Notice
Optimisation
- document 1 document 2 document 3
- niveau 1 niveau 2 niveau 3
Descriptif
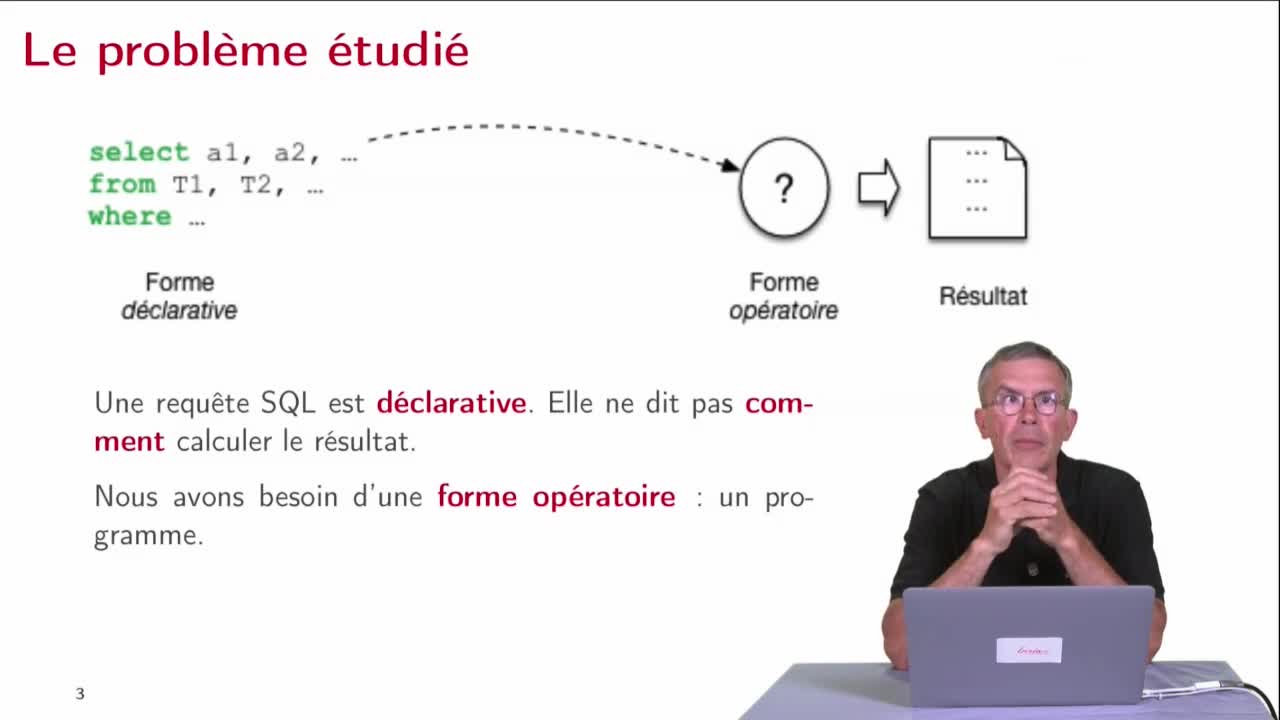
Dans cette septième séquence, nous allons pouvoir maintenant récapituler à partir de tout ce que nous savons et en faisant un premier retour en arrière pour prendre la problématique telle que nous l’avions examinée au départ...
Intervention / Responsable scientifique



Thème
Documentation
Complément
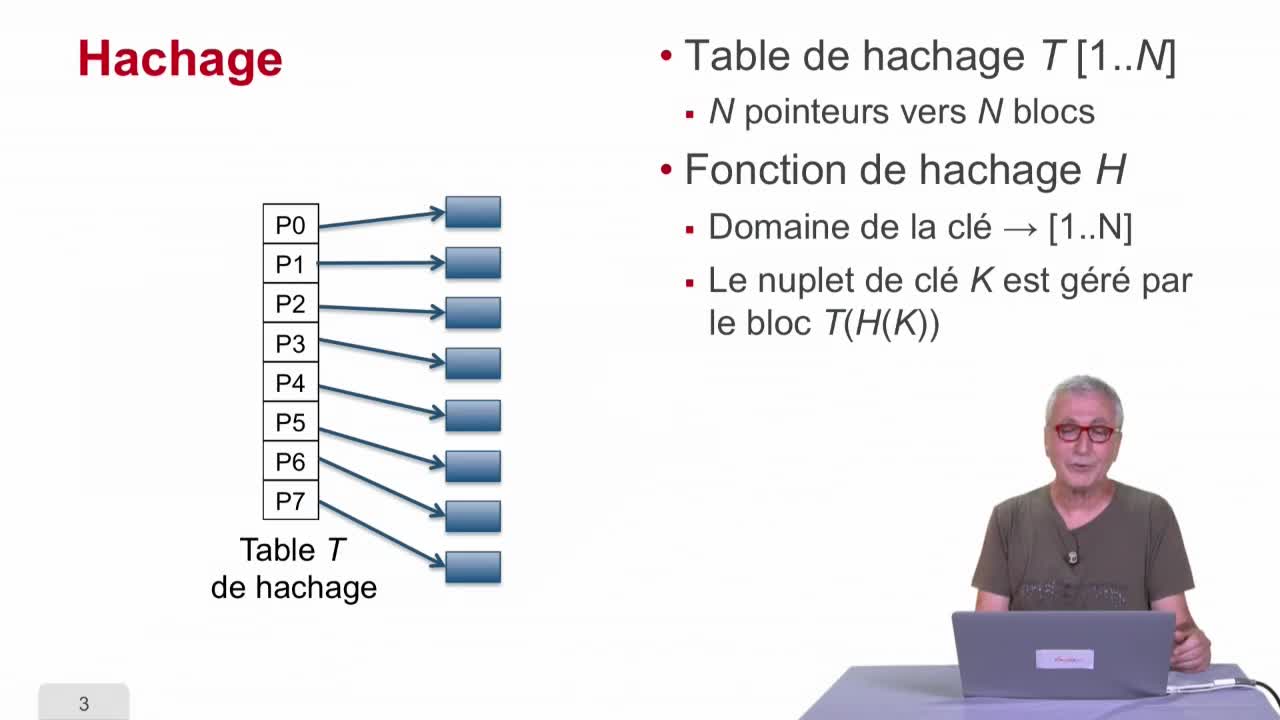
Les applications, SQL et les SGBD
On peut utiliser SQL pour inspecter une base de données ou pour consulter quelques nuplets particuliers. Mais cela reste d’un intérêt limité. En pratique, SQL est surtout utilisé à travers une application comme langage d’accès aux données d’une ou plusieurs bases.
Comment se passe cette intégration de SQL dans un langage de programmation ? La méthode la plus simple consiste à recourir à une librairie de fonctions implantant une interface d’accès au SGBD. On parle d’API (Application Programming Interface), ou de pilote (« driver »). Voici un exemple concret avec l’API JDBC, une interface normalisée pour accéder aux bases relationnelles depuis une application java. On parcourt un ensemble d’utilisateurs et on regarde à quels MOOC ils sont inscrits. (La syntaxe a été légèrement simplifiée ; ne cherchez pas à compiler !)
ResultSet utils = executeQuery( "SELECT * FROM Utilisateur") ; while (utils.next()) { println ("Nom de l’utilisateur: " + utils.getString("nom")) ; // Cherchons ses MOOCs id_util = utils.getString("id")) ResultSet moocs = executeQuery( "SELECT * FROM Mooc where id_util= :id_util") ; while (moocs.next()) { // Affichage du mooc, etc. } } utils.close()Ce petit bout de code devrait se comprendre tout seul. On reconnaît le motif d’accès vu et revu dans le cours et basé sur la notion d’itérateur :
- on initialise dans la phase ‘open()’, ici ‘executeQuery(),
- on itère sur le résultat dans la phase ‘next()’, ici ‘fetch()’, et finalement,
- on libère les ressources avec close().
En fait, une interface de ce type permet au client de « piloter » l’exécution de la requête sur le serveur en dialoguant avec la racine du plan d’exécution. Si ce n’est pas clair, nous vous invitons à reprendre soigneusement les notions vues en cours.
Où est le problème ? En fait il y en a deux : l’optimisation et le décalage entre le langage de programmation et SQL.
L’ optimisation. Le premier problème est directement lié au sujet de cette semaine, l’optimisation. Toutes les données utilisées par l’application pourraient être obtenues par une seule jointure.
select * from Utilisateur as u, Mooc as m where u.id = m.id_utilL’utilisation de deux requêtes dans le code correspond à une certaine logique de l’application : on veut d’abord afficher le nom d’un utilisateur, puis la liste de ses MOOCs. Elle entraine un grave inconvénient : le système va devoir exécuter une fois la requête
select * from Utilisateurpuis exécuter la seconde autant de fois qu’il y a d’utilisateurs !
select * from Mooc where id_util = :id_utilReportez-vous au cours (et à la réflexion qui en découle) pour vous convaincre que cette méthode d’accès est loin d’être optimale. Elle prive l’optimiseur de la possibilité de trouver le plan d’exécution approprié pour la jointure. En pratique, on peut obtenir une grave dégradation des temps de réponse. Le symptôme, identifié sous le nom des ‘1+n requêtes’ est connu et n’a, a priori, pas de solution évidente.
Que faire ? Nous reviendrons sur cette question après avoir considéré le second problème.
Les bases de données objets. D’un point de vue d’ingénierie logicielle, la cohabitation de deux langages basés sur des paradigmes totalement différents est peu satisfaisante. D’un côté, on a un langage (java ici) où tout est objet, et de l’autre un langage d’interrogation déclaratif (SQL) qui manipule des nuplets. Dans la pratique, les développeurs sont donc amenés à écrire répétitivement du code de conversion des nuplets en objets. Ce code est parfaitement stupide, lourd à maintenir, et coûteux en terme de la productivité.
C’est ce qui a conduit aux bases de données objets. Dans une base de données objets, les données sont représentées sous forme d'objets persistants. Un seul paradigme est donc utilisé dans le stockage, par le langage de programmation, et sur l'écran. Cela facilite énormément la programmation d'application et améliore la productivité du programmeur d'application, qui peut prendre en compte "le même objet du disque à l'écran". Cette technologie proposée dans le milieu des années 80 s'est relativement peu imposée. Elle est devenue plus populaire depuis une dizaine d'années avec des systèmes open source, très simples d'utilisation, comme db4O. On peut trouver de nombreuses raisons à ce semi-échec, demi-succès comme (i) les décideurs dans les années quatre-vingt, quatre-vingt dix étaient alors peu familiers avec les langages orientés-objets, et (ii) les systèmes relationnels offrent une large gamme de services que les systèmes de bases de données objets ne proposaient pas alors.
Le mapping objet-relationnel. Pour répondre à ce second problème (le problème des deux langages), les systèmes relationnels ont introduit une couche logicielle intermédiaire qui se charge automatiquement de la conversion entre le monde relationnel et le monde objet. Cette approche s’appelle Object Relational Mapping (ORM), ce qui dit bien ce que cela veut dire. L'approche ORM est une adaptation approximative et relativement inélégante des bases de données objet. Voici la même fonctionnalité que précédemment, mais écrite en ORM (ici, Hibernate, un outil ORM très populaire). Comme précédemment, on a respecté la syntaxe mais on l'a quelque peu dégraissée pour montrer l’essentiel.
List<Utilisateurs> utilisateurs = createQuery("from Utilisateur"); for (Utilisateur util : utilisateurs) { println (`Nom : ` + util.getNom()) ; for (Mooc m : util.getMoocs()) { // du Mooc } }Dans ce code, tout est objet java, les tables sont vues comme des ensembles d’instances de classes Utilisateur ou Mooc. De plus, la couche ORM implante une navigation d’un objet à l’autre (par exemple la fonction getMoocs() associée à un utilisateur). Notre second problème est résolu : nous avons une couche d’accès aux données qui est totalement homogène, et on ne voit même plus de SQL. On poursuit en fait une démarche d’abstraction qui nous a mené des fichiers vers les bases de données, puis de ces dernières vers les langages de programmation objet.
Retour sur le premier problème. En quoi notre premier problème, celui d’une répétition non optimale de requêtes SQL élémentaires, peut-il lui aussi être résolu ? Et bien, la couche d’abstraction ORM va nous permettre d’indiquer, de manière déclarative, que les utilisateurs et leurs MOOCs doivent être récupérés ensemble, solidairement, par une jointure SQL. Nous ne montrons pas ici comment on effectue cette spécification car cela nous emmènerait trop loin, mais il est amusant de constater que les langages de requêtes pour les systèmes ORM les plus avancés (comme le langage HQL intégré à Hibernate) réinvente (de façon partielle et maladroite) des aspects de OQL, le langage déclaratif qui a été proposé comme standard pour les bases de données objet.
Ce qu’il faut retenir :
- Une approche naïve de l’intégration de SQL à une application résulte en une utilisation non optimale du SGBD et notamment de son optimiseur. (On peut d’autant mieux apprécier ce défaut que l’on a suivi le cours sur l’optimisation bien sûr !)
- Nous disposons, dans les langages objets, d’API qui vont faciliter la programmation d’applications.
- Nous disposons également de couches applicatives spécialisées qui vont produire les requêtes SQL pour nous et s’assurer que les possibilités d’optimisation du SGBD sont bel et bien exploitées.
Il n’ en reste pas moins que l’ajout d’une couche supplémentaire dans la pile des niveaux d’abstractions entre l’utilisateur et les données est une source réelle de complexification des architectures applicatives, avec les inconvénients (performance notamment) qui en découlent. Le succès des solutions de type Hibernate (et autres, équivalentes, intégrées aux frameworks de développement) montre que le choix est bien souvent de privilégier la clarté du code applicatif sur la cohabitation du requêtes SQL et d’un langage objet.
Pour en savoir plus :
- Les patterns d’accès aux bases de données, et notamment les Data Access Objects (DAO), cf. par exemple http://www.oracle.com/technetwork/java/dataaccessobject-138824.html
- Un tutoriel sur Hibernate, https://docs.jboss.org/hibernate/orm/3.5/reference/fr-FR/html/tutorial.html
- Le cours de Philippe Rigaux sur les ORM : http://orm.bdpedia.fr.
Dans la même collection
-
Réécriture algébrique
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette deuxième séquence, nous allons étudier la manière dont le système va produire, à partir d’une requête SQL, une expression algébrique donnant la manière d’évaluer cette requête, une première
-
Plans d'exécution
AbiteboulSergeNguyenBenjaminRigauxPhilippeNous avons vu dans la séquence précédente, les opérateurs qui sont des composants de base avec lesquels nous allons construire nos programmes d’évaluation de requêtes. Dans cette quatrième séquence,
-
Exécution et optimisation : introduction
AbiteboulSergeNguyenBenjaminRigauxPhilippeCette partie 3 du cours sera consacrée à l'exécution et à l'optimisation de requêtes. Nous avons vu, dans les semaines précédentes, comment les données étaient organisées physiquement dans des
-
Algorithmes de jointure
AbiteboulSergeNguyenBenjaminRigauxPhilippeNous continuons dans cette séquence 6 notre exploration du catalogue des opérateurs d’un SGBD en examinant un ensemble d’opérateurs très importants, ceux qui vont implanter les algorithmes de jointure
-
Opérateurs
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette troisième séquence, nous allons commencer à étudier l’exécution des requêtes en se penchant sur le noyau des outils qu’on utilise qui sont les opérateurs dont les systèmes disposent pour
-
Tri et hachage
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette cinquième séquence, nous allons commencer à étendre notre catalogue d'opérateurs, en examinant deux opérateurs très importants : le tri et le hachage. En fait dans cette séquence, on va





Avec les mêmes intervenants et intervenantes
-
Hiérarchie de mémoire
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette deuxième séquence, nous allons considérer une technique très efficace qui est la hiérarchie de mémoire.
-
Opérateurs
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette troisième séquence, nous allons commencer à étudier l’exécution des requêtes en se penchant sur le noyau des outils qu’on utilise qui sont les opérateurs dont les systèmes disposent pour
-
Reprise sur panne : introduction
AbiteboulSergeNguyenBenjaminRigauxPhilippeNous débutons la partie 5 de ce cours qui va être consacré à la reprise sur panne. La reprise sur panne est une fonctionnalité majeure des SGBD, elle est extrêmement apprciable puisqu'elle garantit la
-
Optimisation de requête
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette séquence, on va parler d'optimisation de requête, on va montrer comment toutes les techniques d'optimisation de requête qui avaient été développées dans le cas centralisé peuvent être
-
Pannes de disque
AbiteboulSergeNguyenBenjaminRigauxPhilippeNous allons conclure cette partie 5 en examinant le cas de panne le plus grave qui est la perte d'un disque.
-
Présentation du cours de bases de données relationnelles
AbiteboulSergeNguyenBenjaminRigauxPhilippeBienvenue dans ce cours sur les bases de données relationnelles. Le but de cet enseignement est extrêmement simple, on vous veut vous faire comprendre les BDR pour que vous puissiez mieux les
-
Hachage
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette séquence, nous allons étudier une technique qui s’appelle le hachage, fonction de hachage, qui à mon avis est une des techniques les plus cool de l’informatique.
-
Algorithmes de jointure
AbiteboulSergeNguyenBenjaminRigauxPhilippeNous continuons dans cette séquence 6 notre exploration du catalogue des opérateurs d’un SGBD en examinant un ensemble d’opérateurs très importants, ceux qui vont implanter les algorithmes de jointure
-
Le journal des transactions
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette séquence, nous allons étudier le mécanisme principal qui assure la reprise sur panne qui est le journal de transactions ou le log.
-
Conclusion : cinq tendances
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette dernière séquence du cours, nous allons examiner des tendances des bases de données distribuées.
-
Verrouillage hiérarchique
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette dernière séquence de la première partie, nous allons nous intéresser au verrouillage hiérarchique. C'était une autre manière d'améliorer les performances des transactions dans les bases de
-
Exécution et optimisation : introduction
AbiteboulSergeNguyenBenjaminRigauxPhilippeCette partie 3 du cours sera consacrée à l'exécution et à l'optimisation de requêtes. Nous avons vu, dans les semaines précédentes, comment les données étaient organisées physiquement dans des