Notice
Glitter makes SPARQL : glitter, un package R pour explorer et collecter des données du web sémantique - PANELS
- document 1 document 2 document 3
- niveau 1 niveau 2 niveau 3
Descriptif
La collecte de données du web sémantique, qui sont formalisées selon le modèle RDF, nécessite l’élaboration de requêtes dans le langage dédié SPARQL. Ce langage, qui est aux données du web sémantique ce que SQL est aux bases de données relationnelles, a ainsi un objectif très spécifique et demeure assez méconnu des utilisateurs de données.
Au contraire, R est un langage de programmation assez généraliste puisqu’il permet de gérer de nombreux aspects de la chaîne de traitements de données, depuis leur recueil jusqu’à leur valorisation (par des modèles, graphiques, cartes, rapports, applications, etc.).
Le package glitter permet aux utilisateurs de R sans connaissance préalable de SPARQL (analystes de données, chercheurs, étudiants) d’explorer et collecter les données du web sémantique. Par des commandes R, l’utilisateur peut générer des requêtes SPARQL, les envoyer aux points d’accès de son choix, et recueillir les données correspondantes. Ces étapes sont ainsi intégrées à l’environnement R dans lequel l’utilisateur peut également réaliser les étapes d’analyse et de valorisation des données, dans une chaîne de traitement reproductible.
Lors de cette présentation, Lise Vaudor montrera les principales fonctionnalités du package glitter à partir d’exemples. Le package est toujours en développement mais il est fonctionnel, documenté et peut être installé par les participants qui souhaitent le tester en suivant les instructions décrites sur cette page.
Sur le même thème
-
Valoriser les données de la recherche en SHS : dépôt et diffusion des données sur PROGEDO
MboméMarieLa mise en libre accès des données de recherche accroît la visibilité et renforce la crédibilité des travaux scientifiques en assurant une plus grande transparence des méthodologies.
-
Formation à la veille Mir@bel : 3. navigation pour un utilisateur authentifié
DandieuClaireDecampLudovicTroisième volet de la formation à la veille de Mir@bel.
-
Formation à la veille Mir@bel : 2. navigation personnalisée
DandieuClaireDecampLudovicVerlengia BertanhaCarolinaDeuxième volet de la formation à la veille de Mir@bel.
-
[Podcast C'est pas donné] [S01:E02] Karine Pellerin et Caroline Moine
PetitMaximilienBrittoAugustoPellerinKarineMoineCarolineComment comprendre l’institutionnalisation de la question des données de recherche ? Est-ce qu’il existe un décalage entre les préconisations et les pratiques sur le terrain ? Comment passer du
-
Gérer et ouvrir mes données de recherche : les bonnes pratiques-PUDD
BouillardLénaProstRachelLiseron-MonfilsMaélysDans un esprit d’ouverture et de partage des savoirs scientifiques, l’équipe de documentalistes de l’Atelier de la donnée dat@UBFC viendra aborder les bonnes pratiques de gestion et d’ouverture des
-
Le nouveau catalogue de Quetelet-Progedo Diffusion-PUDD
PROGEDO a pour but de développer la culture des données pour la recherche en sciences sociales. Pour mener à bien cette mission Quetelet-Progedo-Diffusion rénove son portail d’accès aux données.
-
Atelier de découverte Mir@bel - Seconde partie (pour les partenaires)
DescollongesAmélieSuite de la présentation de Mir@bel donnée par Amélie Descollonges, chargée du projet Rev@ntiq
-
Atelier de découverte Mir@bel - Première partie
DescollongesAmélieIntroduction à Mir@bel donnée par Amélie Descollonges, chargée du projet Rev@ntiq
-
Référencement dans le DOAJ
RibbePaulinChollierVincentGarcía ReáteguiGalaTroisième webinaire dédié au processus de référencement dans le DOAJ, organisé dans le cadre du projet FNSO Mir@bel2022
-
Formation à la veille Mir@bel : 1. découverte du site
DandieuClaireDecampLudovicVerlengia BertanhaCarolinaPremier volet de la formation à la veille de Mir@bel, pour les partenaires qui mettent à jour les informations sur les revues.
-
Twitter et la linguistique située : réflexions méthodologiques à partir de l’exemple de tweets sur …
BachMatthieuDa CostaArnaudCette communication s’inscrit dans le cadre du projet de recherche interdisciplinaire POPSU visant à entre autres à analyser l’identité métropolitaine et identifier les intérêts des citoyens. Pour
-
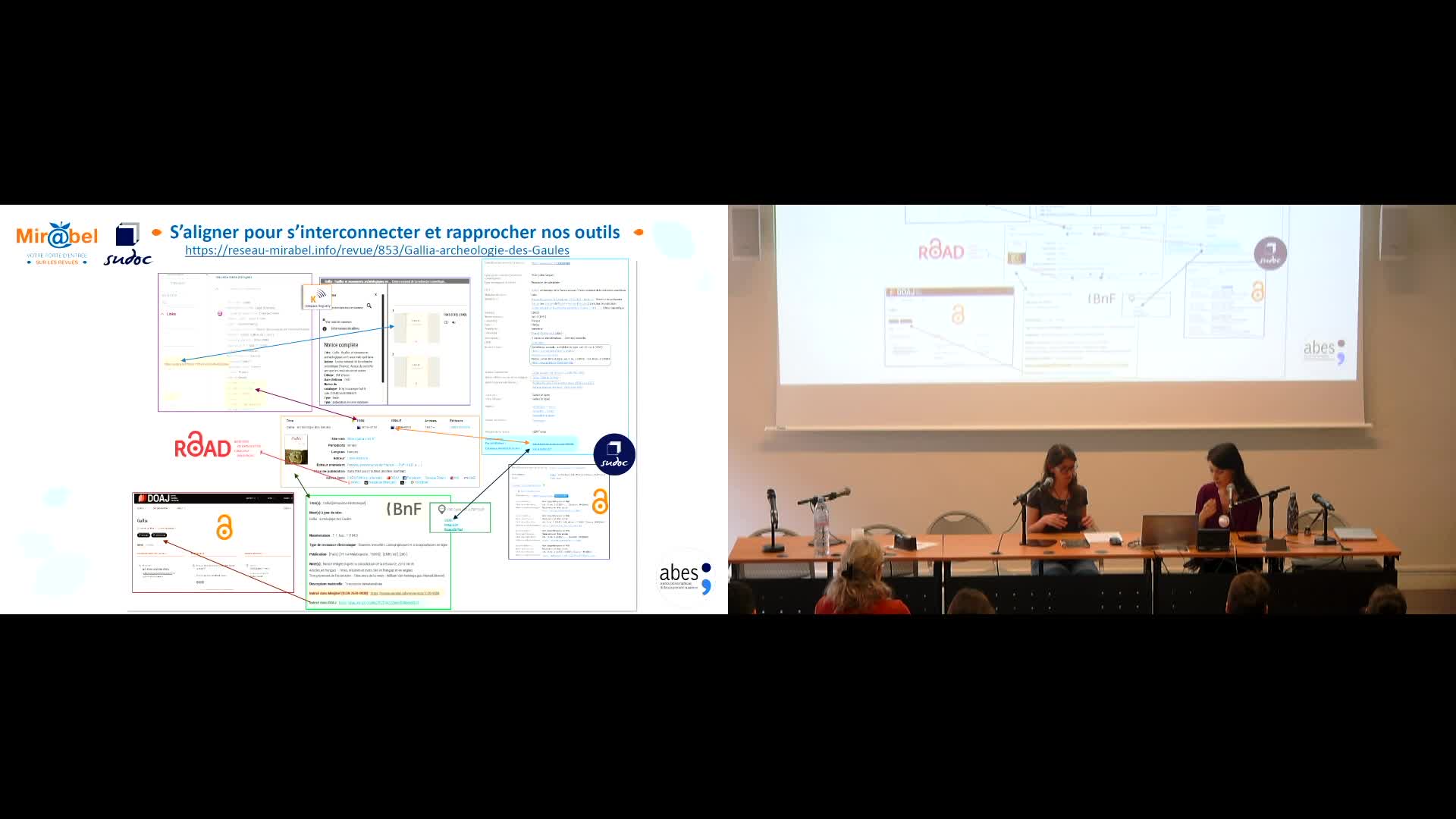
Mir@bel s'aligne : un travail au bénéfice de toutes et tous
ParraMorganeDandieuClairePrésentation des actions d'alignement dans Mir@bel