Chapitres
Notice
Extraire l'information
- document 1 document 2 document 3
- niveau 1 niveau 2 niveau 3
Descriptif
Action nationale de formation du CNRS (ANF TDM 2024) sur l'exploration documentaire et l'extraction d’informations. Cette formation est organisée par le CNRS en collaboration avec INRAE.
Sujet de l'interview
L’extraction d’information et l’annotation sémantique avec le logiciel Alvis NLP
Intervenant
Mouhamadou Ba, ingénieur de recherche
Institut national de recherche pour l'agriculture, l'alimentation et l'environnement (INRAE)
Réalisation
Céline Ferlita, UAR ARDIS (CNRS)
Visuel et identité graphique
Marie-Blanche Huet (blan_buro)
Musique
Inspirational Background by AudioCoffee (Pixabay)
Remerciements
Clémence Lesieur et Maxime Ragot, DDOR (CNRS)
Production
Direction des données ouvertes de la recherche (DDOR) du CNRS
Direction pour la science ouverte (DipSO) de INRAE
Appui à la Recherche et Diffusion des Savoirs (ARDIS) du CNRS
© CNRS, INRAE, 2024
Dans la même collection
-
Créer et télécharger son corpus
HuguinMathildeBarreauxSabineInterview Sabine Barreaux et Mathilde Huguin | Créer et télécharger son corpus avec le service ISTEX Search
-
Explorer et analyser son corpus
RevolJustineInterview Valérie Bonvallot et Justine Revol | Explorer et analyser son corpus avec l'outil Lodex et les web services ISTEX
-
Analyser un corpus de textes
HeidenSergeInterview Serge Heiden | Analyser un corpus de textes avec le logiciel de textométrie TXM
-
Cartographier la connaissance
ChavalariasDavidDelanoëAlexandreInterview David Chavalarias et Alexandre Delanoë | Cartographier la connaissance avec le logiciel GarganText
-
Suivre l'évolution de la connaissance
ChavalariasDavidInterview David Chavalarias et Quentin Lobbé | Suivre l'évolution de la connaissance grâce à la cartographie temporelle (phylomémies)
-
-
Robots conversationnels
FerréArnaudInterview Arnaud Ferré | Le prompt engineering avec les robots conversationnels
-
Fouille de textes et IA générative
ChifuAdrian-GabrielInterview Adrian Chifu | La fouille de textes et l'intelligence artificielle générative
-
Constituer son corpus avec Istex
HuguinMathildeInterview de Mathilde Huguin | La constitution d'un corpus documentaire à partir des ressources Istex
-
Web services ISTEX
RevolJustineInterview de Justine Revol | Des web services dédiés à la fouille de textes
-
Profilage des contributeurs sur Wikipédia
VermeirscheJeanneSanjuanEricInterview Jeanne Vermeirsche et Eric Sanjuan | Plateforme RStudio - Profilage des contributeurs sur Wikipédia
-
Lexicométrie IRaMuTeQ
GinguenéStéphélineInterview de Stéphéline Ginguené | Logiciel IRaMuTeQ : l'exploration d’un corpus textuel à l’aide de la lexicométrie












Sur le même thème
-
Keynote – Reproductibilité / science ouverte
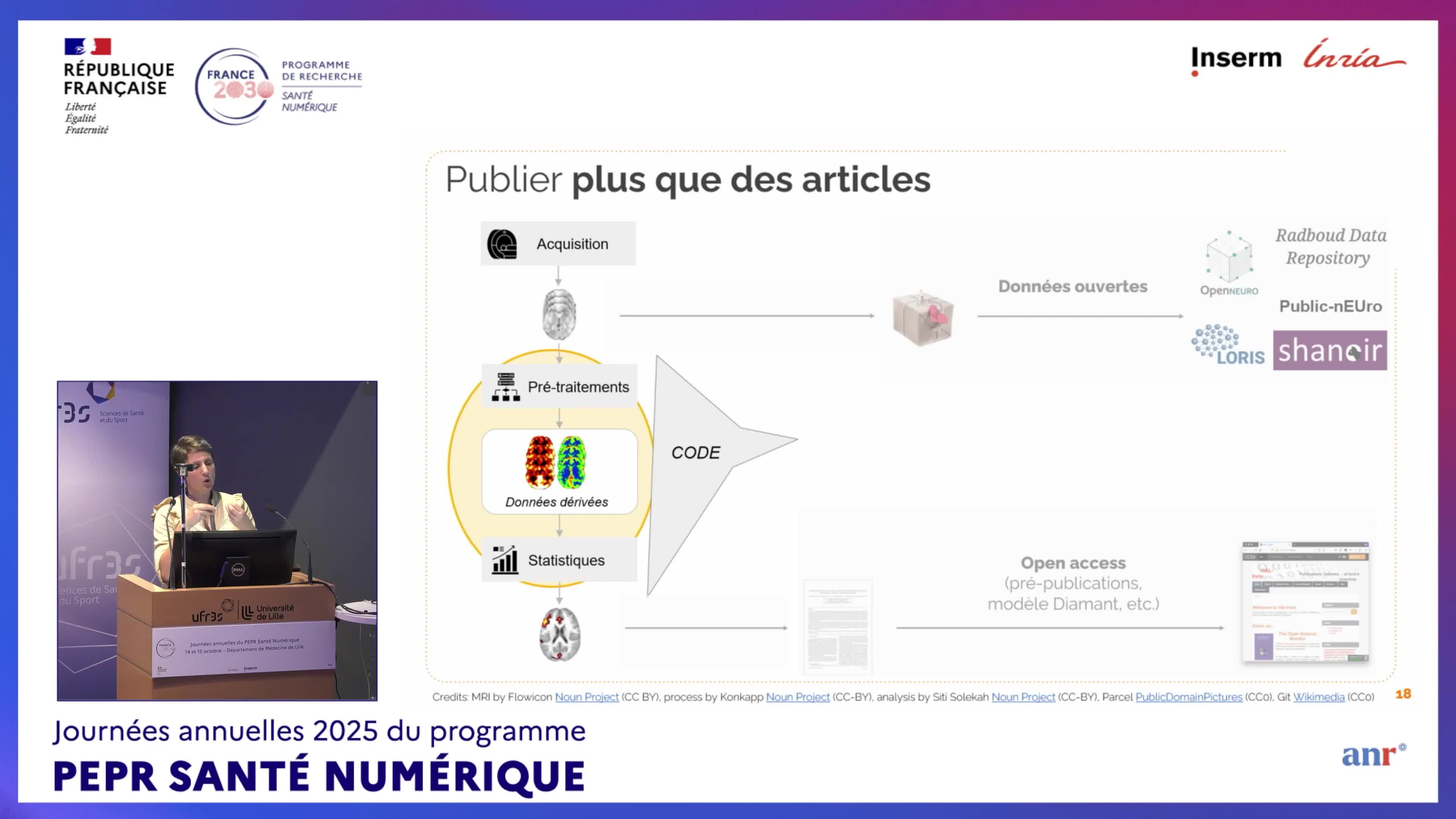
MaumetCamilleKeynote – Reproductibilité / science ouverte
-
Projet CoESciTER
HarauxGeoffreyPrésentation du projet CoESciTER – Corpus Enseignement des Sciences de la Terre.
-
WellBeNet: Analyser et comprendre les modes de vis, un enjeu majeur pour la prévention en santé
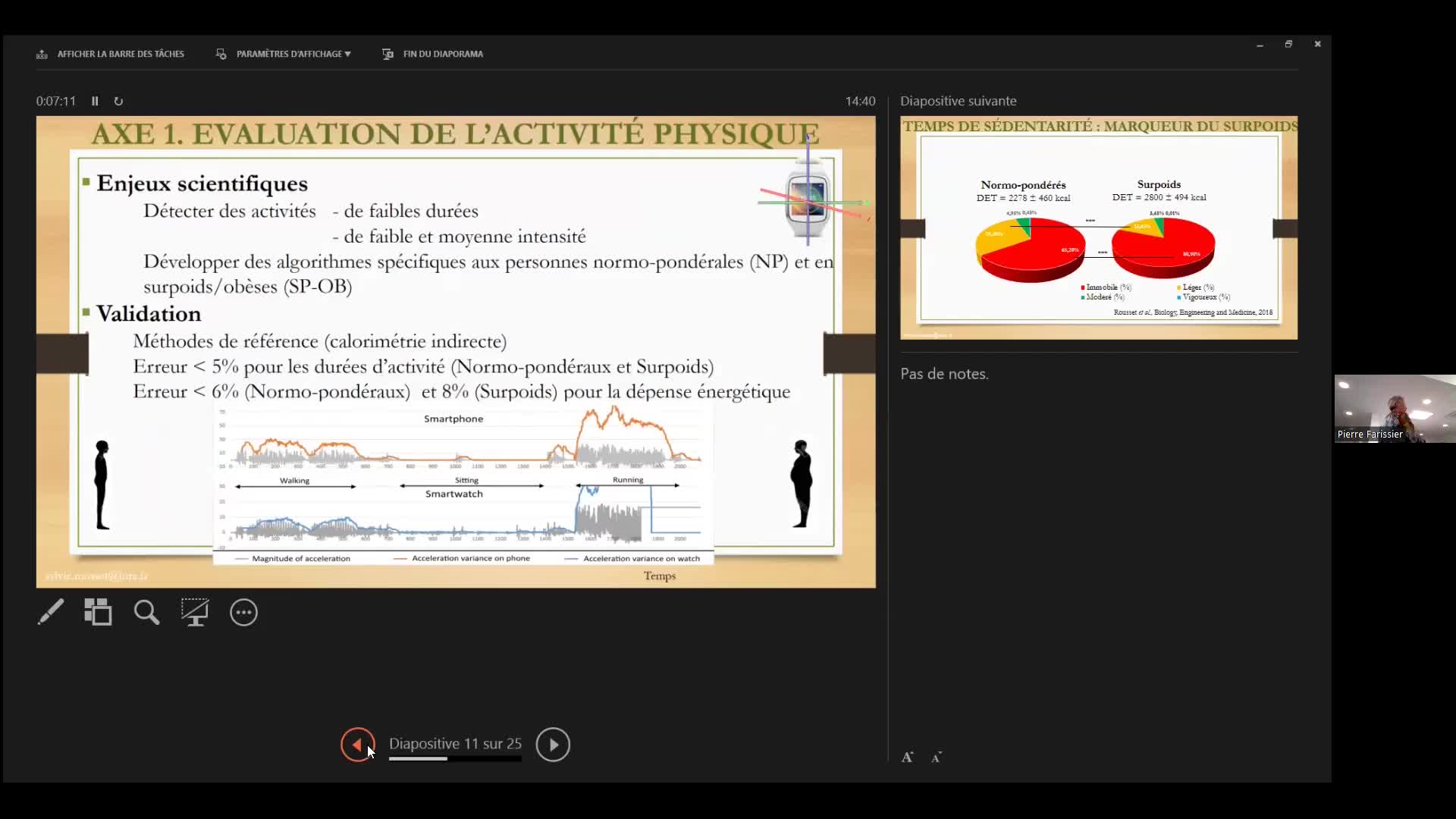
RoussetSylviePrésentation du projet WellBeNet lors du Séminaire Collectes Participatives de Données 2024 Inrae.
-
Regrouper vos publications avec l’idHAL
L'essentiel pour créer votre identifiant idHAL et regrouper vos publications en deux minutes !
-
ForEval: une application mobile pour évaluer les sols forestiers
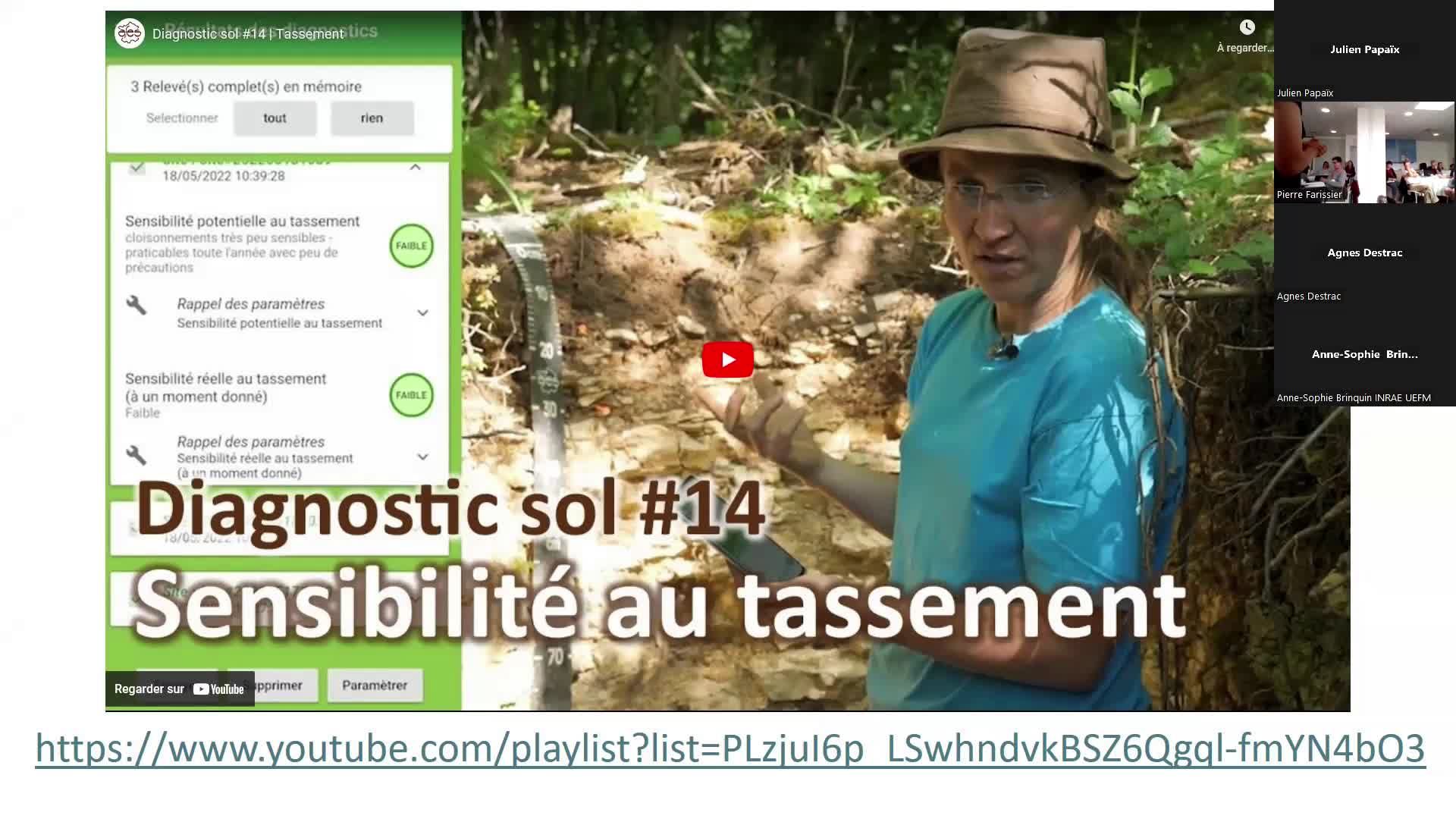
GoutalNoémiePrésentation du projet ForEval lors du Séminaire Collectes Participatives de Données 2024 Inrae.
-
GAELA: une application sur smartphone pour la gestion assistée d’un atelier cunicole
GidenneThierryPrésentation du projet Gaela lors du Séminaire Collectes Participatives de Données 2024 Inrae.
-
Présentation du projet de collecte participative de données Flegme
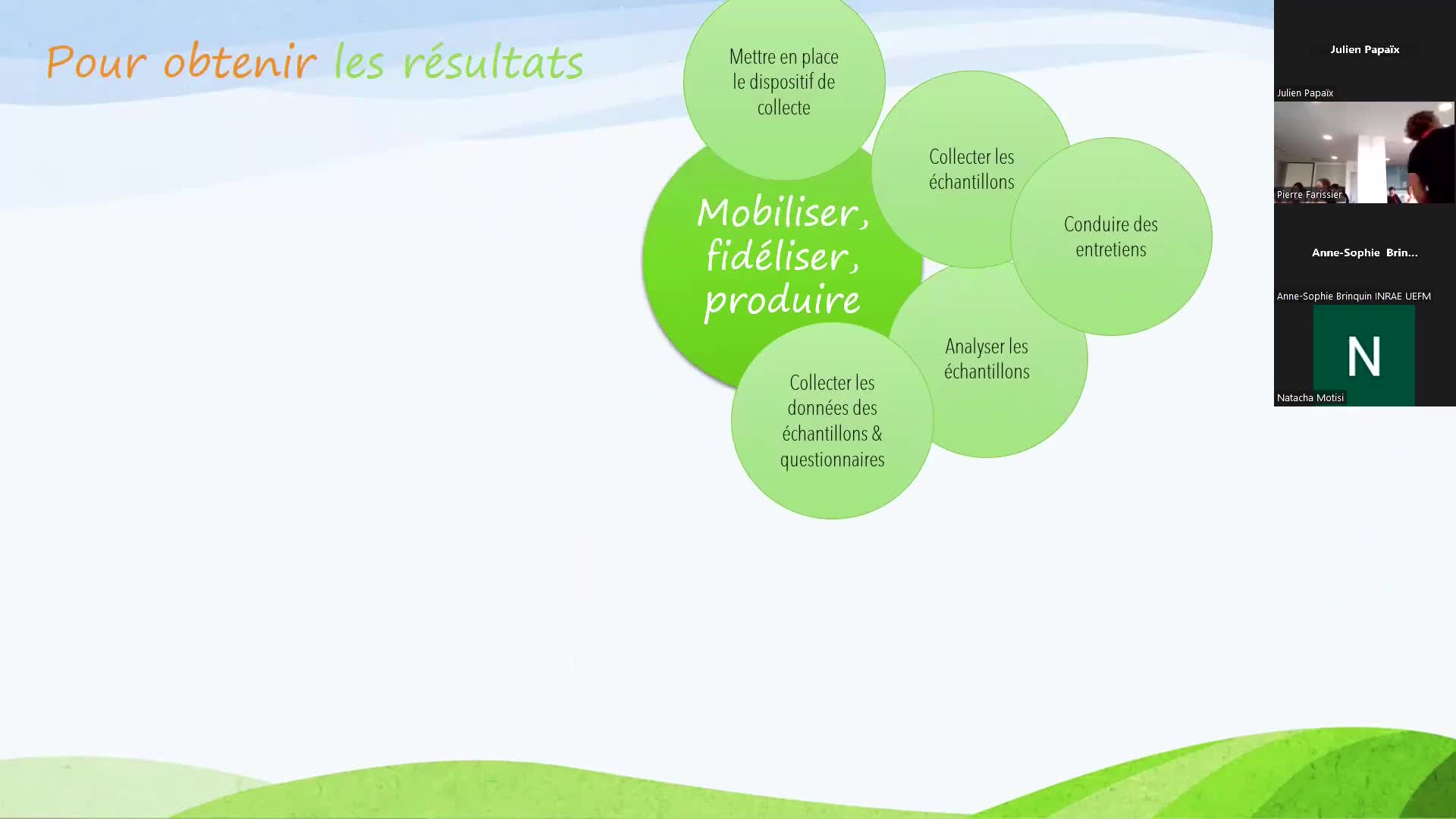
Valence-BertelFlorencePrésentation du projet Flegme lors du Séminaire Collectes Participatives de Données 2024 Inrae.
-
Alimenter votre CRAC depuis HAL
Vous êtes personnel scientifique du CNRS, concerné·e par la campagne CRAC ? Découvrez dans ce tutoriel les grands principes pour que vos dépôts HAL alimentent correctement votre compte-rendu d
-
C@fé Renatis : Retours d’enquête sur les rapports des chercheurs aux identifiants et outils de visi…
BoudryChristopheMesclonAnnaRetours sur les résultats de l'enquête sur l’utilisation et les usages, par les chercheurs et chercheuses, des identifiants numériques chercheurs, notamment Orcid
-
Meet the Networks - UK
RoeschÉtienne B.Présenter le fonctionnement et les objectifs du réseau de recherche reproductible au Royaume Uni...
-
Meet the Networks - Brazil
Gervini Zampieri CentenoEduardaPrésenter le fonctionnement et les objectifs du réseau de reproductibilité brésilien...
-
TAL médical en évolution
GrabarNataliaUn état des lieux de la recherche en Traitement Automatique des Langues (TAL) appliquée à la santé numérique.