Notice
Multi-hachage
- document 1 document 2 document 3
- niveau 1 niveau 2 niveau 3
Descriptif
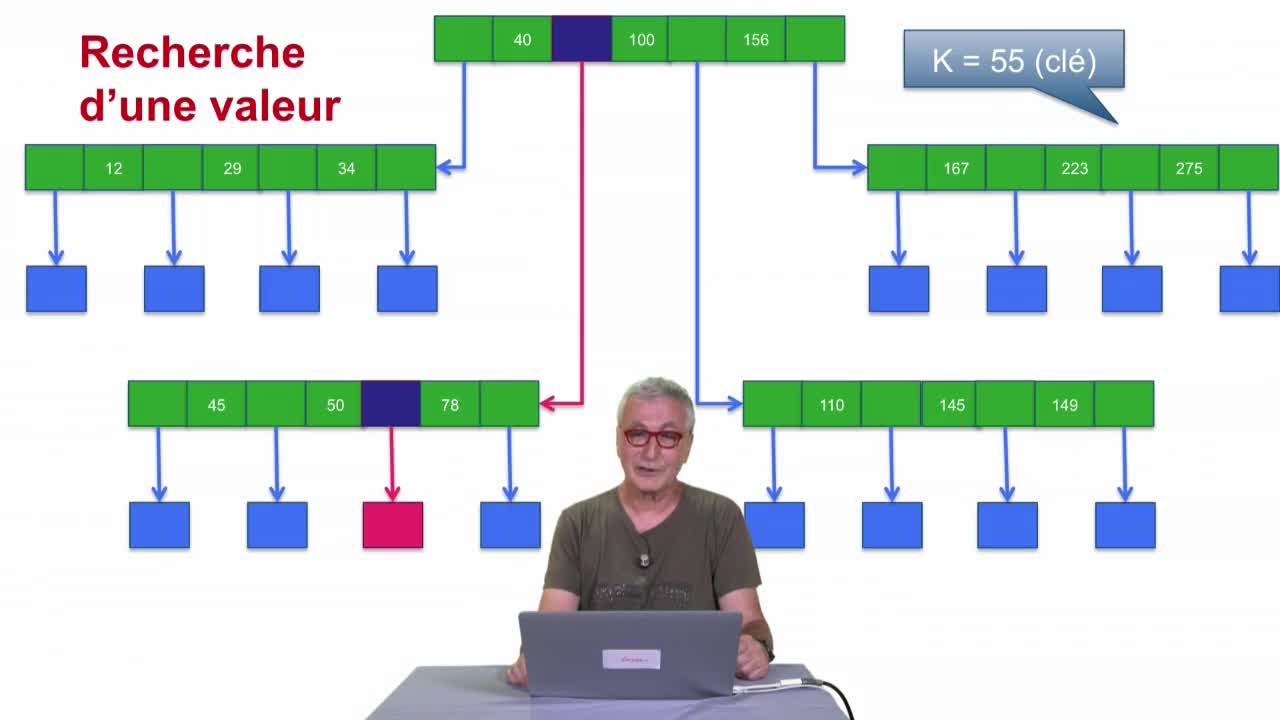
Dans cette dernière séquence de le deuxième partie, nous allons parler du multi-hachage.
Intervention / Responsable scientifique



Thème
Documentation
Complément
Moteur de recherche et recherche plein texte
Quand on parle de requête dans un contexte de base de données, la référence est SQL. Une requête dans ce langage exprime des conditions sur les nuplets à sélectionner, sous la forme d’égalité entre des attributs et des valeurs simples comme des chaines de caractères ou des numériques. Cette recherche est de nature booléenne : un nuplet est ou n’est pas dans le résultat (il satisfait ou non les critères), il n’y a pas d’alternative.
Que peut SQL quand les données à traiter ne sont plus des valeurs simples mais des documents textuels, écrits dans une langue particulière, de taille très variable et dont le contenu n’obéit en principe à aucune règle précise ? Que peut-on faire dans le cadre du Web qui contient des milliards de tels documents ?
Il existe depuis très longtemps un opérateur LIKE qui permet de rechercher des documents contenant une ou plusieurs sous-chaînes. Supposons que l’on veuille sélectionner les nuplets dont le champ ‘contenu’ (que l’on suppose de type TEXT) contient les sous-chaînes « MOOC » et « bases de données ». On pourrait essayer d’exprimer cela en SQL :
select * from docs where contenu like(‘%MOOC%base de données%’)Cette requête est très insatisfaisante pour satisfaire ce besoin. Voyons les points qui fâchent :
- L’opérateur LIKE va trouver les documents contenant ‘MOOC’ avant ‘base de données’, et pas l’inverse. Il faudrait faire une seconde requête (ou utiliser une disjonction).
- Les sous-chaînes sont recherchées littéralement, au caractère près. Un document qui contient ‘Mooc’ ou ‘mooc’, ou contient deux espaces ou un retour à la ligne dans l’expression ‘base de données’, ne sera pas sélectionné.
- Pour la même raison, SQL ne prendra pas en compte les variantes telles les pluriels (‘bases de données’), les conjugaisons de verbe, les acronymes (‘BD’), les synonymes (‘cours en ligne’), le multilinguisme (‘Flot’), etc.
La plupart des systèmes relationnels proposent une extension consistant à exprimer des critères sous forme d’expressions régulières, ce qui ne résout que très partiellement les problèmes ci-dessus. De plus, il faut mentionner une limitation supplémentaire qui les rend vraiment impropres à une recherche « plein texte ». Dans la mesure où on effectue une recherche en fonction d’un besoin exprimé informellement, un processus de nature booléenne qui classe les candidats en deux catégories (sélectionné ou pas) n’est plus satisfaisant ; il est plus naturel d’essayer d’estimer dans quelle mesure un document satisfait le besoin, et de classer les résultats en fonction de cette estimation.
Les moteurs de recherche (des systèmes de recherche plein texte), notamment du Web, tiennent compte de ces spécificités. Ils ont connu un développement considérable depuis 20 ans et la nécessité d’effectuer une recherche rapide et pertinente dans d’énormes masses de documents textuels. Mais même si le web est l’exemple qui vient immédiatement à l’esprit, les moteurs de recherche sont partout : sur votre ordinateur personnel par exemple (Spotlight sous Mac) ou sur votre mobile, dans votre gestionnaire de courrier électronique, etc. Tout le monde a pris l’habitude, dans tous ces contextes, d’utiliser le confort d’une recherche par quelques mots-clés qui ramène une liste classée des documents, ou plus généralement des objets (contacts, rendez-vous, fichiers, articles de blog, etc.), les plus pertinents. On cherche d’instinct la petite loupe, on entre quelques mots dans la fenêtre, et on trouve souvent ce que l’on cherche. Pas de syntaxe compliquée, pas d’hypothèse sur la forme ou l’emplacement des données. Simple et efficace !
Comment ça marche ? On va distinguer deux grandes étapes, la sélection des résultats et leur classement.
La sélection des résultats
Pour faire simple, voici les principales étapes :
Chaque document est soumis à une chaine de transformations :
- découpage du document en mots qu’on appellera des « termes»,
- normalisation des termes, par exemple en les passant en minuscules,
- suppression des suffixes pour se ramener à la racine (« stemming »)
- élimination de mots « vides » (tous les « et », « ou », « le » et autres termes très courants qui ne sont pas représentatifs du contenu sémantique du texte).
Le but de ces transformations lexicales est d’aboutir à un vocabulaire de termes. On va convertir le document en un ensemble de ces termes, et faire de même pour la requête (vous avez bien lu, c’est un ensemble : l’ordre entre les mots est ignoré). On peut aussi utiliser ces transformations pour prendre en compte les synonymes, assimiler LA à Los Angeles, U.S.A. à USA, etc.
On a transformé notre collection de documents en une collection d’ensembles de termes. On va « inverser » cette structure pour obtenir un index, qui associe à chaque terme l’ensemble des documents qui contiennent ce terme. Cette structure est bien plus appropriée à une recherche efficace. Dans l’esprit, cela ressemble beaucoup à l’index d’un livre ou l’index de la bibliothèque du coin de la rue. Pour ce qui est de l’implantation, on peut utiliser une table de hachage, ou une structure plus spécifique pour indexer des chaines de caractères comme le tri (appelé parfois arbre préfixe).
Le diable est dans les détails ! La démarche ci-dessus est bien établie, et permet facilement de construire un mauvais moteur de recherche. Mais pour construire un système à la fois précis et pertinent, il faut prendre tout un ensemble de décisions délicates : que faire des acronymes (USA et usa ont deux sens très différents en français), doit-on ou non éliminer les mots vides, que faire si la collection contient des documents en plusieurs langues, comment indexer des formats riches comme le PDF ou HTML ? Des systèmes spécialisés (dont plusieurs, excellents, sont en Open Source) nous aident à mettre au point d’excellentes fonctionnalités de recherche.
Le classement des résultats
Quand des mots clés sont soumis, un processus de recherche assez complexe va permettre non seulement de sélectionner les documents résultats en accédant aux index mais aussi de classer ces résultats. Pour bien sentir l’importance que peut avoir ce classement, considérons un exemple. En écrivant cet article, nous avons posé au moteur de recherche Google, la requête « Rodin Paris ». Le moteur nous a répondu qu’il y avait « Environ 9,240,000 résultats». Un utilisateur se limitera en général à l’inspection des premières pages de résultats, soit quelques dizaines de documents au plus. La page Web du musée Rodin de Paris que nous cherchions est en fait classée première sur la première page ! Coup de chance ? Non.
Pour classer les résultats d’une recherche plein texte, on a utilisé des mesures de similarité entre les termes de la requête et les différents documents. Plusieurs variantes de la fonction de similarité ont été utilisées. On peut juste mentionner deux heuristiques très courantes :
- On privilégie les termes rares : plus un terme de la requête est rare dans la collection de documents, plus sa présence dans un document tend à faire sélectionner ce document.
- On tient compte de la fréquence des termes : un terme de la requête présent plusieurs fois dans un document tend à faire sélectionner ce document.
Cette approche marche relativement bien sur de petites collections comme une collection de milliers ou dizaines de milliers d’articles scientifiques. D’autres mesures sont complémentaires pour le Web comme Pagerank de Google qui utilise le graphe du Web pour calculer la « popularité » d’une page ; une page est d’autant plus populaire que de nombreuses pages populaires la référencent. C’est ce qui a permis de singulariser la page Web du musée Rodin. D’autres pages étaient sûrement plus proches de la requête « Rodin Paris » mais aucune qui soit aussi populaire.
À côté de la similarité avec les termes de la requête ou de la popularité mentionnée, un moteur de recherche peut utiliser de nombreux autres critères. Il peut choisir de bloquer certains contenus comme Qwant Junior destiné au jeune public. Il peut aussi personnaliser les réponses en tenant compte de ce qu’il sait de l’utilisateur. Il peut enfin privilégier les pages de ses clients ou de ses partenaires. Ce dernier point — et le secret autour de cette fonction de classement — ouvre la porte à toutes les controverses.
http://nlp.stanford.edu/IR-book/ (en anglais)http://webdam.inria.fr/Jorge/?action=chapters (en anglais)
http://b3d.bdpedia.fr/introri.html (en français)
The Anatomy of a Large-Scale Hypertextual Web Search Engine. Sergey Brin and Lawrence Page, http://ilpubs.stanford.edu:8090/361/ Solr, http://lucene.apache.org/solr/
Elastic Search, https://www.elastic.co/fr/
Dans la même collection
-
Indexation : introduction
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette deuxième partie du cours "Bases de données relationnelles", nous allons considérer des techniques d'indexation. Dans une première séquence, nous allons regarder des techniques plutôt
-
Hachage dynamique
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette séquence, nous allons parler du hachage dynamique.
-
Fichiers indexés
AbiteboulSergeNguyenBenjaminRigauxPhilippeDance cette séquence, nous allons parler de fichiers indexés. C’est une structure de données qui est utilisée essentiellement pour accélérer l’accès à l’information.
-
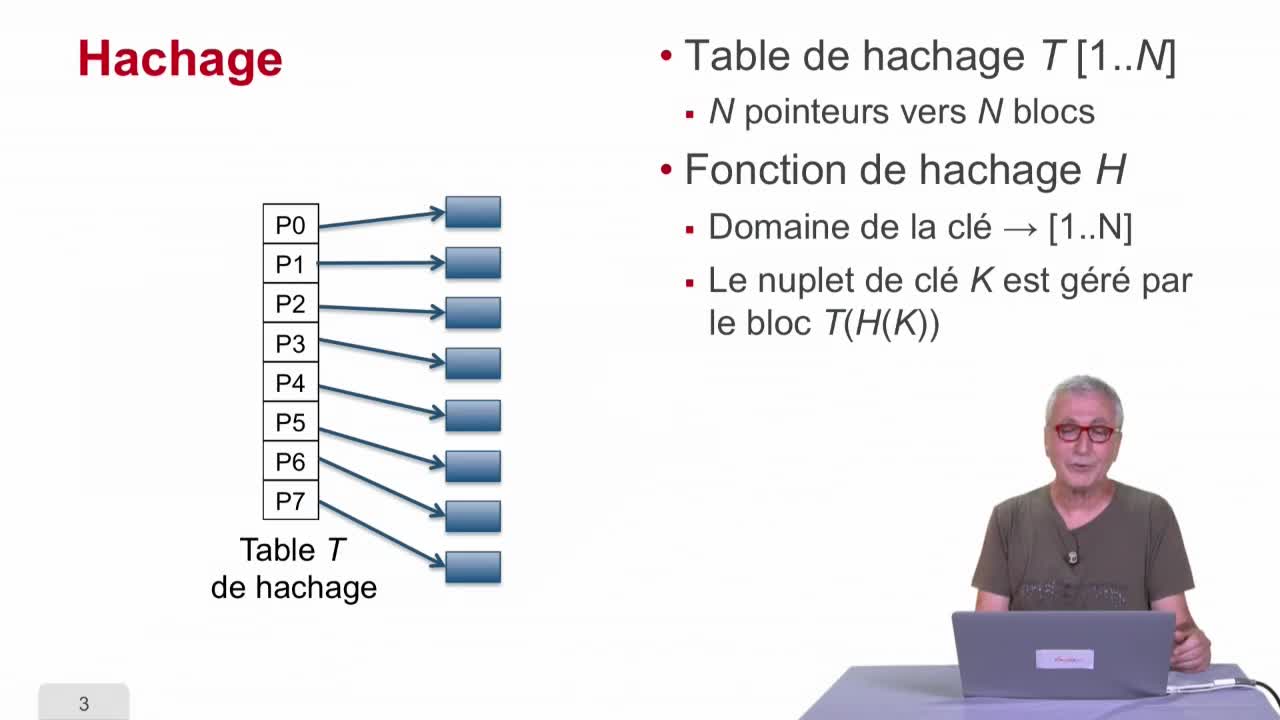
Hachage
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette séquence, nous allons étudier une technique qui s’appelle le hachage, fonction de hachage, qui à mon avis est une des techniques les plus cool de l’informatique.
-
Hiérarchie de mémoire
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette deuxième séquence, nous allons considérer une technique très efficace qui est la hiérarchie de mémoire.
-
Arbre-B
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette séquence, nous allons parler de l’arbre B dont je vous ai déjà parlé la séquence précédente. Le point de départ est très simple : on a coupé le fichier en blocs et pour certains blocs on a


Avec les mêmes intervenants et intervenantes
-
Hiérarchie de mémoire
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette deuxième séquence, nous allons considérer une technique très efficace qui est la hiérarchie de mémoire.
-
Plans d'exécution
AbiteboulSergeNguyenBenjaminRigauxPhilippeNous avons vu dans la séquence précédente, les opérateurs qui sont des composants de base avec lesquels nous allons construire nos programmes d’évaluation de requêtes. Dans cette quatrième séquence,
-
Reprise sur panne : introduction
AbiteboulSergeNguyenBenjaminRigauxPhilippeNous débutons la partie 5 de ce cours qui va être consacré à la reprise sur panne. La reprise sur panne est une fonctionnalité majeure des SGBD, elle est extrêmement apprciable puisqu'elle garantit la
-
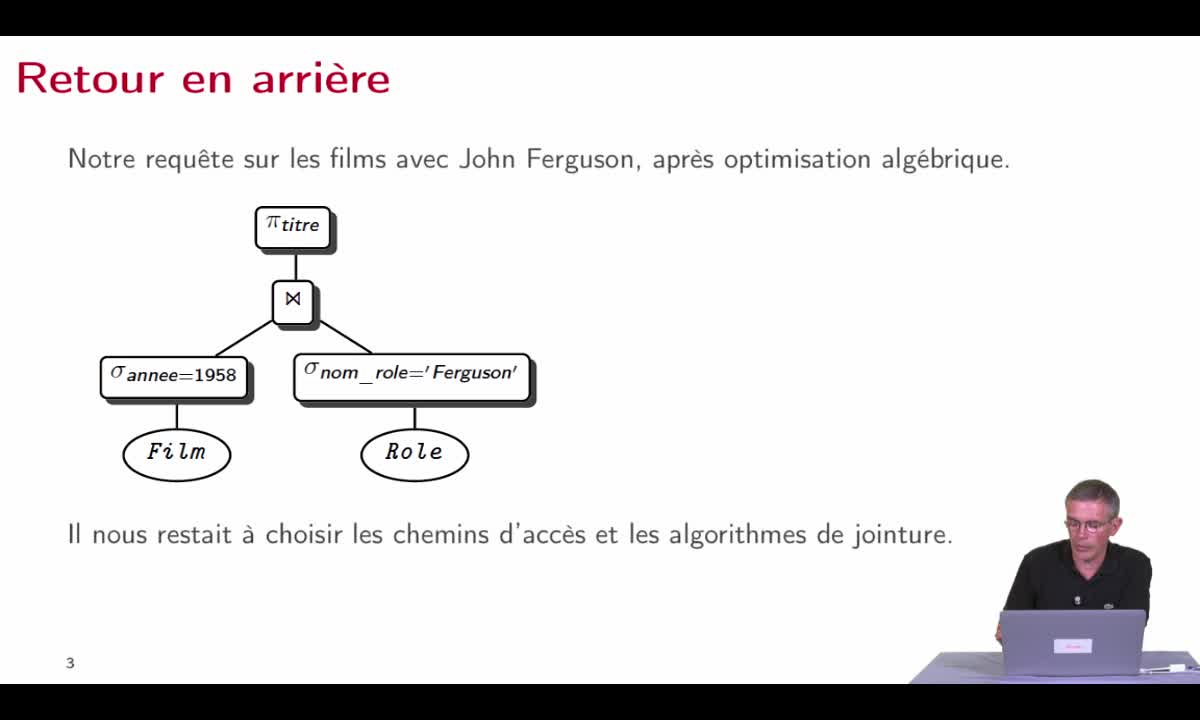
Optimisation de requête
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette séquence, on va parler d'optimisation de requête, on va montrer comment toutes les techniques d'optimisation de requête qui avaient été développées dans le cas centralisé peuvent être
-
Pannes de disque
AbiteboulSergeNguyenBenjaminRigauxPhilippeNous allons conclure cette partie 5 en examinant le cas de panne le plus grave qui est la perte d'un disque.
-
Présentation du cours de bases de données relationnelles
AbiteboulSergeNguyenBenjaminRigauxPhilippeBienvenue dans ce cours sur les bases de données relationnelles. Le but de cet enseignement est extrêmement simple, on vous veut vous faire comprendre les BDR pour que vous puissiez mieux les
-
Hachage
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette séquence, nous allons étudier une technique qui s’appelle le hachage, fonction de hachage, qui à mon avis est une des techniques les plus cool de l’informatique.
-
Optimisation
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette septième séquence, nous allons pouvoir maintenant récapituler à partir de tout ce que nous savons et en faisant un premier retour en arrière pour prendre la problématique telle que nous l
-
Le journal des transactions
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette séquence, nous allons étudier le mécanisme principal qui assure la reprise sur panne qui est le journal de transactions ou le log.
-
Conclusion : cinq tendances
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette dernière séquence du cours, nous allons examiner des tendances des bases de données distribuées.
-
Verrouillage hiérarchique
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette dernière séquence de la première partie, nous allons nous intéresser au verrouillage hiérarchique. C'était une autre manière d'améliorer les performances des transactions dans les bases de
-
Réécriture algébrique
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette deuxième séquence, nous allons étudier la manière dont le système va produire, à partir d’une requête SQL, une expression algébrique donnant la manière d’évaluer cette requête, une première