Notice
Modèle de contrôle d'accès obligatoire (MAC)
- document 1 document 2 document 3
- niveau 1 niveau 2 niveau 3
Descriptif
Dans cette quatrième et dernière séquence sur le contrôle d'accès, nous allons voir le contrôle d'accès obligatoire ou Mandatory access control (MAC) en anglais.
Intervention / Responsable scientifique



Thème
Documentation
Complément
<p>Fortement inspiré par Statistique et Société 2(4) : 33-41 par B.Nguyen - Licence CC-BY
Sécuriser les données par l’anonymisation
La sécurité des bases de données ne dépend pas seulement du contrôle d’accès. Dans certains cas, par exemple celui d’un administrateur de SGBD malhonnête prêt à diffuser le contenu de la base, ces dispositifs sont insuffisants. Il est donc préférable d’avoir réfléchi en amont aux informations que l’on souhaite conserver et qui sont susceptibles d’être communiquées frauduleusement ou par erreur. Une attention particulière doit être portée à la gestion de données personnelles, comme le nom, prénom, numéro de sécurité sociale, etc. La loi demande une déclaration à la CNIL de tout fichier (i.e., de toute base de données) traitant de données personnelles. Toutefois, si les données sont anonymes, alors plus aucune déclaration n’est nécessaire. Dit autrement, le risque associé au vol d’une donnée anonyme est supposé sinon nul, tout du moins très faible. Dans cet article, nous nous intéressons aux diverses techniques permettant de rendre une base de données anonyme.
Il existe légalement deux types de données : les données à caractère personnel, et les données anonymes. Les données sont à caractère personnel « dès lors qu’elles concernent des personnes physiques identifiées directement ou indirectement » pour citer la CNIL. Au contraire, toute donnée qu’il est impossible d’associer avec une personne physique sera dite « anonyme. » Il est intéressant de constater que la loi française définit une impossibilité forte, puisqu’elle précise que « pour déterminer si une personne est identifiable, il convient de considérer l'ensemble des moyens en vue de permettre son identification dont dispose ou auxquels peut avoir accès le responsable du traitement ou toute autre personne. » Plus mesuré, le projet de règlement Européen prévoit que « pour déterminer si une personne est identifiable, il convient de considérer l'ensemble des moyens susceptibles d'être raisonnablement mis en œuvre, soit par le responsable du traitement, soit par une autre personne, pour identifier ladite personne.
Ces définitions sous entendent qu'il existe plusieurs méthodes d’anonymisation, plus ou moins efficaces, au sens d’une protection plus ou moins « forte ». Pourquoi n’utiliserait-on pas toujours « la meilleure » ? Parce qu’il y a un coût à payer pour une anonymisation forte. Calculer une « bonne » anonymisation coûte en temps de calcul. Et puis, plus les données sont anonymes, moins elles sont précises. Par exemple, si on publie des informations au niveau d’un département on est beaucoup moins anonyme que si on les publie au niveau d’une région. Bien que tous ces facteurs entrent en jeu, le facteur déterminant reste cependant le type de modèle d’anonymisation utilisé.Comme nous allons le voir, il conditionne l’exploitation des données anonymes et peut la restreindre à certains types de calculs.
Pour illustrer ces techniques, considérons une base de données d’opinions politiques, composée d’une table dont un échantillon est donné ci-dessous. On repère dans un n-uplet des données dites sensibles comme une opinion politique. De manière évidente, si on connait le n° de sécu d'une personne, on peut accéder à son opinion politique.
|
Numéro de sécurité sociale (Identifiant) |
Age |
Code postal |
Sexe |
Parti politique (Donnée sensible) |
|
2401075123123 |
75 |
75005 |
F |
Les Républicains |
|
2750875123123 |
40 |
75012 |
F |
Parti socialiste |
|
1931175123123 |
12 |
78000 |
M |
Parti socialiste |
La pseudonymisation
La pseudonymisation consiste à supprimer les champs directement identifiants des enregistrements, et à ajouter à chaque enregistrement un nouveau champ, appelé pseudonyme, dont la caractéristique est qu’il doit rendre impossible tout lien entre cette nouvelle valeur et la personne réelle. Pour créer ce pseudonyme, on utilise souvent une fonction de hachage que l’on va appliquer à l’un des champs identifiants (par exemplele numéro de sécurité sociale), ce qui rend impossible (ou tout du moins extrêmement difficile) la déduction de la valeur initiale. On voit ainsi que deux entités possédant des informations sur une même personne, identifiée par son numéro de sécurité sociale, pourraient partager ces données de manière anonyme en hachant cet identifiant.
Le gros avantage de la pseudonymisation est qu’elle n’impose aucune limite au traitement subséquent des données. Tant que l’on traite des champs qui ne sont pas directement identifiants, on pourra exécuter exactement les mêmes calculs qu’avec une base de données non-anonyme. Ainsi, la Figure 2 illustre un exemple de calcul de la moyenne d’âge pour une opinion politique. L’utilisation de données pseudonymisées ne nuit pas à ce calcul.
Figure 2. Pseudonymisation et exemple de calcul
Figure 3. Un exemple de recoupement d'une base anonyme (source Sweeney 2002)
Toutefois, la pseudonymisation n’est pas reconnue comme un moyen d’anonymisation, car elle ne donne pas un niveau de protection suffisamment élevé : la combinaison d'autres champs peut permettre de retrouver l'individu concerné. Latanya Sweeney l’a mis en évidence aux Etats-Unis en 2001 en croisant deux bases de données, l’une, médicale, pseudonymisée et l’autre, électorale, avec des données nominatives, mais sans valeur sensible. Le croisement a été effectué non pas sur des champs directement identifiants, mais sur un triplet de valeurs : code postal, date de naissance et sexe. Il apparaît qu’un tel triplet caractérise uniquement environ 80% de la population des Etats-Unis[1] ! L. Sweeneya ainsi pu relier des données médicales à des individus (en l’occurrence le gouverneur de l’Etat).
Le k-anonymat
Afin de se protéger contre ce type d’attaque, appelée record linkage[2], Sweeney a proposé la technique de k-anonymat. Celle-ci consiste à flouter la possibilité de lier un n-uplet anonyme à un n-uplet non anonyme de la manière suivante :
1) déterminer les ensembles d’attributs (appelés quasi-identifiants) qui peuvent être utilisés pour croiser les données anonymes avec des données identifiantes ; puis
2) réduire le niveau de détail des données de telle sorte qu’il y ait au moins k n-uplets différents avec la même valeur de quasi-identifiant, une fois celui-ci généralisé (on dit alors que les individus font partie de la même classe d’équivalence).
« Généraliser » signifie en fait « enlever un degré de précision » à certains champs. Il devient impossible d’être sûr avec une confiance supérieure à 1/k que l’on a bien lié un individu donné à son n-uplet anonyme. L’avantage du k-anonymat est que l’analyse des données continue de fournir des résultats exacts, à ceci près qu’on ne peut pas dissocier les individus d'un groupe. Dans la Figure 4, nous montrons un exemple de généralisation des champs activité et âge d'une base de données d’opinions politiques sur des étudiants et enseignants d’une université. Les étudiants sont identifiés par leur niveau d’étude (L3, M1, etc.), qui se généralise en « étudiant », et les enseignants par leur position académique (doctorant, maître de conférences, etc.), qui se généralise en « enseignant ». Nous traçons dans cette figure l'origine de chaque n-uplet flouté.
Toutefois, une certaine quantité d’information reste dévoilée, en particulier de l’information négative : si on connaît le quasi-identifiant d’une personne, on pourra exclure tout un ensemble de valeurs (celles qui n’apparaissent pas dans la classe d’équivalence), ou bien savoir qu’elle a de plus grandes chances d’avoir une certaine valeur sensible. Dans une situation extrême, si tous les individus d’une classe d’équivalence possèdent les mêmes valeurs sur un champ intéressant l’attaquant, alors celui-ci sera capable d’identifier cette valeur de manière certaine pour un individu. C’est le cas pour les enseignants qui votent tous pour « Les Républicains ». On peut également voir qu’aucun M2 ne vote « Les Républicains ». Si on sait que John est un M2, alors on peut en déduire qu’il n’a pas voté L.R.
Figure 4. Anonymisation d'une table sur des données universitaires
Enfin, un problème technique important subsiste pour réaliser le k-anonymat : être capable de déterminer les généralisations à effectuer pour produire les quasi-identifiants, ce qui peut être fait soit par un expert humain qui connaît le domaine, ou bien par un calcul informatique, souvent très coûteux pour une base de données réelle.
La l-diversité
Comme on l’a vu à la Figure 4, il est parfois possible de déduire des informations dans certains cas pathologiques, sans faire le moindre croisement. Le modèle de la L-diversité répond à ce problème, en ajoutant une contrainte supplémentaire sur les classes d’équivalence : non seulement au moins k n-uplets doivent apparaître dans une classe d’équivalence, mais de plus le champ sensible associé à la classe d’équivalence doit prendre au moins L valeurs distinctes[3]. Dans l’exemple de la Figure 5, on voit que pour constituer de telles classes on doit parfois regrouper ensemble des étudiants et des enseignants. Leur activité est alors désignée de façon encore plus générale (« université »).
Figure 5. Données l-diverses
Cependant, en menant une attaque par croisement du même type que celle de Sweeney, il reste possible de déduire des informations. On voit par exemple dans la Figure 5 qu’on peut déduire qu’un étudiant de 20 ans aura une probabilité 0.33 (soit 1/k) de voter PS, 0.33 de voter LR et 0.33 de voter FN, mais surtout aucune chance de voter pour un autre parti ! Si on sait que Bill est la seule personne de la base dans ce cas de figure, alors on peut déduire des informations sensibles à son sujet.
Conclusion
Le problème de l’anonymisation des données, en vue d’assurer leur innocuité tout en permettant une analyse poussée, reste un problème ouvert. Même s’il existe des solutions pour garantir de manière formelle une certaine protection des données d’un individu (comme la confidentialité différentielle), celles-ci sont difficiles à mettre en œuvre. Aussi, et même si elles ne permettent pas de réduire totalement le risque, les instituts statistiques, tels l’INSEE recourent de manière pratique aux techniques de k-anonymat et L-diversité. En revanche, contrairement à ce que peut laisser penser son nom, la pseudonymisation n'est pas une technique d'anonymisation à proprement parler, et ne doit pas être utilisée en tant que telle. Le cœur du problème réside dans la possibilité de croiser des données de plusieurs sources. C’est d’ailleurs les réactions contre un projet gouvernemental d’identification de chaque citoyen par un numéro unique en vue de croisements des données de différentes administrations qui a conduit en 1974 à la création de la CNIL. Le citoyen perd le contrôle de ces données quand celles-ci sont concentrées sur des serveurs en charge de leur traitement. Des tentatives comme les « Personal information management systems »[4] ou « Secure Personal Data Servers »[5] essaient de rendre à chacun ce contrôle. Chacun gère ses données dans un serveur personnel (par exemple dans un espace personnel sur le cloud, ou dans du matériel sécurisé à son domicile) et autorise ou refuse les traitements. Les traitements de données doivent alors réalisés de manière décentralisée, chacun y participant pour garantir l’anonymat de tous.
Références
[1] L. Sweeney: “ k-anonymity: a model for protecting privacy”, International Journal on Uncertainty, Fuzziness and Knowledge-based Systems, 10(5), 2002. [2] A. Machanavajjhala , D. Kifer , J. Gehrke , etM. Venkatasubramaniam:“L-diversity: Privacy beyond k-anonymity”, ACM Transactions on Knowledge Discovery from Data, 1(1):2007. [3] C. Dwork :“Differential Privacy”, International Colloquium on Automata, Languages and Programming, 2006. [4] S.Abiteboul, B. André, D.Kaplan : “Managing Your Digital Life”, Communications of the ACM, Vol. 58(5), 2015. [5] T. Allard, N. Anciaux, L. Bouganim, Y. Guo, L. Le Folgoc, B. Nguyen, Ph. Pucheral, Ij. Ray, Ik. Ray, S. Yin “Secure Personal Data Servers: a Vision Paper”, Proceedings of the 36th International Conference on Very Large Data Bases (VLDB), vol. 3(1), 2010[1] Autrement dit : une personne qui appartient à ce groupe de 80% de la population est seule à posséder son triplet code postal - date de naissance – sexe. Dans le complément de 20%, les personnes partagent leurs triplets avec une ou plusieurs autres personnes.
[2] Liaison entre enregistrements
[3] On peut généraliser à plusieurs champs sensibles.
[4] Il faudrait en réalité baser cette génération sur la distribution réelle des maladies.
Dans la même collection
-
Modèle de contrôle d'accès discrétionnaire (DAC)
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette séquence, nous allons nous intéresser au contrôle d'accès discrétionnaire c'est à dire à la discrétion du propriétaire de l'objet en question. Ce modèle a été définit au début des années 90
-
Contrôle d'accès : introduction
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette quatrième partie, nous nous intéressons au contrôle d'accès qui est une problématique de sécurité d'accès à l'information. Nous allons commencer dans cette première séquence par présenter
-
Modèle de contrôle d'accès basé sur les rôles (RBAC)
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette troisième séquence, nous allons nous intéresser maintenant au contrôle d'accès basé sur les rôles qui est une évolution du contrôle d'accès discrétionnaire par le fait qu'on a maintenant


Avec les mêmes intervenants et intervenantes
-
Estampillage
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette quatrième séquence, nous allons présenter une technique pour atteindre la sérialisabilité des transactions qui est l'estampillage. Le principe est relativement simple : on va associer à
-
Hachage dynamique
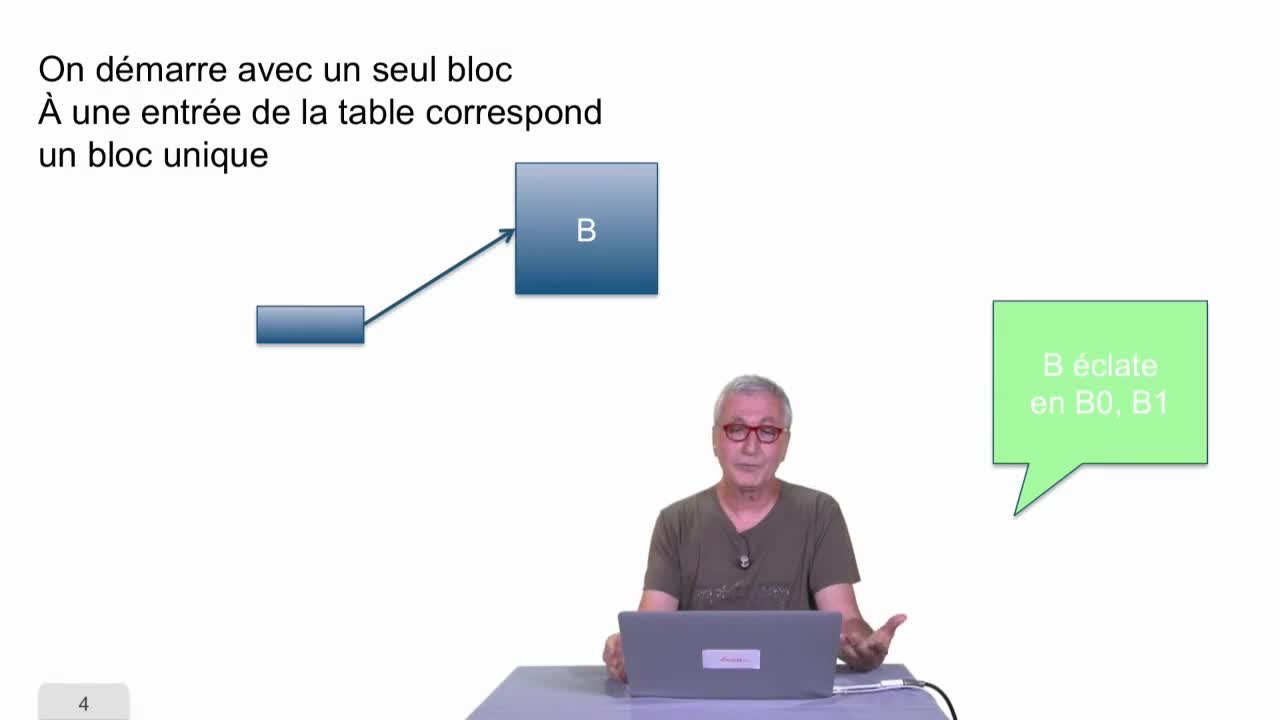
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette séquence, nous allons parler du hachage dynamique.
-
Optimisation
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette septième séquence, nous allons pouvoir maintenant récapituler à partir de tout ce que nous savons et en faisant un premier retour en arrière pour prendre la problématique telle que nous l
-
Algorithmes de reprise sur panne
AbiteboulSergeNguyenBenjaminRigauxPhilippeAvec le journal de transactions que nous avons présenté dans la séquence précédente, nous sommes maintenant en mesure d'avoir un algorithme de reprise sur panne qui est tout à fait robuste. Nous
-
Les transactions : introduction
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette première partie, nous allons étudier les transactions et la concurrence c'est à dire le fait qu'il y ait plusieurs transactions qui arrivent en même temps. On va commencer par expliquer ce
-
Indexation : introduction
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette deuxième partie du cours "Bases de données relationnelles", nous allons considérer des techniques d'indexation. Dans une première séquence, nous allons regarder des techniques plutôt
-
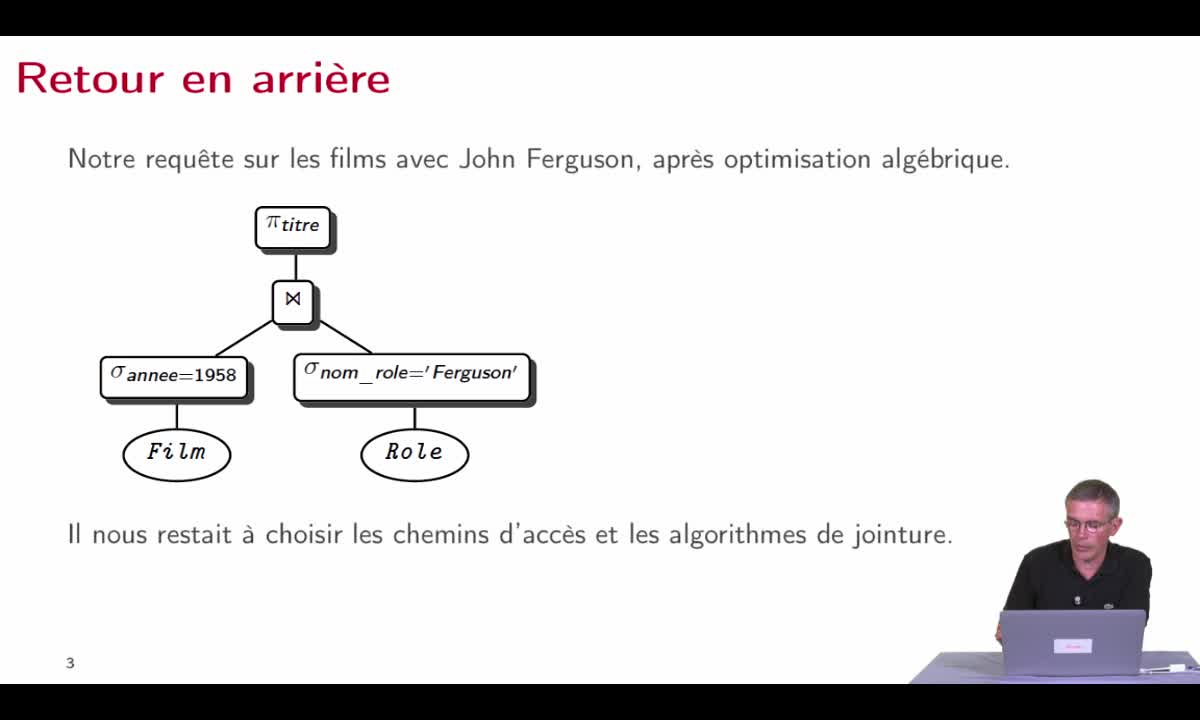
Réécriture algébrique
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette deuxième séquence, nous allons étudier la manière dont le système va produire, à partir d’une requête SQL, une expression algébrique donnant la manière d’évaluer cette requête, une première
-
Modèle de contrôle d'accès basé sur les rôles (RBAC)
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette troisième séquence, nous allons nous intéresser maintenant au contrôle d'accès basé sur les rôles qui est une évolution du contrôle d'accès discrétionnaire par le fait qu'on a maintenant
-
Fragmentation
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette troisième séquence, on va parler de fragmentation.
-
Verrouillage à 2 phases
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette séquence, nous allons présenter une deuxième manière d'atteindre la sérialisabilité qui est le verrouillage à deux phases ou "two-phase locking" en anglais noté 2PL. En fait, ce qu'on a vu
-
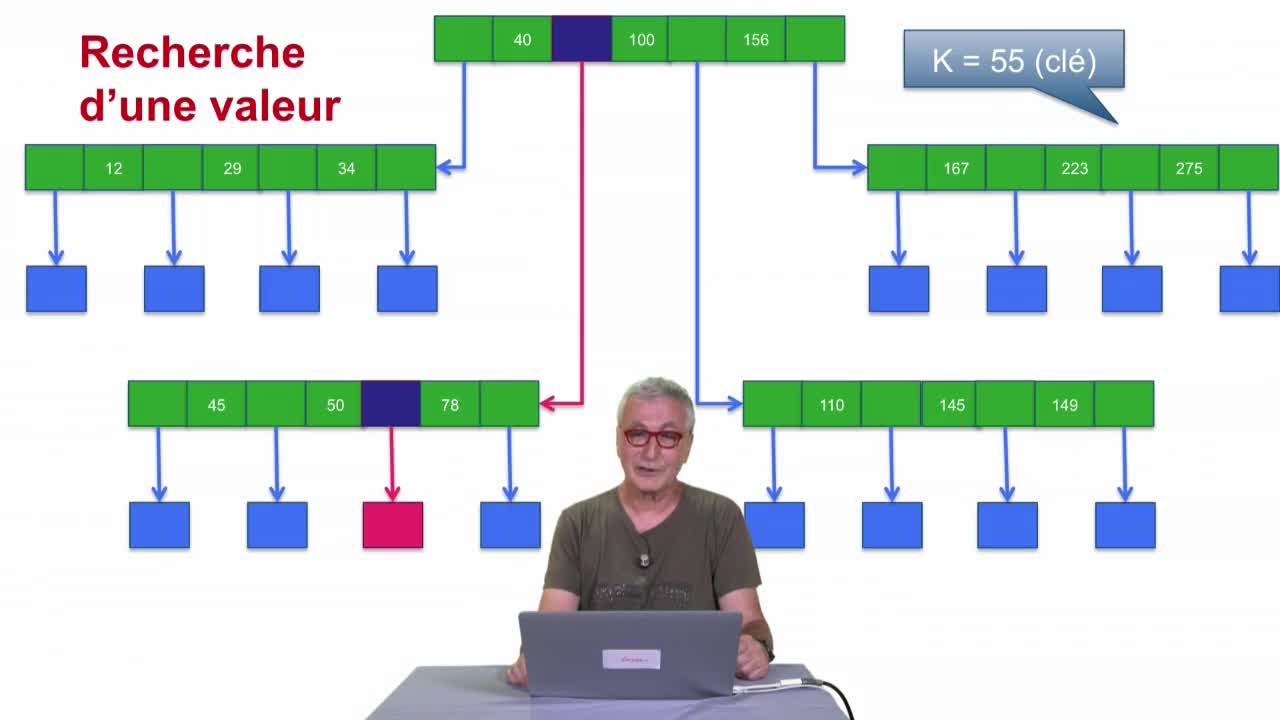
Arbre-B
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette séquence, nous allons parler de l’arbre B dont je vous ai déjà parlé la séquence précédente. Le point de départ est très simple : on a coupé le fichier en blocs et pour certains blocs on a
-
Tri et hachage
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette cinquième séquence, nous allons commencer à étendre notre catalogue d'opérateurs, en examinant deux opérateurs très importants : le tri et le hachage. En fait dans cette séquence, on va