Notice
Présentation du cours de bases de données relationnelles
- document 1 document 2 document 3
- niveau 1 niveau 2 niveau 3
Descriptif
Bienvenue dans ce cours sur les bases de données relationnelles. Le but de cet enseignement est extrêmement simple, on vous veut vous faire comprendre les BDR pour que vous puissiez mieux les maîtriser. Pour faire ça, on s’y est mis à trois : je suis Serge Abiteboul et je fais ça avec deux amis, Benjamin Nguyen et Philippe Rigaux.
Intervention / Responsable scientifique



Thème
Documentation
Documents pédagogiques
Les données dans le Cloud et les Data centers

Il est intéressant de remarquer que la gestion de données dans un système de gestion de base de données (SGBD) n’a cessé de se compliquer. On pourra suivre cette évolution sur la figure ci-dessus. Considérons par exemple une application Toque qui utilise les données sur des recommandations de restaurants. Au départ, les données (les recommandations) et l’application (le code de Toque) sont sur le même ordinateur (architecture mono-machine). Dans les années 70-80, on est passé à une architecture client-serveur. On a placé le serveur (le SGBD et ses données) sur une machine dédiée, dotée des ressources adaptées, et les clients (les applications qui accèdent à ces données) sur d’autres, souvent des postes (les fameux micro-ordinateurs) remplaçant les terminaux passifs. Cette architecture a encore évolué à partir des années 90 par l’ajout d’un troisième niveau (« 3-tier ») en séparant la couche applicative et l’interface utilisateur.
Les raisons principales de cette complexité croissante tiennent essentiellement à l’augmentation des ressources nécessaires pour chaque composant :
- Les serveurs de données sont confrontés à des volumes de données sans cesse croissants, et doivent communiquer avec un nombre d’applications clientes elles-mêmes en constante progression. On parlait en Mégaoctets dans les années 80, en Téraoctets de nos jours, soit une croissance de l'ordre d’un million. Un serveur de données dans une grande entreprise doit satisfaire des milliers de requêtes simultanées. Ces tendances (et quelques autres, comme la sécurité) ont dicté l’affectation de ressources de calcul importantes aux SGBD.
- Les applications elles-mêmes ont grossi et se sont complexifiées. Notre application Toque, initialement écrite en Fortran et effectuant quelques opérations simples, est devenue une plate-forme Java complexe, utilisant des bibliothèques extérieures, fournissant des services Web, mettant en jeu un paramétrage lourd. L'installation et la maintenance d'une telle plate-forme sur les postes clients sont devenues des tâches très complexes : on préfère ne laisser au poste client qu’une couche logicielle mince dédiée à l’interface utilisateur.
Nous sommes en 2015, l'application Toque est devenue une référence avec une base de données ambitionnant de couvrir tous les restaurants du monde, des logiciels internes d’analyse et de recommandation gourmands en ressources, une interface sur le Web et des applications mobiles. De plus, le nombre d’utilisateurs de l’application varie assez fortement dans le temps, avec un pic de fréquentation le samedi en fin d’après-midi. Les dirigeants se posent la question : comment faire face à l’augmentation des ressources matérielles nécessaires, à leur maintenance, à leur renouvellement, tout en ne surdimensionnant pas leur système. Le cloud offre une solution.
Le cloud computing, ou l’informatique en nuage, est l'exploitation de la puissance de calcul ou de stockage de serveurs informatiques distants par l'intermédiaire d'un réseau, généralement l'internet. Ces serveurs sont loués à la demande, le plus souvent par tranche d'utilisation selon des critères techniques (puissance, bande passante, etc.) mais également au forfait. Il s'agit donc d'une délocalisation de l'infrastructure informatique. [A partir de Wikipédia, Cloud computing, 2015]
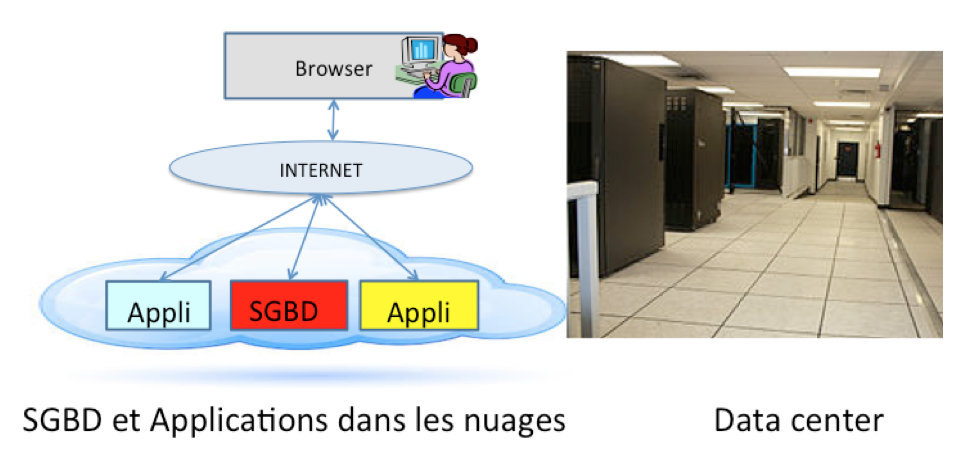
Dans le cas de la gestion de données, on va déporter le SGBD et l’application dans le cloud, c’est-à-dire dans des fermes de serveurs connectées à l’Internet (figure ci-dessus). Les données passent sur des machines, dont la localisation quelque part dans le monde n’a a priori pas d’importance, et idem pour les applications. Ce qui a permis de le faire c’est :
1. l’augmentation des vitesses et capacité des réseaux informatiques, et
2.
la disponibilité d’immenses ressources interconnectées de calcul et de
stockage – les fermes de serveurs – dotées de la technologie permettant
de les découper en machines virtuelles, configurables à la demande, pour
optimiser leur temps d’utilisation.
(De nombreuses questions, en particulier juridiques, apparaissent lors de l’utilisation du cloud. En effet, comme les données sont localisées dans plusieurs pays, quelles lois s’appliquent alors ? Par exemple, les lois sur la gestion des données personnelles diffèrent entre l'Europe et les Etats-Unis.)
On sait maintenant faire fonctionner des fermes de serveur avec des millions de processeurs, des PétaOctets (1 PO = 1 000 TO) de données. On peut construire, temporairement, à la demande, une infrastructure virtuelle pour exécuter à faible coût de très gros traitements, sans avoir à effectuer d’investissement lourd. Cette flexibilité permet également de répondre à un problème de charge variable au cours du temps.
Une ferme de serveurs, c’est d’abord une masse considérable de matériel informatique, des baies de processeurs, des baies de stockage, des réseaux informatiques, des réseaux de télécoms, un système électrique fournissant une puissance considérable, un système de climatisation consommant une part importante de cette électricité… C’est aussi un support pour les données de notre application Toque, avec des problématiques relevant de quasiment tous les sujets du Mooc Bador :
- L’architecture est évidemment distribuée pour gérér les millions d’utilisateurs et de restaurants, les milliards de recommandations et de commentaires (Semaine 6).
- La gestion efficace de ces grandes quantités de données conduit à l’optimisation de requêtes et aux index (Semaines 2,3).
- Les données ont une valeur considérable et doivent être très protégées dans le cloud. Cela passe bien sûr par la sécurité, et par exemple, la prévention d’accès non autorisés aux données (Semaine 4).
- Cette protection passe aussi par la résistance aux pannes afin d’assurer une disponibilité et une pérennité totales (Semaines 1,5). Les données sont par exemple répliquées pour être accessibles même quand certaines machines, certains réseaux sont en panne.
Avec un nombre massif de machines, de disques, des pannes arrivent statistiquement souvent. Un des défis techniques est le maintien opérationnel d’un système en dépit de la fréquence d’incidents plus ou moins graves. Un autre est la gestion de la climatisation : comment arriver à maintenir à faible coût les machines à une température raisonnable alors qu’elles dissipent une énergie considérable et qu’il peut faire chaud en dehors du centre. Des efforts importants sont consacrés à la baisse du « coût écologique » de tels centres.
Alors, doit-on recourir au Cloud pour nos données et nos applications ? Pesons le pour et le contre :
- Pour : l’absence d’investissement dans une infrastucture matérielle coûteuse, d’obsolescence rapide, dont la qualité de service (disponibilité, efficacité) est techniquement difficile à garantir.
- Pour : la délégation de la gestion des problématiques informatiques « bas niveau » (matériel, systèmes) à des compétences extérieures, afin de mieux pouvoir se concentrer sur son cœur de métier.
- Contre : le prix à payer est une dépendance accrue vis-à-vis des sociétés de service, et une certaine incertitude sur la sécurité des données confiées à une entité externe.
Recourir au cloud, pour une entreprise, c’est donc choisir une forme de spécialisation économique, avec les avantages et inconvénients connus et discutés depuis longtemps.
Pour conclure, observons qu’à une échelle plus modeste, le cloud c’est aussi la possibilité pour une PME, un individu, de disposer d’un serveur à très faible coût (quelques Euros par mois), connecté sur le Web, hébergeant un site web, un blog ou des applications plus ambitieuses. C’est la démocratisation de l’accès au Web en tant qu’acteur.
Complément : un déluge de données
Avec les mêmes intervenants et intervenantes
-
Degrés d'isolation dans les SGBD
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette sixième séquence, nous allons nous intéresser au degré d'isolation dans les SGBD c'est-à-dire des manières d'accepter des transgressions sur le concept de serialisabilité en échange d'un
-
Multi-hachage
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette dernière séquence de le deuxième partie, nous allons parler du multi-hachage.
-
Contrôle d'accès : introduction
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette quatrième partie, nous nous intéressons au contrôle d'accès qui est une problématique de sécurité d'accès à l'information. Nous allons commencer dans cette première séquence par présenter
-
Algorithmes de reprise sur panne
AbiteboulSergeNguyenBenjaminRigauxPhilippeAvec le journal de transactions que nous avons présenté dans la séquence précédente, nous sommes maintenant en mesure d'avoir un algorithme de reprise sur panne qui est tout à fait robuste. Nous
-
Les transactions : introduction
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette première partie, nous allons étudier les transactions et la concurrence c'est à dire le fait qu'il y ait plusieurs transactions qui arrivent en même temps. On va commencer par expliquer ce
-
Hiérarchie de mémoire
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette deuxième séquence, nous allons considérer une technique très efficace qui est la hiérarchie de mémoire.
-
Opérateurs
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette troisième séquence, nous allons commencer à étudier l’exécution des requêtes en se penchant sur le noyau des outils qu’on utilise qui sont les opérateurs dont les systèmes disposent pour
-
Modèle de contrôle d'accès obligatoire (MAC)
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette quatrième et dernière séquence sur le contrôle d'accès, nous allons voir le contrôle d'accès obligatoire ou Mandatory access control (MAC) en anglais.
-
Fragmentation
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette troisième séquence, on va parler de fragmentation.
-
Verrouillage à 2 phases
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette séquence, nous allons présenter une deuxième manière d'atteindre la sérialisabilité qui est le verrouillage à deux phases ou "two-phase locking" en anglais noté 2PL. En fait, ce qu'on a vu
-
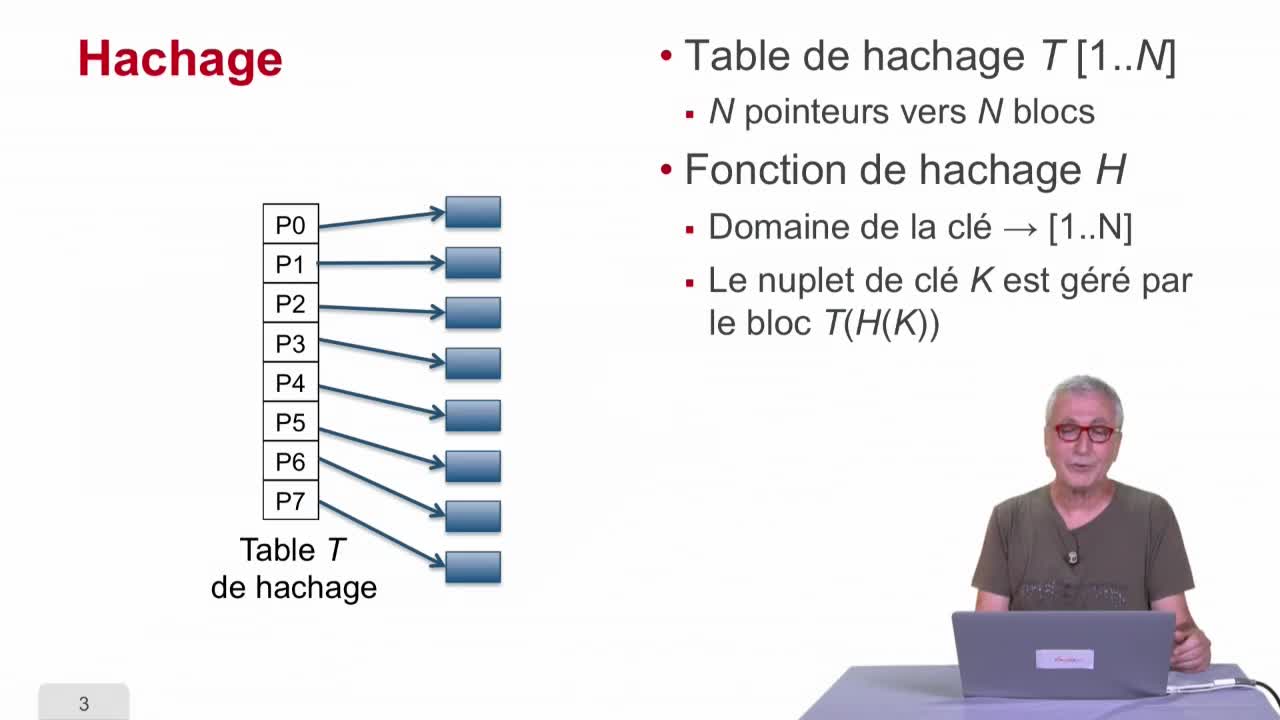
Hachage
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette séquence, nous allons étudier une technique qui s’appelle le hachage, fonction de hachage, qui à mon avis est une des techniques les plus cool de l’informatique.
-
Algorithmes de jointure
AbiteboulSergeNguyenBenjaminRigauxPhilippeNous continuons dans cette séquence 6 notre exploration du catalogue des opérateurs d’un SGBD en examinant un ensemble d’opérateurs très importants, ceux qui vont implanter les algorithmes de jointure