positifs seront présentés :
- Maturité du composant de stockage sur disque (mode distribué)
- Bon respect du standard AWS S3 sur cette partie
- Intégration avec le référentiel d'identité existant (IPA/LDAP) malgré la logique différente en object storage
Nous aborderons également les écueils et les limites auxquels nous sommes confrontés :
- Faible maturité de l'intégration Bande et nombre d'acteurs limité (aujourd'hui mais en évolution)
- Difficulté d'appropriation du modèle par les utilisateurs
- Niveaux de compatibilité des frameworks (Mapserveur, Orchestrateur, ...) de traitements ou librairies de données (NetCDF, Format optimisé Cloud)
Thème
Documentation
Dans la même collection
-
Table ronde et discussions : infrastructures de calcul et ateliers de la donnée de recherche Data G…
CastexStéphanieRenardArnaudAlbaretLucieRenonNicolasDufayardJean-FrançoisPARTIE 5 : Des interactions croisées, à propos des compétences
-
Table ronde et discussions : infrastructures de calcul et ateliers de la donnée de recherche Data G…
CastexStéphanieRenardArnaudAlbaretLucieRenonNicolasDufayardJean-FrançoisPARTIE 2 : Les ateliers de la données
-
Table ronde et discussions : infrastructures de calcul et ateliers de la donnée de recherche Data G…
CastexStéphanieRenardArnaudAlbaretLucieRenonNicolasDufayardJean-FrançoisPARTIE 7 : Conclusion
-
Table ronde et discussions : infrastructures de calcul et ateliers de la donnée de recherche Data G…
CastexStéphanieRenardArnaudAlbaretLucieRenonNicolasDufayardJean-FrançoisPARTIE 4 : Des interactions croisées, liens entre le calcul et les données.
-
Table ronde et discussions : infrastructures de calcul et ateliers de la donnée de recherche Data G…
CastexStéphanieRenardArnaudAlbaretLucieRenonNicolasDufayardJean-FrançoisPARTIE 1 : Introduction et présentation des intervenants
-
Table ronde et discussions : infrastructures de calcul et ateliers de la donnée de recherche Data G…
CastexStéphanieRenardArnaudAlbaretLucieRenonNicolasDufayardJean-FrançoisPARTIE 6 : L'accompagnement autour de la gestion des données
-
Table ronde et discussions : infrastructures de calcul et ateliers de la donnée de recherche Data G…
CastexStéphanieRenardArnaudAlbaretLucieRenonNicolasDufayardJean-FrançoisPARTIE 3 : les liens entre les structures
-
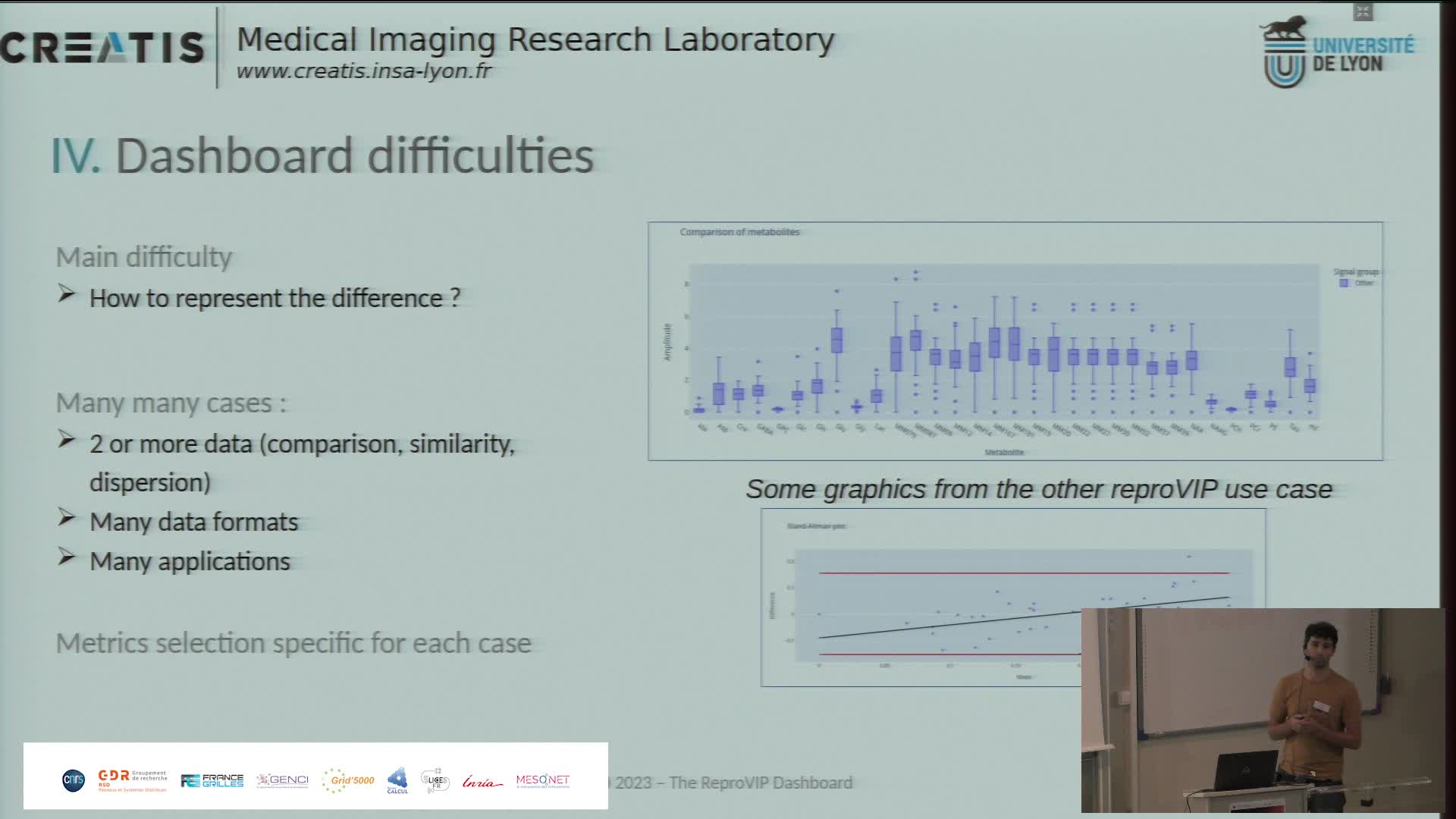
Présentation du dashboard ReproVIP pour visualiser la reproductibilité dans l'imagerie médicale
BonnetAxelLa plateforme d'imagerie virtuelle VIP [1] (https://vip.creatis.insa-lyon.fr) est un portail web de simulation et d'analyse d'images médicales. Elle existe depuis plus de 10 ans et a évolué pour
-
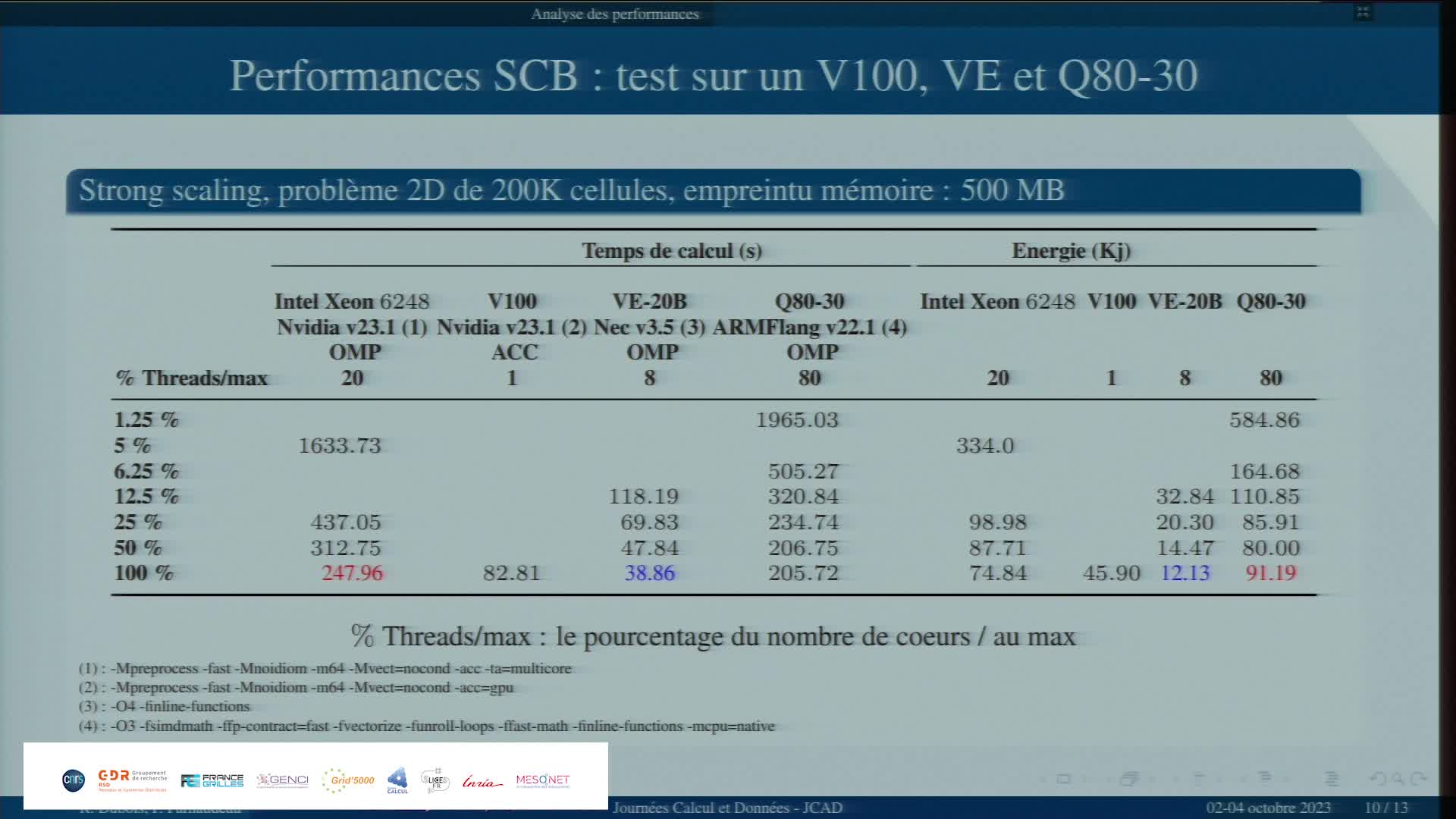
Etude comparative de 3 architectures spécialisées avec un code applicatif
ParnaudeauPhilippeÉtude comparative de 3 architectures spécialisées avec un code applicatif.
-
MesoNET : Structuration nationale des mésocentres de Calcul et de Données
RenardArnaudMesoNET répond aux besoins régionaux de calcul pour la recherche académiques, la formation et les entreprises en proposant des équipements structurants.
-
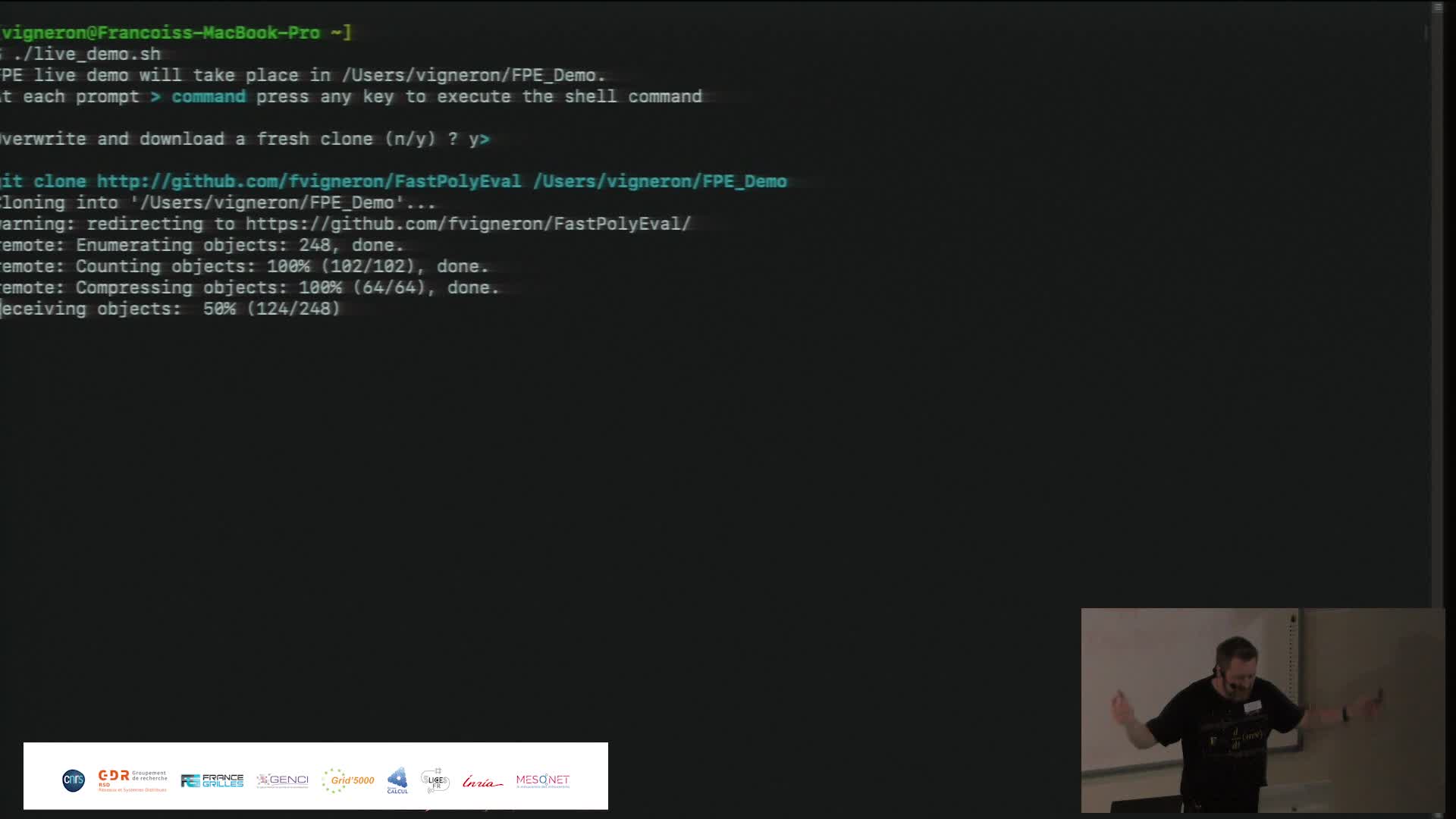
Fast Polynomial Evaluation (présentation + demo)
VigneronFrançoisWe propose a new algorithm for quickly evaluating polynomials. The FPE algorithm pre-conditions a complex polynomial P of degree d in time O(d log d), with a low multiplicative constant independent
-
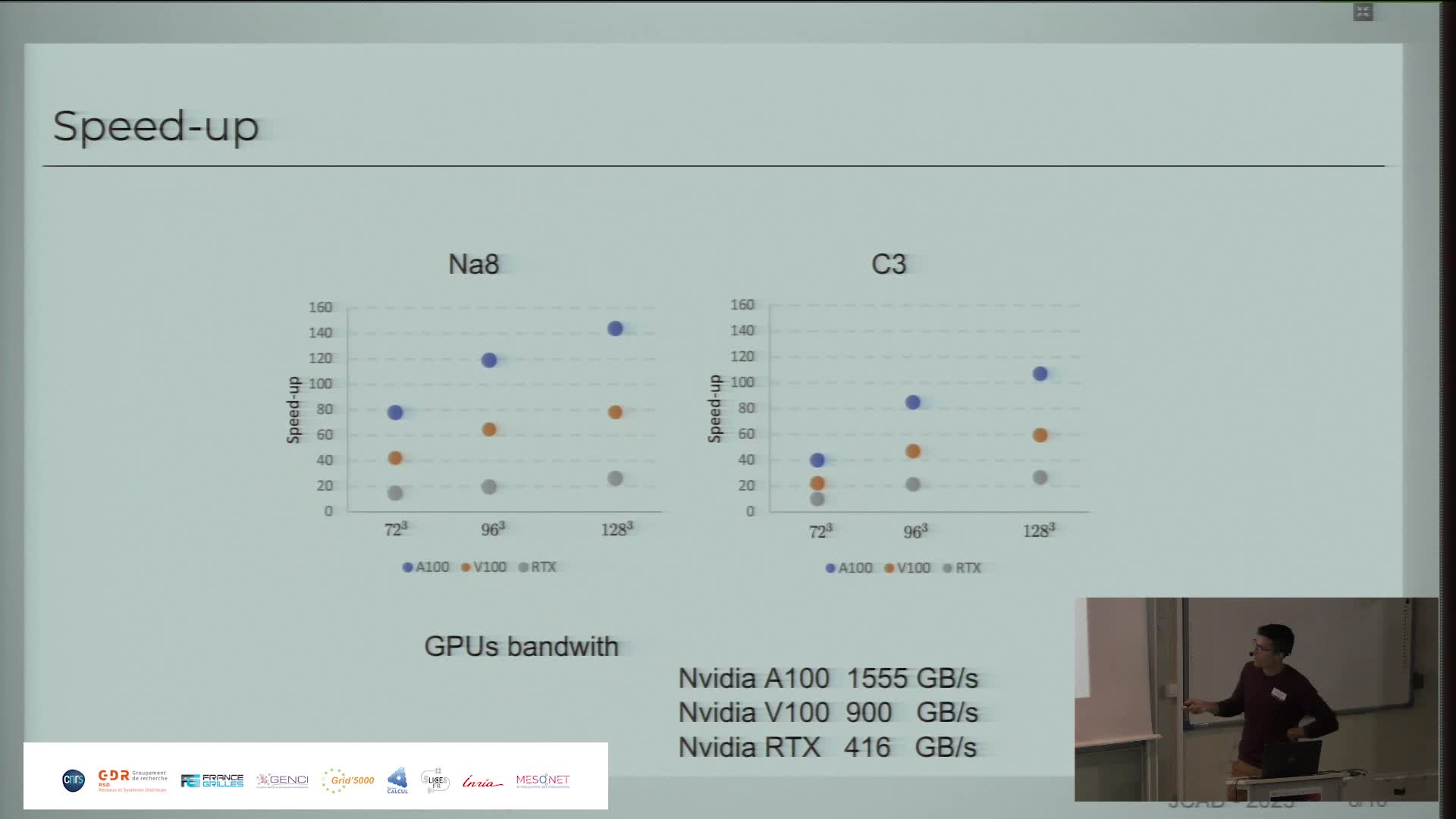
Présentation des performances paralléles du code QDD CUDA Fortran sur différentes Architectures GPU
PaipuriMahendraQDD est l'acronyme de Quantum Dissipative Dynamics, un ensemble de théories développées pour prendre en compte les corrélations dynamiques incohérentes dans les clusters et les molécules.