Notice
Parallel computing with Matlab using MPI4.0 via the Caryam interface
- document 1 document 2 document 3
- niveau 1 niveau 2 niveau 3
Descriptif
Matlab is widely used in scientific community and is an effective framework to develop code prototypes in numerical modeling. Developers can easily test mathematical methods to solve complex problems, and also take benefits of multicores hardware architectures to apply parallelization techniques.
The Parallel Computing Toolbox (PCT)[1] provided by Mathworks is an user-friendly way to implement explicit message passing parallel programing paradigm for distributed memory architectures. But the functionalities of this toolkit can restrict the scope of large memory applications. Indeed, additional licence (Parallel Server [2]) is mandatory to run applications which several nodes or more than 12 cores. Moreover, these toolkits don't provide as much as features than standard APIs like MPI, broadly used in compiled programming langages in the HPC field, specially when domain decomposition methods are involved.
In response to these limitations, ad-hoc MPI wrappers were developed to enable the use of MPI standard features from a Matlab program (MPIMEX [3] or HPCmatlab [4]). They exploit the MEX framework to call C functions from Matlab. But they don't integrate interesting MPI features such as derived datatypes and graph virtual topology. Moreover, they don't use recent Matlab versions which offer built-in Data API, taking advantages of a large part of C++11 features like memory management with copy-on-right semantics.
We developed a new MPI interface (Caryam), based on a recent C/C++ API of Matlab (v2023a). MEX files can be compiled with mpich4.0.2, Intel MPI 2021 and OpenMPI4.1.3 [5]. It makes possible to use a major part of MPI version 4.0 features like point-to-point and collectives communications, derived datatypes, but also cartesian and graph communicators topologies and asynchronous mode which are not accessible in the Mathworks PCT.
Thus, Caryam v1.0 helps to familiarize oneself with the MPI API in an existing Matlab prototype before rewritting it into a compiled langage when it is needed.
We conducted benchmarks on typical algorithms to compare the performances of Caryam and the PCT. Benchmarking set was run on the supercomputer RUCHE held by the regional Mésocentre du Moulon [6]. RUCHE nodes each contains 40 cores (2 x Intel Xeon Gold 6230) with 192GB of memory and are interconnected through a 100 Gbits/s OPA network.
We first perform point-to-point and collective operations on data sizes up to 1GBytes. In all cases, results highliht at least two time faster communications by using the Caryam interface than the PCT. Caryam also provides similar performances to the pure C++ version of benchmarks for data size higher than 1MBytes. We also describe Caryam capabilities to perform asynchronous operations.
Then we carry out scalability studies based on a Parallelized Conjugate Gradient solver (PCG) of a Toeplitz system [7] without preconditionning. We calculate performance scores (speedup, efficiency, Gflops/s) in both strong and weak scaling cases. Based on the resolution of ~6 Gbytes matrix system, Caryam is faster and less memory consuming (-30 %) than the PCT on up to 12 cores. Caryam provides a better scalability than the PCT also by reducing the high overhead caused by parallel region managing.
Besides, The version 1.0 of Caryam enables to reach a 1.046 TFlops peak performance by solving a 1GiB/core size system with the PCG algorithm running on 1000 cores of the RUCHE supercomputer.
We finally show how the use of Caryam v1.0 makes possible the resolution of a 30 million degree of freedom problem on 320 cores by a Matlab prototype on RUCHE. This experiment focus on a mixed domain decomposition method to solve 2D [8,9] and 3D magnetostatic problems.
Thème
Documentation
Dans la même collection
-
Table ronde et discussions : infrastructures de calcul et ateliers de la donnée de recherche Data G…
CastexStéphanieRenardArnaudAlbaretLucieRenonNicolasDufayardJean-FrançoisPARTIE 4 : Des interactions croisées, liens entre le calcul et les données.
-
Table ronde et discussions : infrastructures de calcul et ateliers de la donnée de recherche Data G…
CastexStéphanieRenardArnaudAlbaretLucieRenonNicolasDufayardJean-FrançoisPARTIE 1 : Introduction et présentation des intervenants
-
Table ronde et discussions : infrastructures de calcul et ateliers de la donnée de recherche Data G…
CastexStéphanieRenardArnaudAlbaretLucieRenonNicolasDufayardJean-FrançoisPARTIE 6 : L'accompagnement autour de la gestion des données
-
Table ronde et discussions : infrastructures de calcul et ateliers de la donnée de recherche Data G…
CastexStéphanieRenardArnaudAlbaretLucieRenonNicolasDufayardJean-FrançoisPARTIE 3 : les liens entre les structures
-
Table ronde et discussions : infrastructures de calcul et ateliers de la donnée de recherche Data G…
CastexStéphanieRenardArnaudAlbaretLucieRenonNicolasDufayardJean-FrançoisPARTIE 5 : Des interactions croisées, à propos des compétences
-
Table ronde et discussions : infrastructures de calcul et ateliers de la donnée de recherche Data G…
CastexStéphanieRenardArnaudAlbaretLucieRenonNicolasDufayardJean-FrançoisPARTIE 2 : Les ateliers de la données
-
Table ronde et discussions : infrastructures de calcul et ateliers de la donnée de recherche Data G…
CastexStéphanieRenardArnaudAlbaretLucieRenonNicolasDufayardJean-FrançoisPARTIE 7 : Conclusion
-
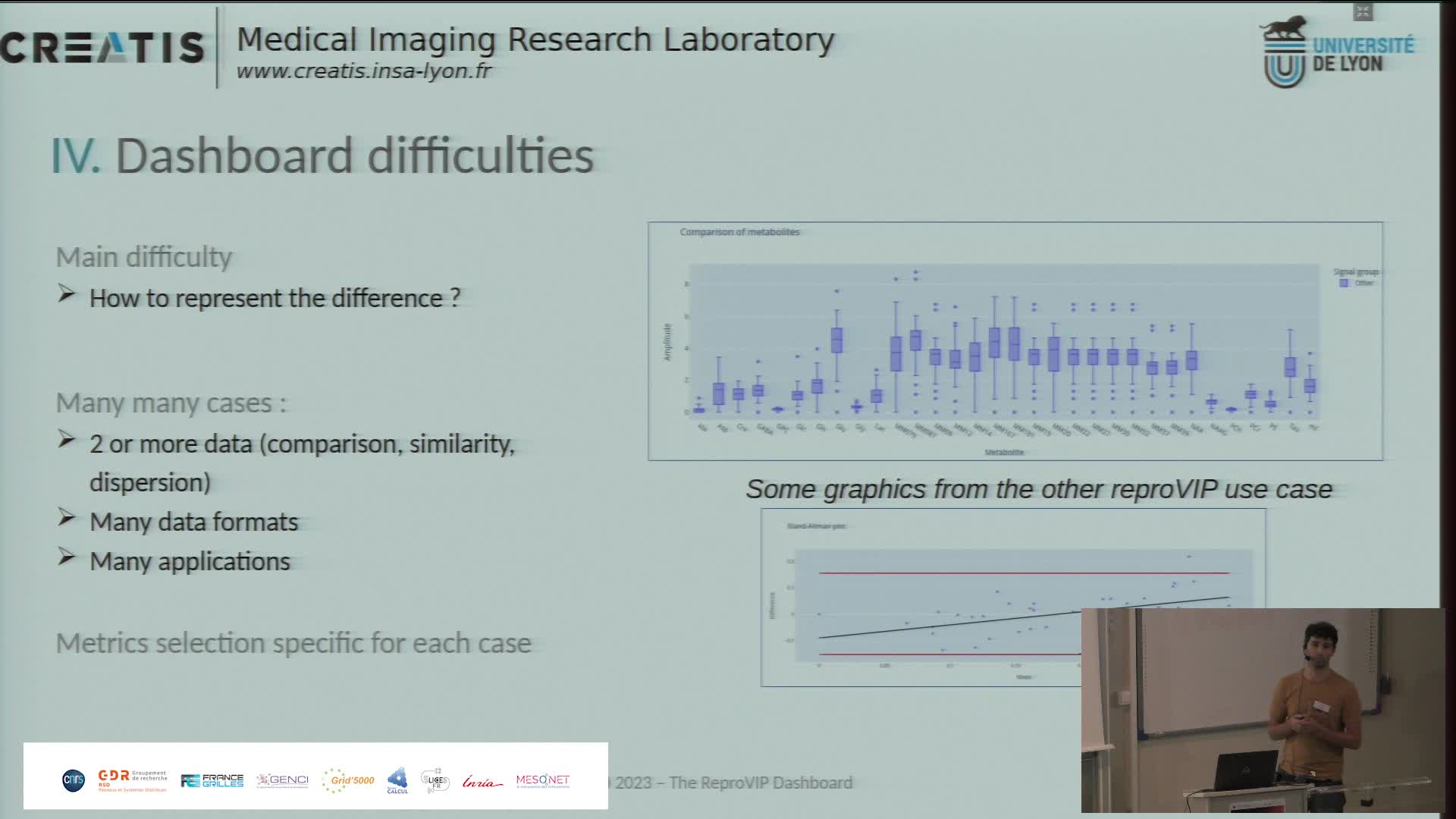
Présentation du dashboard ReproVIP pour visualiser la reproductibilité dans l'imagerie médicale
BonnetAxelLa plateforme d'imagerie virtuelle VIP [1] (https://vip.creatis.insa-lyon.fr) est un portail web de simulation et d'analyse d'images médicales. Elle existe depuis plus de 10 ans et a évolué pour
-
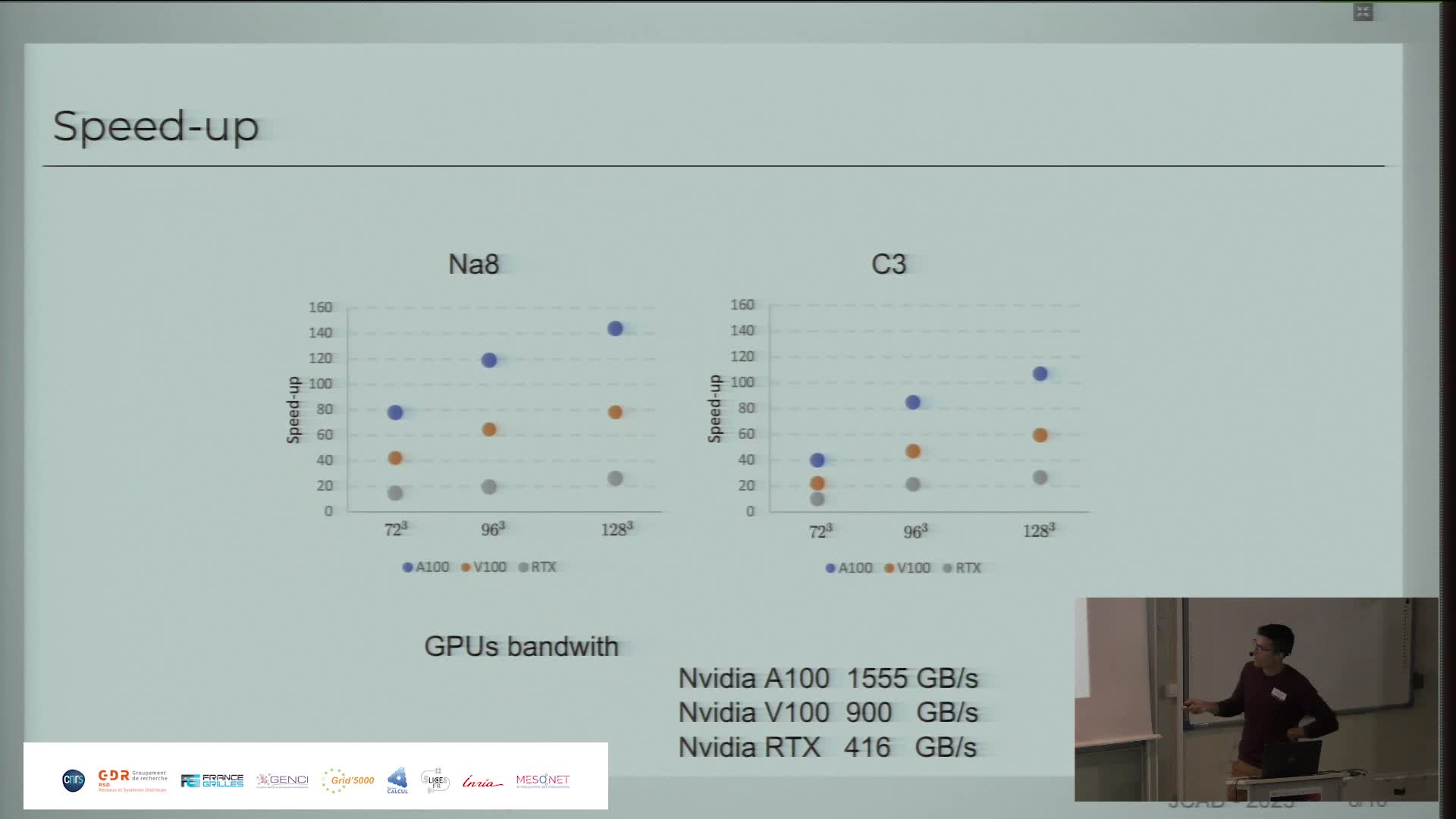
Présentation des performances paralléles du code QDD CUDA Fortran sur différentes Architectures GPU
PaipuriMahendraQDD est l'acronyme de Quantum Dissipative Dynamics, un ensemble de théories développées pour prendre en compte les corrélations dynamiques incohérentes dans les clusters et les molécules.
-
Parallélisation par l'intermédiaire d'une fenêtre à mémoire partagée (MPI 3.0) : application à un c…
ElyakimePierreJADIM est un code de calcul de mécanique des fluides développé en Fortran 90 à l'Institut de Mécanique des Fluides de Toulouse (IMFT).
-
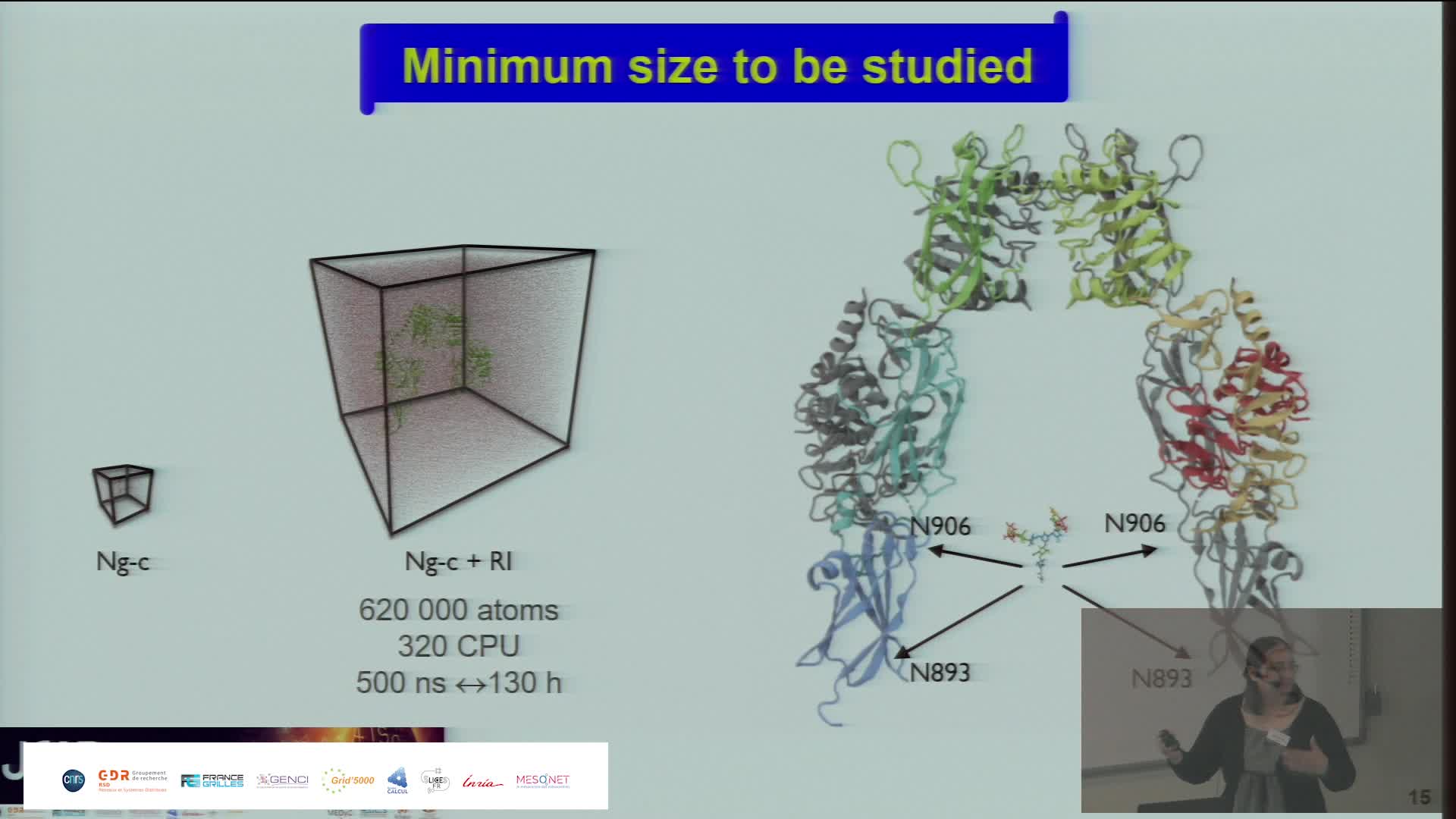
Simulating the Extra Cellular Matrix - Calculations and data from atom to animal
BaudStéphanieThe extracellular matrix (ECM) is a three-dimensional network of macromolecules that is the architectural support for cells and allows tissue cohesion. This dynamic structure regulates many biological
-
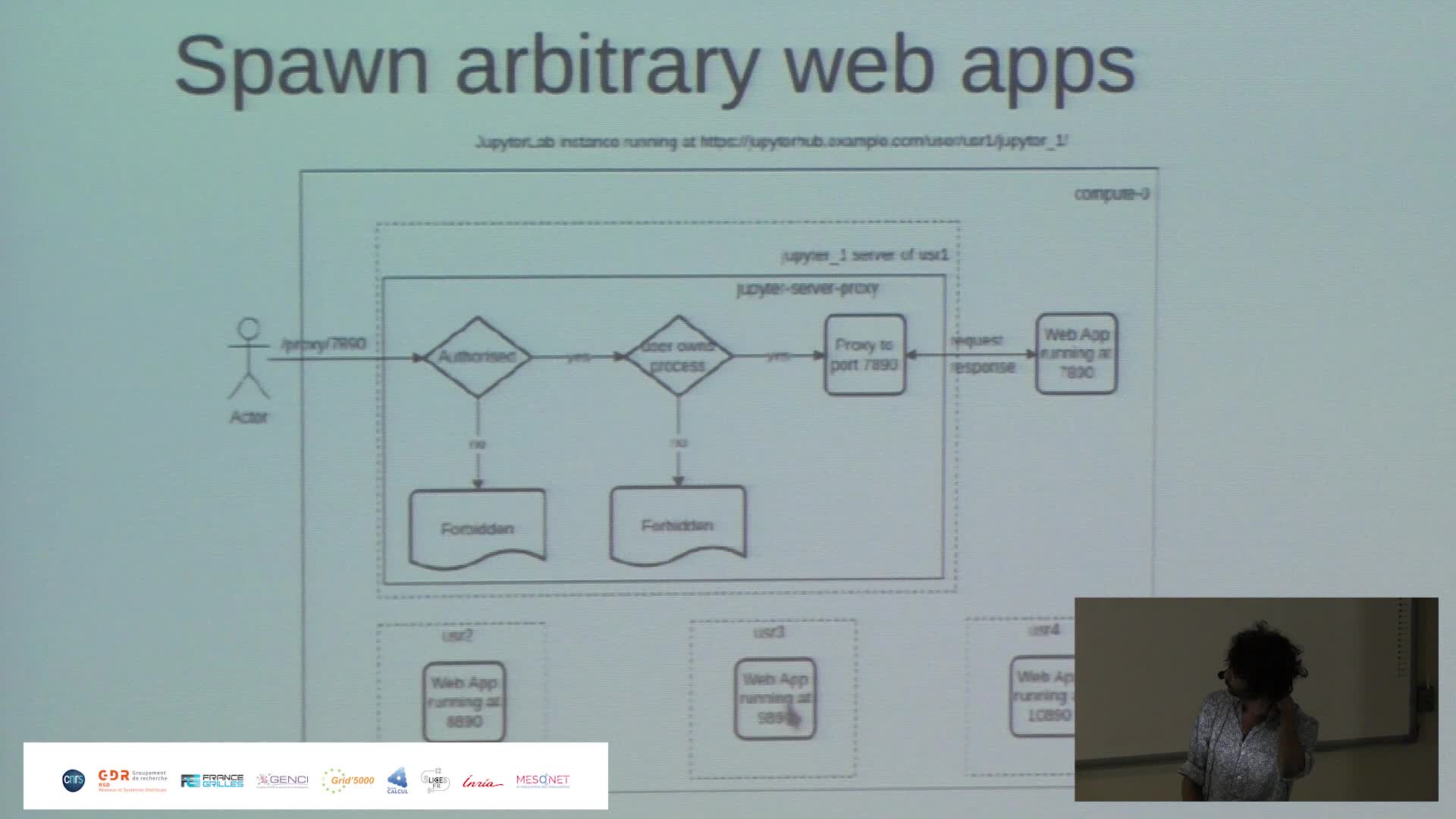
Harnessing the power of Jupyter{Hub,Lab} to make Jean Zay HPC resources more accessible
PaipuriMahendraThis talk revolves around the deployment of JupyterHub on Jean Zay HPC platform and how it is done to meet the demands of RSSI (ZRR constraints) and also to provide a seamless experience to the end