
Abiteboul, Serge (1953-....)
Directeur de recherches à l'Inria et à l'ENS Paris, membre du collège de l'Arcep (en 2022)
Professeur au Collège de France (2011-2012) du cours "Sciences des données : de la logique du premier ordre à la Toile" dans le cadre de la chaire annuelle "Informatique et sciences numériques"
Serge a été, entre autres, professeur invité des universités de Stanford, Oxford, et professeur au Collège de France. Il est membre de l'Académie des Sciences française et européenne. Il a obtenu le prix Milner et l’ACM SIGMOD Innovation Award. Il a co-fondé la start-up Xyleme en 2000.
Vidéos
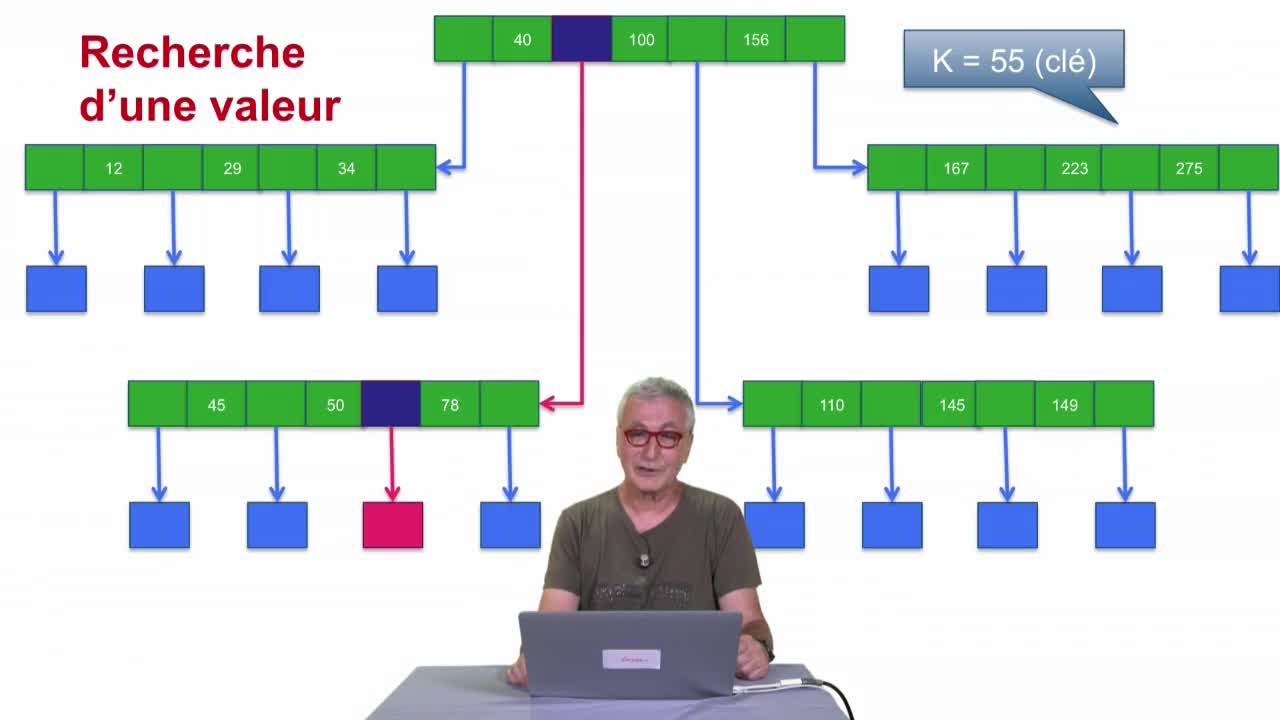
Arbre-B
Dans cette séquence, nous allons parler de l’arbre B dont je vous ai déjà parlé la séquence précédente. Le point de départ est très simple : on a coupé le fichier en blocs et pour certains blocs on a

Tri et hachage
Dans cette cinquième séquence, nous allons commencer à étendre notre catalogue d'opérateurs, en examinant deux opérateurs très importants : le tri et le hachage. En fait dans cette séquence, on va
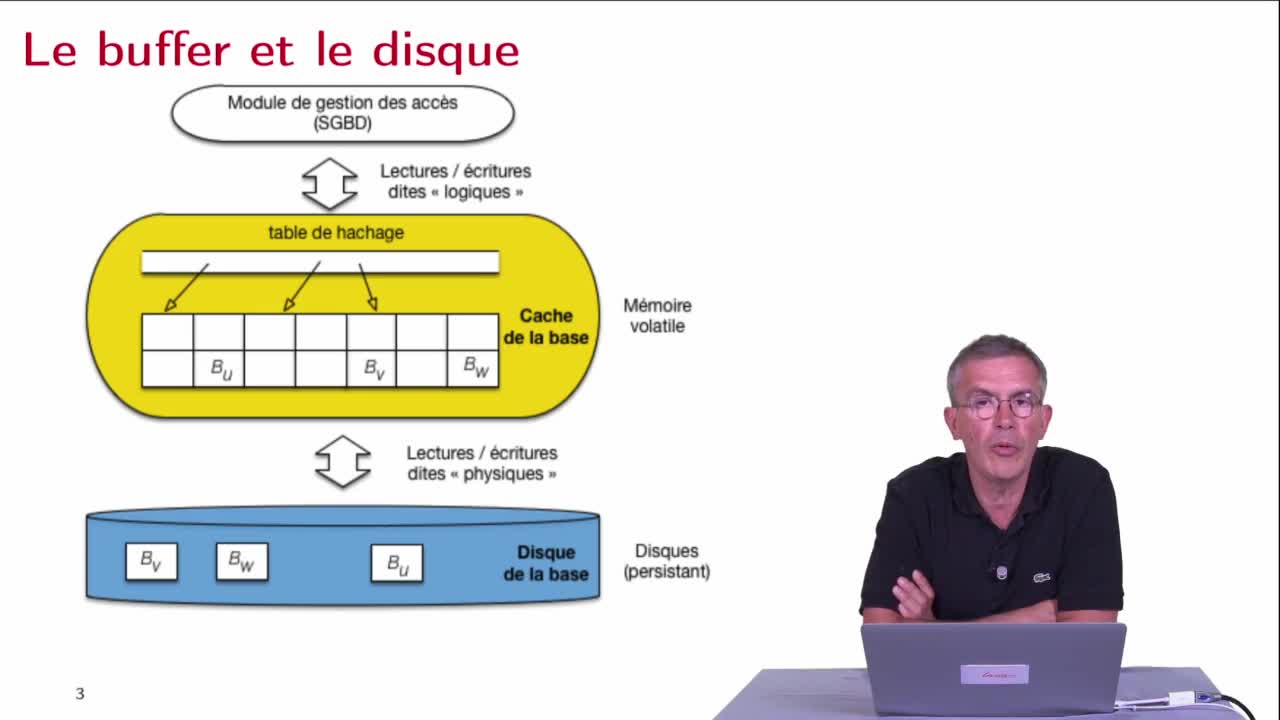
Lectures et écritures, buffer et disque
Dans cette deuxième séquence, pour essayer de bien comprendre ce qu'implique une panne, on va revoir de manière assez détaillée les échanges entre les différents niveaux de mémoire précédemment

Réplication
Dans cette cinquième séquence, nous allons étudier la réplication. L'idée à retenir : la raison essentielle à la réplication c'est la fiabilité.

Degrés d'isolation dans les SGBD
Dans cette sixième séquence, nous allons nous intéresser au degré d'isolation dans les SGBD c'est-à-dire des manières d'accepter des transgressions sur le concept de serialisabilité en échange d'un

Multi-hachage
Dans cette dernière séquence de le deuxième partie, nous allons parler du multi-hachage.

Contrôle d'accès : introduction
Dans cette quatrième partie, nous nous intéressons au contrôle d'accès qui est une problématique de sécurité d'accès à l'information. Nous allons commencer dans cette première séquence par présenter

Algorithmes de reprise sur panne
Avec le journal de transactions que nous avons présenté dans la séquence précédente, nous sommes maintenant en mesure d'avoir un algorithme de reprise sur panne qui est tout à fait robuste. Nous

Les transactions : introduction
Dans cette première partie, nous allons étudier les transactions et la concurrence c'est à dire le fait qu'il y ait plusieurs transactions qui arrivent en même temps. On va commencer par expliquer ce

Hiérarchie de mémoire
Dans cette deuxième séquence, nous allons considérer une technique très efficace qui est la hiérarchie de mémoire.

Opérateurs
Dans cette troisième séquence, nous allons commencer à étudier l’exécution des requêtes en se penchant sur le noyau des outils qu’on utilise qui sont les opérateurs dont les systèmes disposent pour

Modèle de contrôle d'accès obligatoire (MAC)
Dans cette quatrième et dernière séquence sur le contrôle d'accès, nous allons voir le contrôle d'accès obligatoire ou Mandatory access control (MAC) en anglais.