Chapitres
Notice
Extraire l'information
- document 1 document 2 document 3
- niveau 1 niveau 2 niveau 3
Descriptif
Action nationale de formation du CNRS (ANF TDM 2024) sur l'exploration documentaire et l'extraction d’informations. Cette formation est organisée par le CNRS en collaboration avec INRAE.
Sujet de l'interview
L’extraction d’information et l’annotation sémantique avec le logiciel Alvis NLP
Intervenant
Mouhamadou Ba, ingénieur de recherche
Institut national de recherche pour l'agriculture, l'alimentation et l'environnement (INRAE)
Réalisation
Céline Ferlita, UAR ARDIS (CNRS)
Visuel et identité graphique
Marie-Blanche Huet (blan_buro)
Musique
Inspirational Background by AudioCoffee (Pixabay)
Remerciements
Clémence Lesieur et Maxime Ragot, DDOR (CNRS)
Production
Direction des données ouvertes de la recherche (DDOR) du CNRS
Direction pour la science ouverte (DipSO) de INRAE
Appui à la Recherche et Diffusion des Savoirs (ARDIS) du CNRS
© CNRS, INRAE, 2024
Dans la même collection
-
Créer et télécharger son corpus
HuguinMathildeBarreauxSabineInterview Sabine Barreaux et Mathilde Huguin | Créer et télécharger son corpus avec le service ISTEX Search
-
Explorer et analyser son corpus
RevolJustineInterview Valérie Bonvallot et Justine Revol | Explorer et analyser son corpus avec l'outil Lodex et les web services ISTEX
-
Analyser un corpus de textes
HeidenSergeInterview Serge Heiden | Analyser un corpus de textes avec le logiciel de textométrie TXM
-
Cartographier la connaissance
ChavalariasDavidDelanoëAlexandreInterview David Chavalarias et Alexandre Delanoë | Cartographier la connaissance avec le logiciel GarganText
-
Suivre l'évolution de la connaissance
ChavalariasDavidInterview David Chavalarias et Quentin Lobbé | Suivre l'évolution de la connaissance grâce à la cartographie temporelle (phylomémies)
-
-
Robots conversationnels
FerréArnaudInterview Arnaud Ferré | Le prompt engineering avec les robots conversationnels
-
Fouille de textes et IA générative
ChifuAdrian-GabrielInterview Adrian Chifu | La fouille de textes et l'intelligence artificielle générative
-
Constituer son corpus avec Istex
HuguinMathildeInterview de Mathilde Huguin | La constitution d'un corpus documentaire à partir des ressources Istex
-
Web services ISTEX
RevolJustineInterview de Justine Revol | Des web services dédiés à la fouille de textes
-
Profilage des contributeurs sur Wikipédia
VermeirscheJeanneSanjuanEricInterview Jeanne Vermeirsche et Eric Sanjuan | Plateforme RStudio - Profilage des contributeurs sur Wikipédia
-
Lexicométrie IRaMuTeQ
GinguenéStéphélineInterview de Stéphéline Ginguené | Logiciel IRaMuTeQ : l'exploration d’un corpus textuel à l’aide de la lexicométrie












Sur le même thème
-
La science ouverte au CNRS
PetitAntoineJournée science ouverte au CNRS 2025 – La science ouverte au CNRS avec Antoine Petit (CNRS)
-
Ouverture de la journée science ouverte au CNRS 2025
SchuhlAlainJournée science ouverte au CNRS 2025 – Discours d'ouverture avec Alain Schuhl (CNRS)
-
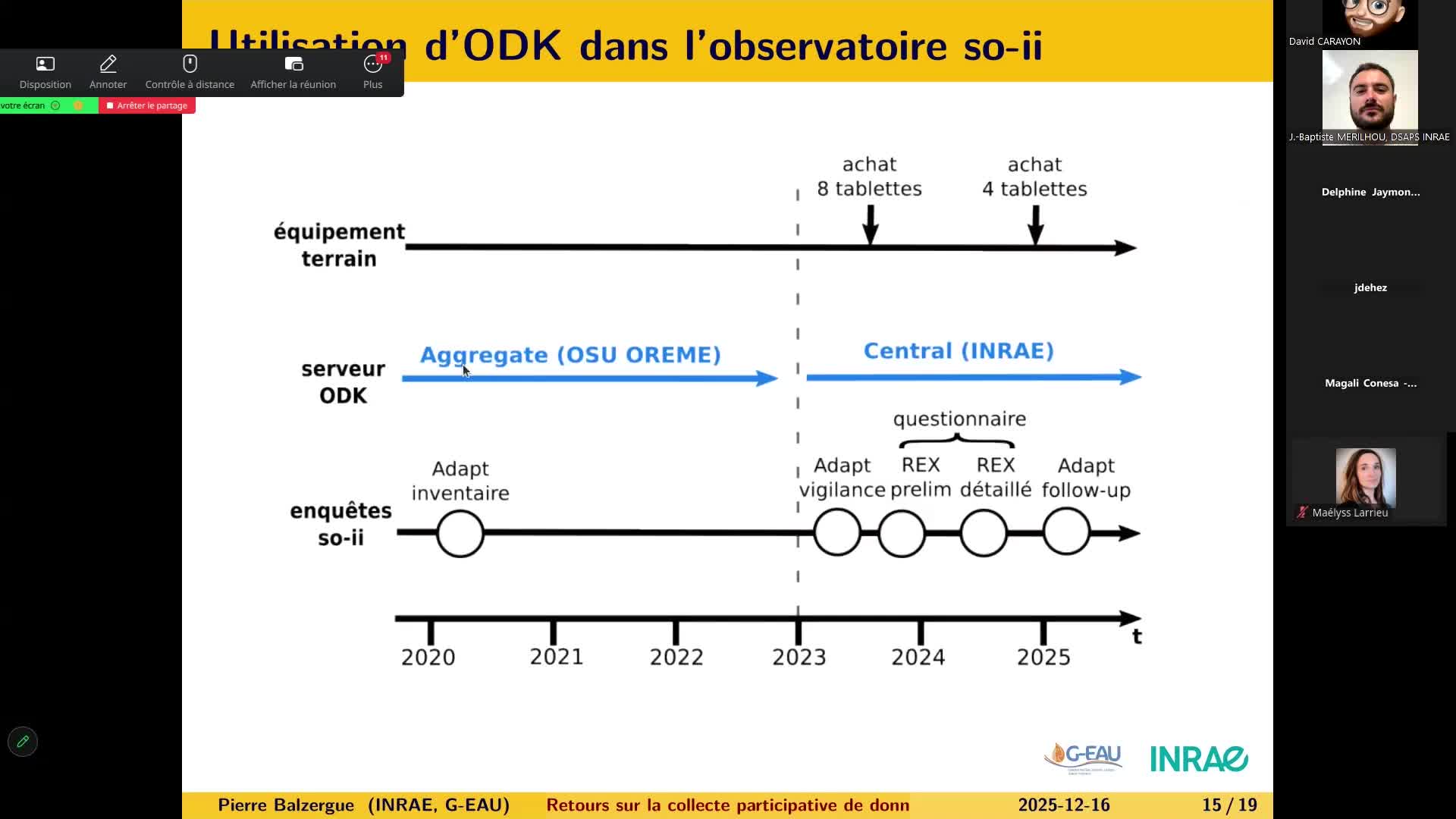
[Webinaire Au SenS large 4] Collecte participative de données avec ODK, un outil mutualisé au sein …
FarissierPierreBalzerguePierreCarayonDavidPierre Balzergue (UMR G-EAU) et David Carayon (UR EABX) illustrent l’utilisation d’ODK (Open Data Kit), outil open source mutualisé au sein d’INRAE, à travers deux projets de collecte participative de
-
[Webinaire Au SenS large 3] Comment (ne pas) faire rater son projet de SRP ?
TurcatiLaureLaure Turcati, coordinatrice de programmes de sciences participatives à Sorbonne Université, partage ici une analyse collective des erreurs rencontrées dans dix projets en France. Elle montre l
-
[Webinaire Au SenS large 2] Médiation scientifique avec Les Savanturiers
RaletMarie-ChristineAnsourAngeVal-LailletDavidAnge Ansour, directrice du programme Savanturiers au sein de l'AFPER (Association française pour l'éducation par la recherche) nous présente le projet "les savanturiers de l'alimentation durable" créé
-
API de recherche HAL
RousselleThéoCaugantJulienVidéo issue du webinaire dédié à l'API recherche de l'archive ouverte HAL, dans le cadre de la programmation 2025-2026 du Club utilisateur CasuHAL.
-
L’interface de validation du dépôt
Vous êtes chargé·e de la validation technique des dépôts pour le portail de votre établissement, découvrez l’interface de vérification et de validation technique d'un dépôt spécifique.
-
L'interface générale de validation technique
Vous êtes chargé·e de la validation technique des dépôts pour le portail de votre établissement, découvrez l’interface générale de vérification et de validation technique des dépôts.
-
La fin annoncée des relecteurs et des relectrices ?
LarivièreVincentJournée science ouverte au CNRS 2025 – La fin annoncée des relecteurs et des relectrices ? avec Vincent Larivière (Université de Montréal)
-
La publication scientifique : fin d'une culture pour une industrie culturelle ?
Boukacem-ZeghmouriChérifaJournée science ouverte au CNRS 2025 – La publication scientifique : fin d'une culture pour une industrie culturelle ? avec Chérifa Boukacem-Zeghmouri (Université Claude Bernard Lyon 1)
-
La fin annoncée des lecteurs et des lectrices ?
TornyDidierJournée science ouverte au CNRS 2025 – La fin annoncée des lecteurs et des lectrices ? avec Didier Torny (CNRS)
-
Multilinguisme et IA au Canada - Promesses et limites de l’IA pour la découvrabilité des contenus s…
MeursMarie-JeanJournée science ouverte au CNRS 2025 – Multilinguisme et IA au Canada - Promesses et limites de l’IA pour la découvrabilité des contenus scientifiques avec Marie-Jean Meurs (Université du Québec à