Vers plus d’intégration de données

Descriptif
Cette dernière partie du cours "Web sémantique et Web de données" propose une conclusion ouverte du cours en abordant plusieurs initiatives pour intégrer toujours plus de données sur le Web.
Nous allons notamment voir comment décrire et tracer les données publiées (VoID, DCAT, Prov-O), comment intégrer données et documents avec la syntaxe RDFa pour RDF et comment exporter des données d’une base relationnelle.
Nous terminerons en insistant sur l’existence d’autres standards que nous ne couvrirons pas. Nous mentionnerons ainsi l’initiative LDP, qui propose une interface d’accès aux données liées (une API REST). Nous parlerons aussi d’une autre approche pour le raisonnement en reposant sur des règles (RIF).
Enfin, nous conclurons la semaine et le MOOC en insistant sur l’intégration des standards que nous avons vus avec les autres standards et sur l’importance de ce travail de compatibilité pour maintenir une architecture unifiée du Web et construire des applications Web les plus complètes possible.
Vidéos
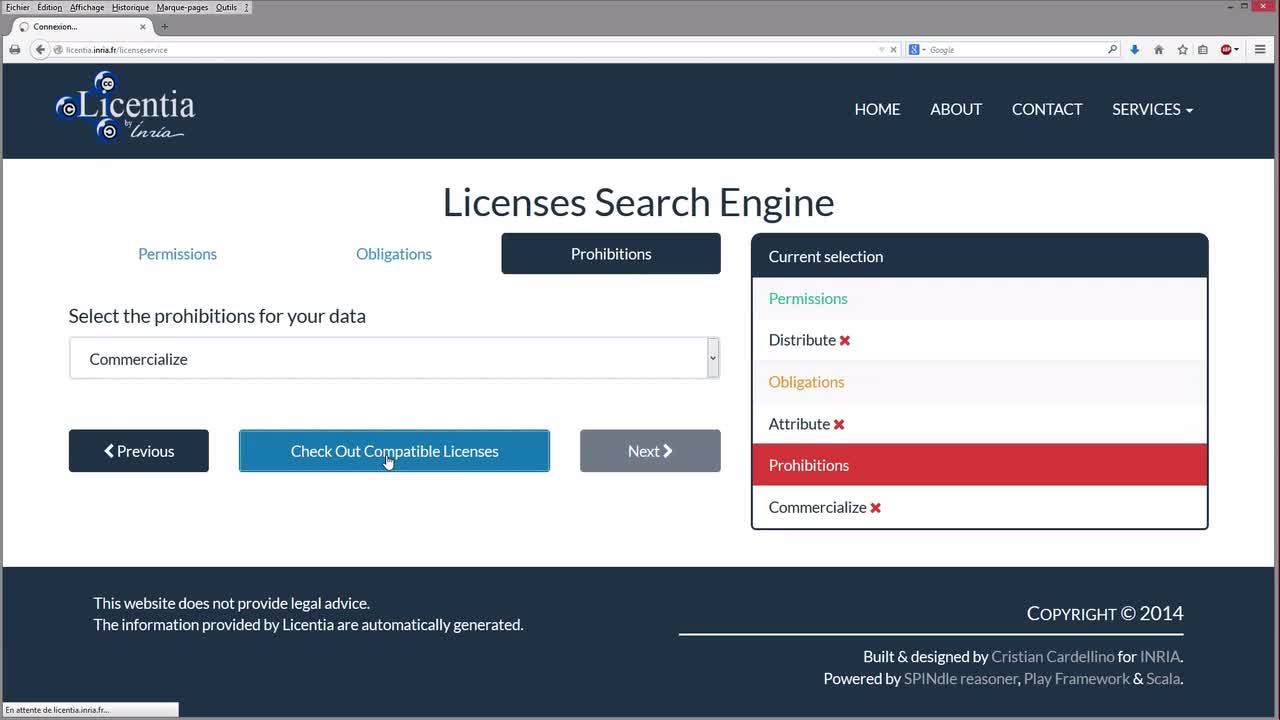
Démos de la partie "Vers plus d’intégration de données"
Dans cette démonstration, nous allons sur le site Licentia de l'INRIA. Ce site a une particularité qui est de vous permettre de choisir et de composer des licences à attacher à vos données.

Conclusion
Il est maintenant temps de conclure ce cours et nous allons commencer par rappeler tout ce qui a été présenté. Nous avons vu d'abord un certain nombre de moyens de lier les données sur le Web et d'y

LDP, RIF, etc.
Dans cette séquence, nous allons parler de deux standards : LDP et RIF. LDP (Linked Data Platform) est un standard de la pile Web sémantique que nous n'aurons pas le temps de détailler dans ce cours.
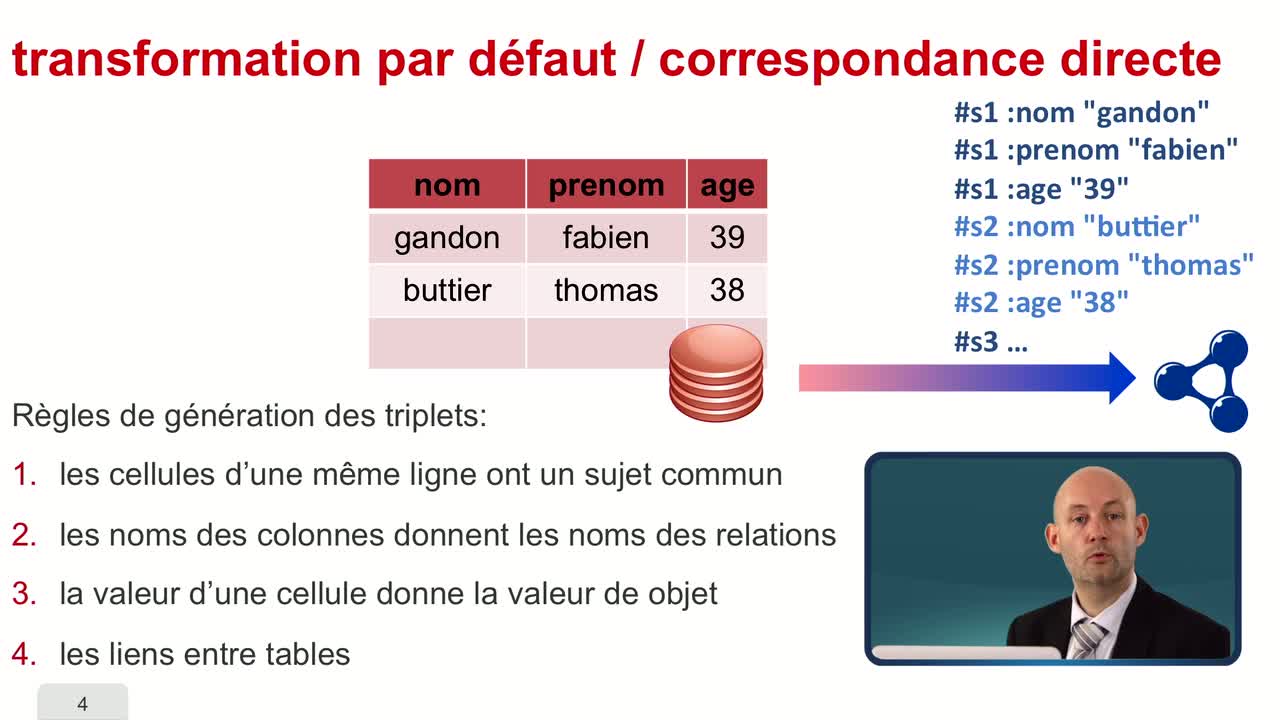
Liens avec les bases de données
Nous venons de voir comment RDFa et GRDDL nous permettent d'extraire et d'injecter des données dans des pages Web ou des pages XML. On va maintenant s'interesser au cas des bases de données.
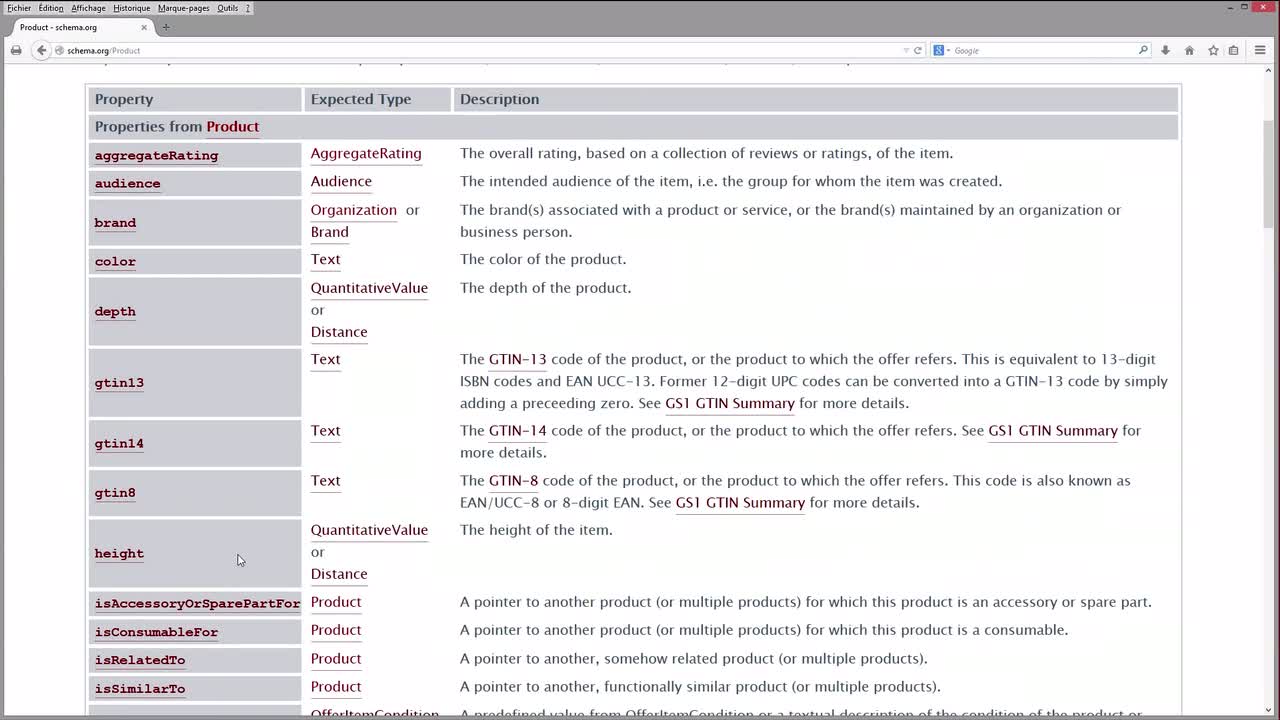
RDF dans les pages HTML (2)
Seconde séquence consacrée à RDF dans les pages HTML.

RDF dans les pages HTML (1)
Avec VoID et DCAT, on a vu comment identifier des sources de données sur le Web. Et avec PROV-O, on a vu comment faire de la traçabilité sur les données. On va maintenant regarder comment intégrer les
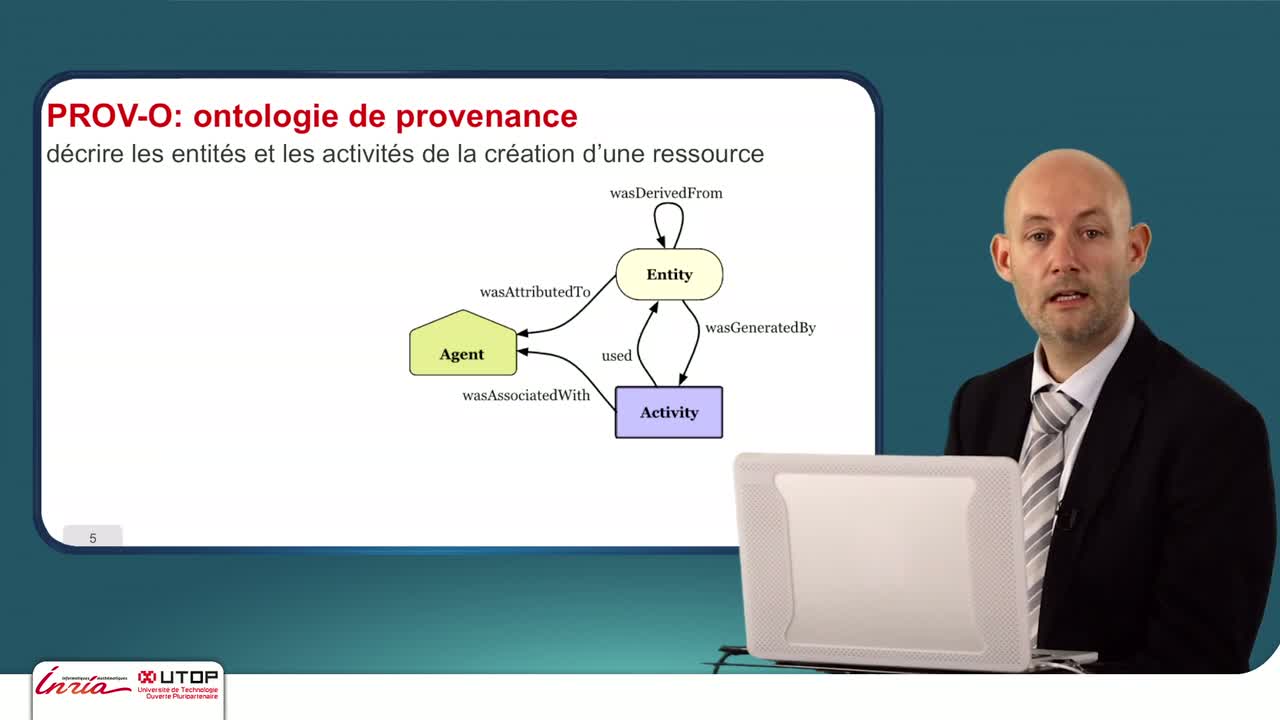
PROVenance et traçabilité
Avec VoID et DCAT, on s'est doté de moyens d'annoter les jeux de données. On va s'interesser maintenant à faire de la traçabilité c'est à dire à savoir par où la donnée est passée, quelles
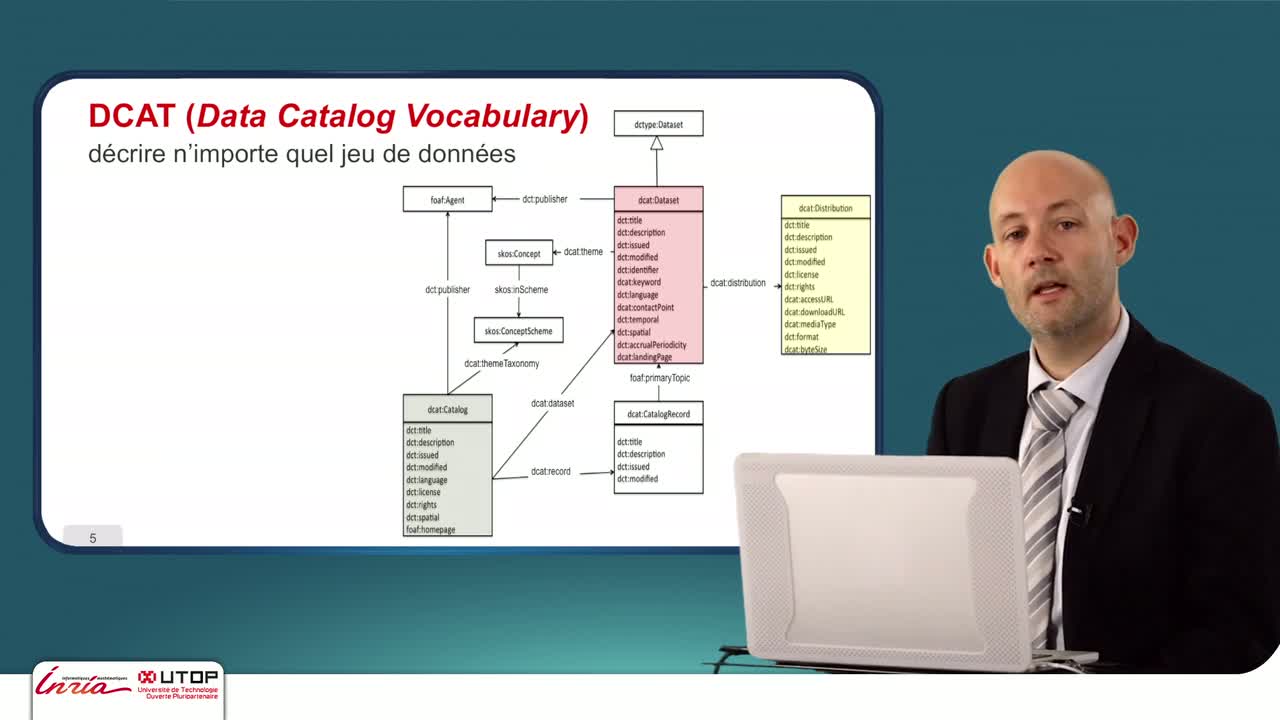
DCAT pour les jeux de données
Nous venons de voir VoID qui permet d'annoter des sources de données RDF sur le Web. D'une certaine façon, DCAT (Data Catalog Vocabulary) que nous allons voir maintenant, va généraliser l'approche de

VoID pour les bases RDF
Dans cette première séquence, nous allons parler de VoID (Vocabulary of Interlinked Datasets) qui va nous permettre d'annoter des sources RDF sur le Web de façon à les retrouver.
Intervenants et intervenantes

Auteur d'une thèse en Informatique à Nice en 1988

Professeure en poste à Université Côte d'Azur (en 2022)
Maîtresse de conférences en poste à l'Université de Nice-Sophia Antipolis (en 2020)
Autrice d'une thèse en sciences appliquées soutenue à Paris 6 en 1997
Professeur des Universités Université de Côte d'Azur
Rapporteure lors d'une thèse soutenue à l'INSA Lyon en 2024
Présidente du jury d'une thèse en Informatique à Université Côte d'Azur en 2024

Chercheur à l'INRIA de Sophia-Antipolis, FR (en 2016). Directeur de recherche à l'INRIA Sophia Antipolis-Méditerranée, Université Côte d'Azur (en 2021)
Titulaire d'un doctorat en sciences (Informatique, Nice, 2002)