Notice
Veille technologique et réalisations en programmation sur processeurs vectoriels à vecteurs longs
- document 1 document 2 document 3
- niveau 1 niveau 2 niveau 3
Descriptif
Les processeurs dotés de vecteurs longs sont aujourd'hui peu répandus dans l'écosystème des centres de calcul. Les processeurs vectoriels NEC SX-Aurora, qui possèdent des vecteurs de 256x64 bits ont fait l'objet de veille technologique pour le portage d'applications, dans le cadre de deux partenariats de NEC : d'une part avec le mésocentre CRIANN et d'autre part avec l'entreprise qui développe la bibliothèque MUMPS [1], solveur d'algèbre linéaire parallèle de référence. Au CRIANN, ces travaux ont été menés dans la perspective du projet MesoNET dont le volet calcul vectoriel sera mis en œuvre par ce mésocentre.
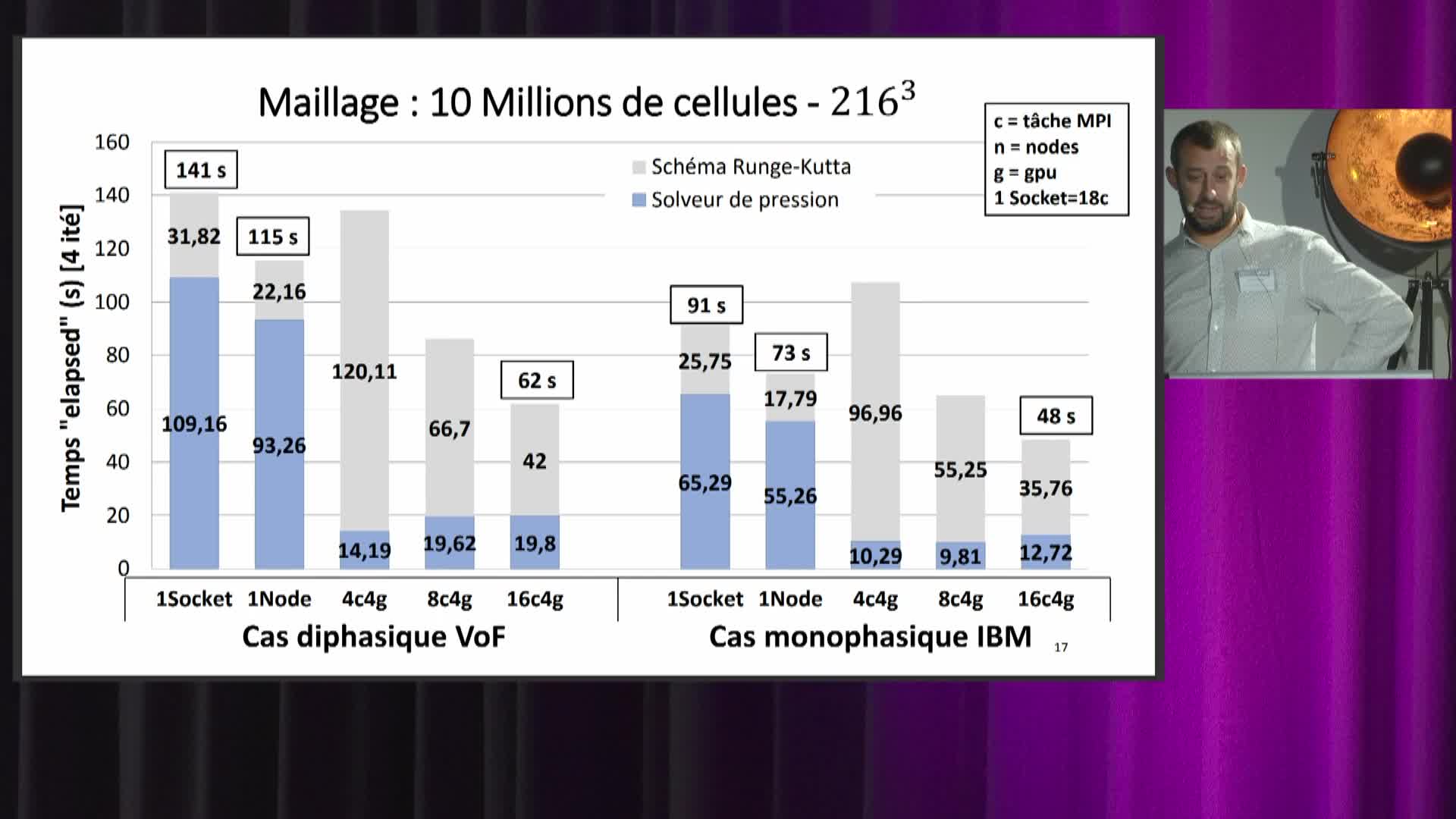
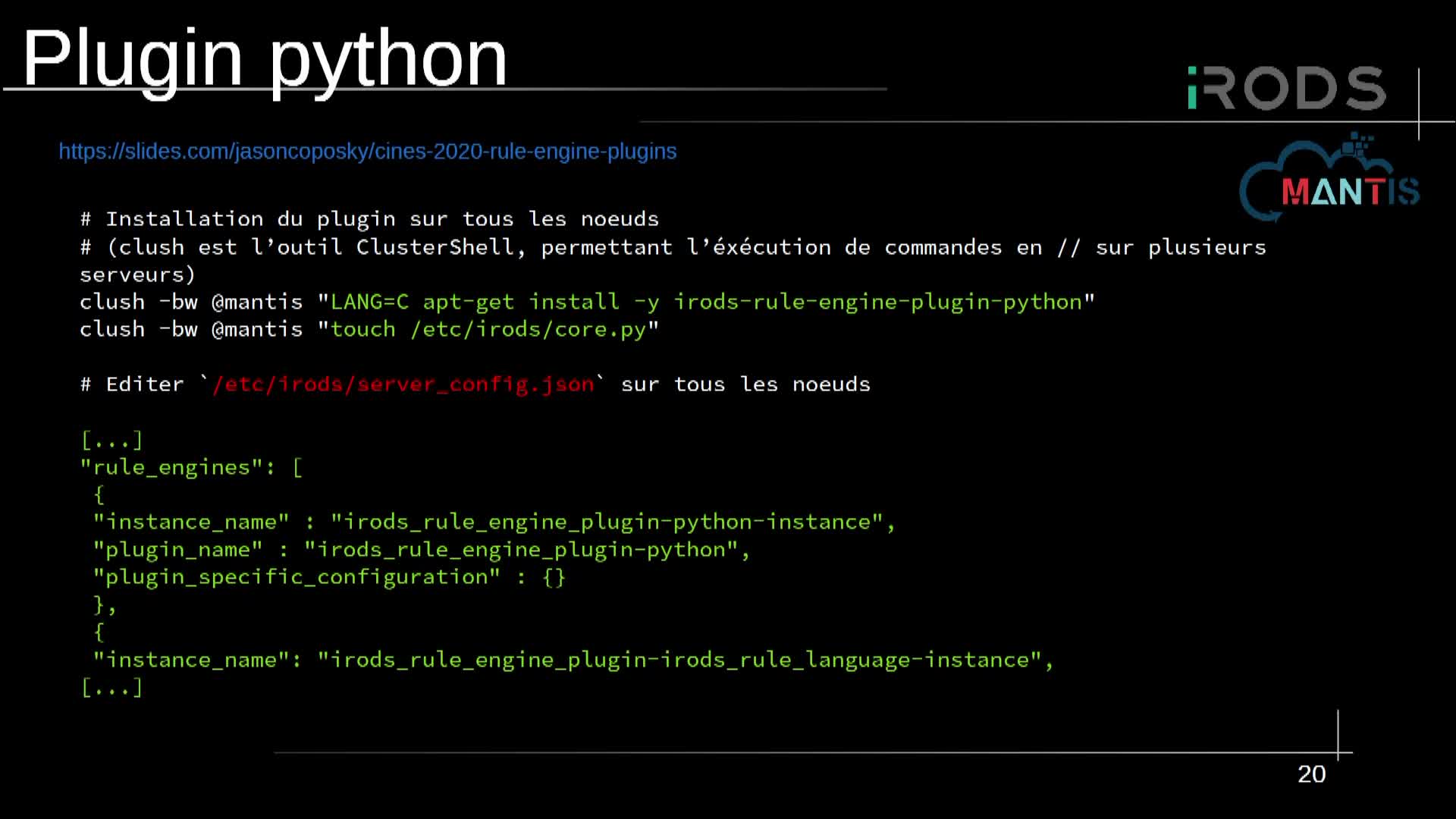
La veille technologique du CRIANN a d'abord porté sur des domaines et méthodes HPC mis en œuvre par des laboratoires normands. Le potentiel des processeurs vectoriels a été évalué pour des applications de traitement d'image. Préalablement aux portages de deux applications prévus sur les ressources de MesoNET à partir de l'automne 2022, les performances de noyaux de calcul les concernant ont aussi été analysées : noyau de calcul FFT 3D/MPI mis en jeu par une application de physique des matériaux, et noyau de calcul LBM (Lattice Boltzmann Method) pour des applications ciblées d'écoulements anisothermes avec changement de phase. Des facteurs d'accélération de 4 à 6 sont fournis par un processeur vectoriel par rapport à un serveur d'architecture x86 pour ces applications d'imagerie et ces noyaux. Le rapport de force entre Aurora et GPU Volta dépend de l'intensité arithmétique des codes, les processeurs vectoriels étant plus performants en bande passante mémoire et les GPU plus performants en puissance crête. En intelligence artificielle, le modèle d'apprentissage profond ResNet50 a aussi été évalué sur Aurora avec la librairie SOL. Une évaluation fonctionnelle de bibliothèques Python optimisées (Numpy, NCLPy), ainsi que de Spark/Frovedis a aussi été réalisée. Pour anticiper de potentiels besoins pour MesoNET, l'environnement logiciel permettant le calcul hybride x86/vector engine (offloading) a été enrichi d'une version FORTRAN de l'API VEDA (Vector Engine Driver API). Enfin, la réalisation la plus aboutie du partenariat CRIANN/NEC concerne l'application de dynamique moléculaire Quantum Espresso, optimisée sur Aurora [2] pour des cas tests du laboratoire LCS de l'ENSICAEN. Un facteur d'accélération de 3,5 a été obtenu dans la comparaison entre Aurora et AMD 7642 (réduction de temps machine à iso-nombre de Watts, ou réduction du nombre de Watts à même temps machine). Les techniques de programmation mises en œuvre pour ce portage seront le cœur de la première partie d'intervention.
La deuxième partie portera sur l'optimisation vectorielle de la bibliothèque MUMPS, travail réalisé principalement par les auteurs de ce solveur, au sein de Mumps Tech [3] avec un accompagnement de NEC. Mumps Tech [3] est une start up créée par une ingénieure et un chercheur de l'Inria et un enseignant-chercheur de Toulouse INP-ENSEEIHT. MUMPS est un solveur direct multifrontal parallélisé en OpenMP et MPI. Il permet la résolution de grands systèmes linéaires creux de manière rapide et robuste. Lors de cette intervention nous aborderons la démarche d'optimisation et de vectorisation, ainsi que l'offload sur processeur X86 de la partie scalaire. Nous aborderons également les échanges ayant permis l'amélioration du compilateur. Les travaux en cours et perspectives seront également abordés (en particulier la capacité à exploiter le format Block Low-Rank avec compression de rang faible des données).
Thème
Documentation
Dans la même collection
-
-
-
-
-
-
-
-
-
Recherche Data Gouv : un écosystème au service du partage et de l'ouverture des données de recherche
Un écosystème au service du partage et de l’ouverture des données de recherche
-
-
-
Refroidissement par immersion de serveurs : premiers retours opérationnels
Le refroidissement par immersion n'est pas une nouveauté, de l'IT en général au HPC en particulier. Il y a 35 ans, les Cray-2 et successeurs avaient leur assemblage de tours immergées dans un fluide