Notice
Conclusion : cinq tendances
- document 1 document 2 document 3
- niveau 1 niveau 2 niveau 3
Descriptif
Dans cette dernière séquence du cours, nous allons examiner des tendances des bases de données distribuées.
Intervention / Responsable scientifique



Thème
Documentation
Complément 1,Complément 3,Complément 2

(No SQL)
Depuis des années, SQL (Structured Query Language) est le langage standard normalisé pour interroger et mettre à jour des bases de données relationnelles. Il s’est imposé jusque dans les systèmes pour construire des sites Web, avec PHP-MySQL. Mais les exigences d’applications « extrêmes » ont conduit à remettre en question sa suprématie. On retrouve des demandes difficiles à satisfaire avec des systèmes relationnels dans deux grandes classes d’applications :
- Applications transactionnelles : on peut avoir des millions de transactions à traiter par seconde, et ce vingt-quatre heures sur vingt-quatre. C’est le cas par exemple pour des sites de E-commerce comme Amazon.
- Applications décisionnelles : on doit réaliser des calculs, notamment statistiques, sur des téraoctets de données. C’est le cas par exemple pour des sites de recommandation comme Netflix.
Enfin, certaines applications, comme le trading haute-fréquence (ou trading algorithmique) marient les contraintes du transactionnel (volume important de transactions, besoin évident de rapidité) et du décisionnel (calculs complexes à mettre en œuvre avant de prendre la décision d’acheter ou vendre).
Quand on utilise les bons vieux systèmes relationnels sur de telles applications, ça rame… Quand on essaie de comprendre pourquoi, on réalise que les systèmes relationnels paient un fort overhead pour leur universalité, c’est-à-dire le fait qu’ils sont destinés à traiter tout type d’application, avec des données très diverses dans leur représentation, dans leur structure et leur volumétrie. Les difficultés rencontrées pour les applications mentionnées ci-dessus ont conduit à considérer des systèmes de gestion de données spécialisés qui passent à l’échelle des grands systèmes transactionnels ou décisionnels, mais en abandonnant cette universalité.
Les systèmes relationnels permettent par exemple à plusieurs utilisateurs de partager des données de manière contrôlée grâce à un système de verrous ; la pose de verrou sur une donnée ou sur un morceau d’index particulier par une application garantit qu’aucune autre application ne va toucher cette information. Ce système de verrous est essentiel pour assurer des propriétés fondamentales comme la cohérence d’une base de données et de son évolution, mais il est aussi complexe et coûteux en temps. On peut améliorer les performances en le remplaçant par un protocole de partage moins sûr mais plus performant. Dans le cadre des systèmes distribués, un théorème proposé par Eric Brewer vient encourager un tel abandon. Le Théorème CAP explique qu’il est impossible de répondre aux trois exigences suivantes à la fois :
-
- Cohérence (consistency) : la valeur d’une donnée à un instant donné est la même pour chaque participant au système.
- Disponibilité (availability) : une donnée doit toujours être accessible même en cas de panne.
- Tolérance au partionnement : le système doit continuer à fonctionner même quand il est fragmenté par des problèmes de réseaux.
Dans des situations très distribuées, comme c’est le cas pour des applications qui travaillent à l’échelle duWeb, on peut choisir d’abandonner les exigences strictes en terme de cohérence (résumées par les propriétés ACID des transactions) au profit de la fluidité d’une exécution transactionnelle massive.
Une autre particularité fréquente des systèmes NoSQL est de s’appuyer sur des modèles de données plus simples que le modèle relationnel, des langages plus simples que SQL. Par exemple, plutôt que de considérer des tableaux à plusieurs colonnes, on va se limiter à associer des valeurs à des clés (comme dans un dictionnaire). On va aussi tirer un trait sur des opérations complexes comme la « jointure ». Quand on fait tout ça, on aboutit à des systèmes d’une grande pauvreté en terme de puissance de représentation et d’interrogation. C’est de là que vient le nom « No SQL » : ce n’est pas qu’on est « contre » SQL, mais plutôt qu’on n’est « même pas » SQL et qu'on en est fier ! Certains préfèrent comprendre le sigle comme « Not only SQL ». Doit-on alors comprendre qu’on est au delà de SQL ou que SQL n’est pas la solution à tout ? Dans le fourre-tout du NoSQL, on peut d'ailleurs trouver des propositions de modèles très spécialisés qui sur certains aspects sont plus riches que le modèle relationnel (par exemple pour représenter des graphes), avec des langages, eux aussi très spécialisés, qui proposent des opérations qui n’existent pas en SQL.
Mais nous nous intéressons surtout ici aux systèmes moins universels mais avec les performances extrêmes demandées. Ce n’est pas par miracle que ces systèmes arrivent à ces performances étonnantes : ils sont plus rapides parce qu'ils font moins de choses. C'est comme ça qu'on arrive à des passages à l’échelle de PétaOctets de données, de millions de transactions simultanées. C'est aussi parce qu'ils s'appuient typiquement sur des architectures massivement parallèles. La simplification des modèles trouve d’ailleurs là sa principalemotivation : simplifier pour pouvoir paralléliser et donc passer à l’échelle d’infrastructures s’appuyant sur des milliers, voire des millions de machines. Parfois, le concept même de machine devient obsolète, et ce sont des (réseaux de) cartes graphiques (processeurs intrinsèquement massivement parallèles, mais aux propriétés de calculs bien spécifiques) qui sont utilisés. Le NoSQL s’est donc imposé dans le monde du Big Data et dans celui des applications Web démesurées.
Si les systèmes NoSQL connaissent de grands succès, il faut bien être conscient de ce tout qu'on perd. Ce qu’un système de gestion de données ne fait pas, c’est à l’application de le prendre en charge. On ne dispose pas des langages de haut niveau si pratiques pour déléguer la gestion des données à des systèmes évolués. Avec un système NoSQL qui ne sait faire (certes, efficacement) que des put() et des get(), il faut écrire du code relativement bas niveau et complexe pour la moindre fonctionnalité que l’on souhaite introduire, le moindre contrôle que l’on veut garantir, la moindre mise à jour, etc. Tout cela représente potentiellement des pertes énormes de productivité, de fiabilité, et même d’efficacité (les systèmes relationnels, quoiqu’on en dise, savent faire des choix d’exécution intelligents, performants et adaptés au contexte).
L’engouement actuel pour ces systèmes mal connus, mal compris, non normalisés, dont on peut penser parfois à tort qu’ils représentent un progrès alors qu’ils ne sont que des solutions alternatives pour certaines niches, risque de conduire à des désillusions. Dans la plupart des cas, il reste préférable de recourir à un système relationnel pour ses langages normalisés, sa richesse de fonctionnalité, sa robustesse et même ses performances (mais oui). Réservons au NoSQL les applications avec tellement de données ou tellement de transactions que la solution relationnelle est exclue.
Pour aller plus loin :
-
-
- Nombreux exemples de systèmes NoSQL dans la page Wikipédia
- NoSQL, W3 resource
- Nombreux exemples de systèmes NoSQL dans la page Wikipédia
-
Calculer sur des données massives
in : Interstices, https://interstices.info/jcms/p_83082/calculer-sur-des-donnees-massives
,Gestion de données en pair-à-pair
Dans un réseau pair-à-pair, chaque machine est à la fois un serveur et un client. On parle de P2P pour peer-to-peer en anglais (pair-à-pair ou égal-à-égal). Le but est d’utiliser la distribution, comme dans les systèmes de bases de données distribuées. Une grande différence est que toutes les machines sont traitées sur le même rang; il n’y a pas de « maitre » ou d'« esclave ». Chaque machine est appelée un nœud et l’ensemble forme un réseau en pair-à-pair.
Le grand principe du P2P est la mise en commun et le partage de ressources. Avant de nous concentrer sur le partage de données, nous allons considérer d’autres types de partage, les partages de communication et de puissance de calcul.
Communications. On peut mettre en commun l’utilisation des réseaux de communication. Les premières versions de Skype supportaient des télécommunications sur IP en s’appuyant sur du P2P. On peut aussi considérer des réseaux mobiles dits « ad hoc ». Dans de tels réseaux sans fil, une communication passe d’un nœud à l’autre (d'un téléphone mobile à l'autre) depuis la source émettrice pour arriver à destination , sans passer par des points d’accès et des infrastructures spécialisées, comme c’est le cas pour le Wifi ou le GSM.
Calcul. On peut aussi partager des puissances de calcul. L’idée de départ, c’est que la puissance de calcul des ordinateurs est souvent inutilisée. Pensez au nombre d’heures chaque jour où votre ordinateur personnel au travail ou chez vous (si vous en avez un) ne fait rien. Quand vous ne vous en servez pas, un système P2P peut confier à votre ordinateur des calculs. En utilisant des milliers de machines inactives, on peut ainsi fabriquer une formidable puissance de calcul collaboratif. Par exemple, le projet Seti@home a utilisé cette approche pour analyser le spectre magnétique de signaux de l’espace et rechercher (sans succès) des traces d'intelligence extra-terrestres.
Données et information. Les systèmes P2P sont particulièrement adaptés à la diffusion et au partage de données et de l’information. Avec la réplication, ils facilitent la disponibilité, en offrant des moyens de pallier les pannes ou les inaccessibilités de serveurs (dues par exemple à une censure). Une des applications les plus populaires est le partage de fichiers, avec des protocoles comme BitTorrent. Si ce protocole est souvent utilisé pour obtenir des films en contournant le droit d’auteur, il est également appliqué dans un cadre cette fois tout à fait légal pour la gestion des mises à jour logicielles, que ce soit de systèmes d’exploitation comme Linux, ou de jeux vidéo comme World of Warcraft.
Comment ça marche ? Un fichier (par exemple un patch de mise à jour Linux) est proposé sur un réseau. Un pair va le télécharger pour pouvoir effectuer cette mise à jour (comme client). Il va en garder une copie, et pourra donc ensuite le fournir (agissant comme serveur) quand d’autres pairs vont réclamer cette mise à jour.
Arrêtons-nous un instant sur ce qui se passe pour une mise à jour de sécurité importante, ce qui va nous permettre de dégager un avantage essentiel du parallélisme. Dans une approche classique client-serveur, ce fichier est sur un serveur. Si le serveur tombe en panne, le fichier n’est plus accessible. S’il y a trop de demandes de téléchargement, le serveur pourrait être saturé. En P2P, plus le fichier est populaire, plus il est disponible sur de nombreux pairs. Même si certains d’entre eux sont temporairement inaccessibles, il en restera toujours pour proposer ce fichier. De plus, il est probable qu’un nœud « proche » rendra la communication super efficace. Si plusieurs nœuds proches de vous disposent du fichier, vous pourrez même en télécharger une partie chez chacun. Le parallélisme en action !
|
Le piratage. Cela concerne principalement les services de streaming et de téléchargement de films, de musique et de séries télé, qui violent le droit des auteurs à contrôler la diffusion de leurs œuvres. Malgré des lois de protection de la propriété intellectuelle comme Hadopi, les utilisateurs de tels services restent nombreux, des millions juste en France. Les systèmes de téléchargement en P2P ont tenu une grande place qui tend cependant à diminuer devant la surveillance accrue dont ils sont l’objet. |
Les réseaux P2P permettent d’augmenter les performances et la disponibilité des données. C’est au prix d’une plus grande complexité. Une difficulté est évidemment de coordonner le travail de machines autonomes, qui peuvent rejoindre le réseau ou le quitter de manière imprévisible, à des rythmes élevés. Une autre est de retrouver une information qui est stockée sur un des pairs du réseau. On distingue plusieurs approches :
- Le serveur d’index. On utilise un serveur qui gère un index des ressources disponibles. C’est évidemment la méthode la plus simple. Cependant, ce serveur devient un point de faiblesse. Par exemple, s’il est en panne, tout le réseau s’effondre.
- Les réseaux non-structurés. On diffuse la demande d’information massivement à des voisins, qui la transmettent à des voisins, jusqu’à tomber sur quelqu’un qui a l’information ou qui sait où la trouver. Evidemment, une difficulté est de choisir à quels voisins transmettre la demande ; une autre est d'éviter de saturer le réseau en envoyant chaque demande à tous les participants du réseau.
- Les réseaux structurés. On utilise une structure de données distribuée pour rechercher l’information. C’est par exemple une table de hachage distribuée (DHT pour distributed hash table) comme Chord ou Pastry. Une telle structure permet de retrouver à partir d’une clé (par exemple, le nom d’un fichier), le contenu correspondant (le fichier lui-même), et ce en utilisant un nombre de messages logarithmique dans le nombre de pairs actifs.
Dans la même collection
-
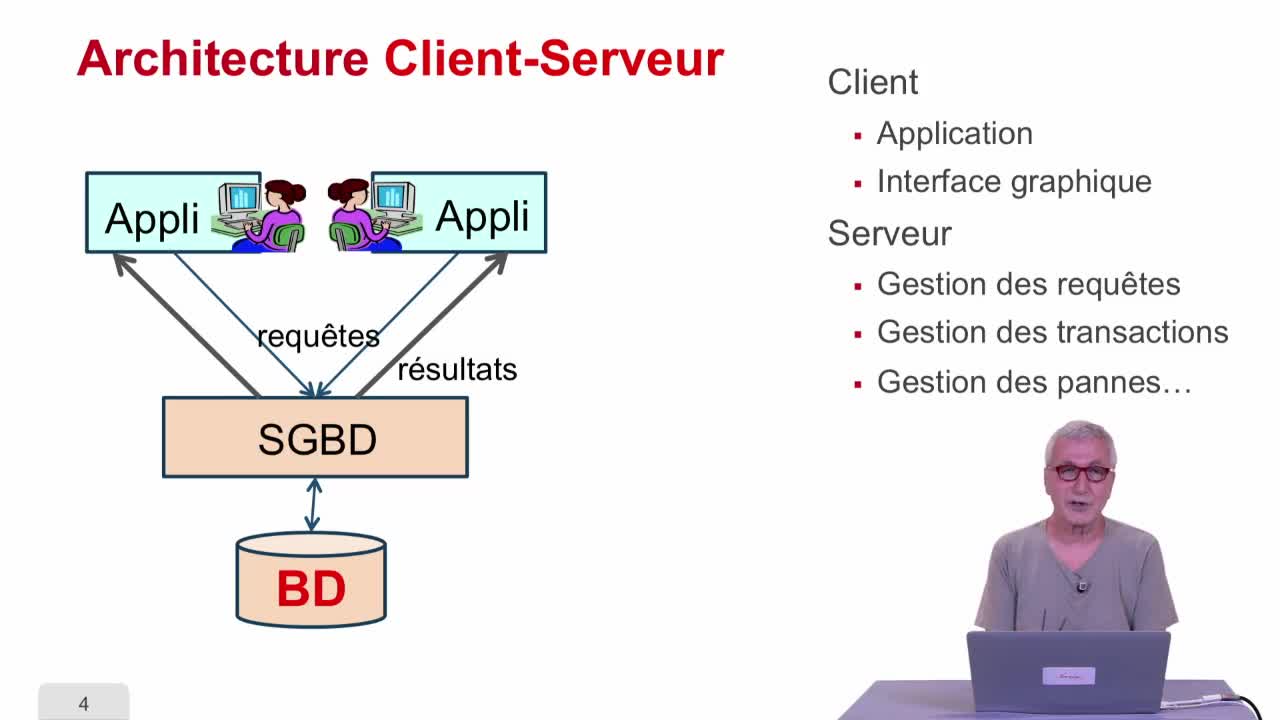
Différentes architectures
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette deuxième séquence, on va considérer différentes sortes d'architectures utilisées pour faire des bases de données distribuées.
-
Optimisation de requête
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette séquence, on va parler d'optimisation de requête, on va montrer comment toutes les techniques d'optimisation de requête qui avaient été développées dans le cas centralisé peuvent être
-
Bases de données distribuées : introduction
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette dernière partie, on va toucher à un sujet particulièrement à la mode, les bases de données distribuées. Vous allez voir qu'on va rencontrer plein de "buzzword". Alors on va parler des
-
Concurrence
AbiteboulSergeNguyenBenjaminRigauxPhilippeOn a vu dans une séquence précédente, comment étendre l'optimisation de requête au cas distribué. Nous allons regarder maintenant comment étendre la concurrence au cas distribué.
-
Fragmentation
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette troisième séquence, on va parler de fragmentation.
-
Réplication
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette cinquième séquence, nous allons étudier la réplication. L'idée à retenir : la raison essentielle à la réplication c'est la fiabilité.





Avec les mêmes intervenants et intervenantes
-
Indexation : introduction
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette deuxième partie du cours "Bases de données relationnelles", nous allons considérer des techniques d'indexation. Dans une première séquence, nous allons regarder des techniques plutôt
-
Réécriture algébrique
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette deuxième séquence, nous allons étudier la manière dont le système va produire, à partir d’une requête SQL, une expression algébrique donnant la manière d’évaluer cette requête, une première
-
Modèle de contrôle d'accès basé sur les rôles (RBAC)
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette troisième séquence, nous allons nous intéresser maintenant au contrôle d'accès basé sur les rôles qui est une évolution du contrôle d'accès discrétionnaire par le fait qu'on a maintenant
-
Différentes architectures
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette deuxième séquence, on va considérer différentes sortes d'architectures utilisées pour faire des bases de données distribuées.
-
Verrouillage à 2 phases
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette séquence, nous allons présenter une deuxième manière d'atteindre la sérialisabilité qui est le verrouillage à deux phases ou "two-phase locking" en anglais noté 2PL. En fait, ce qu'on a vu
-
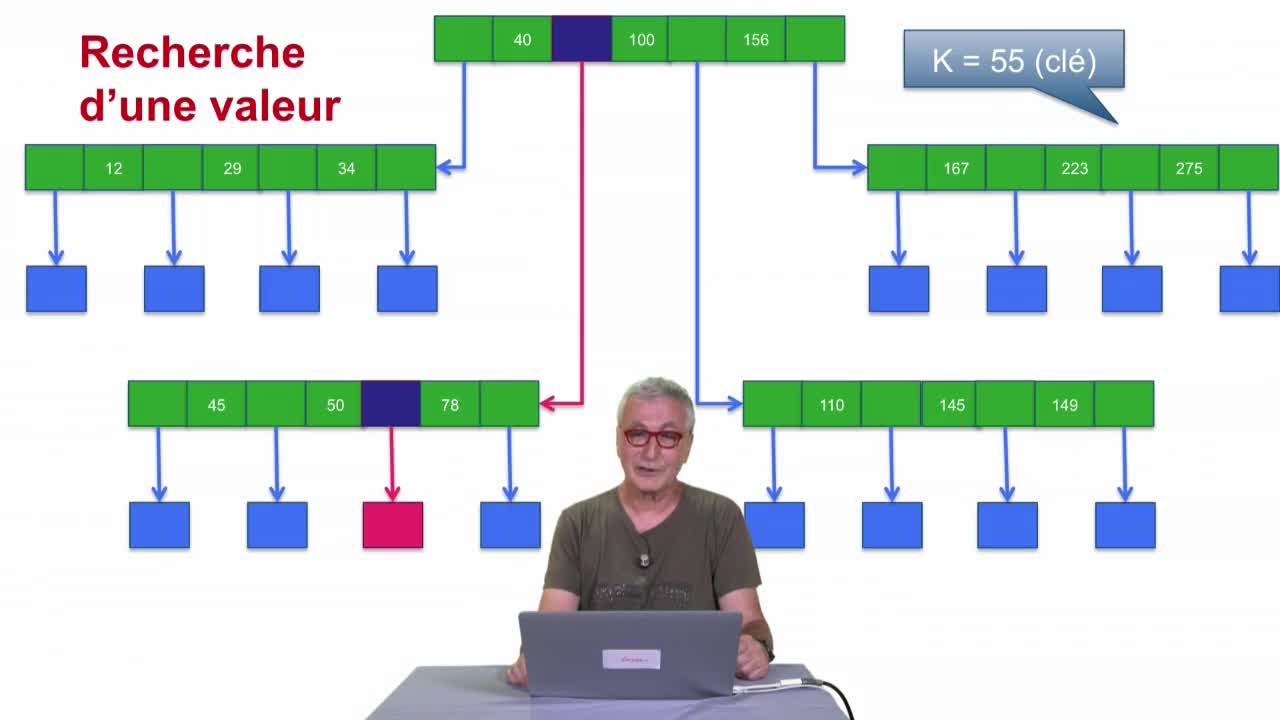
Arbre-B
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette séquence, nous allons parler de l’arbre B dont je vous ai déjà parlé la séquence précédente. Le point de départ est très simple : on a coupé le fichier en blocs et pour certains blocs on a
-
Tri et hachage
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette cinquième séquence, nous allons commencer à étendre notre catalogue d'opérateurs, en examinant deux opérateurs très importants : le tri et le hachage. En fait dans cette séquence, on va
-
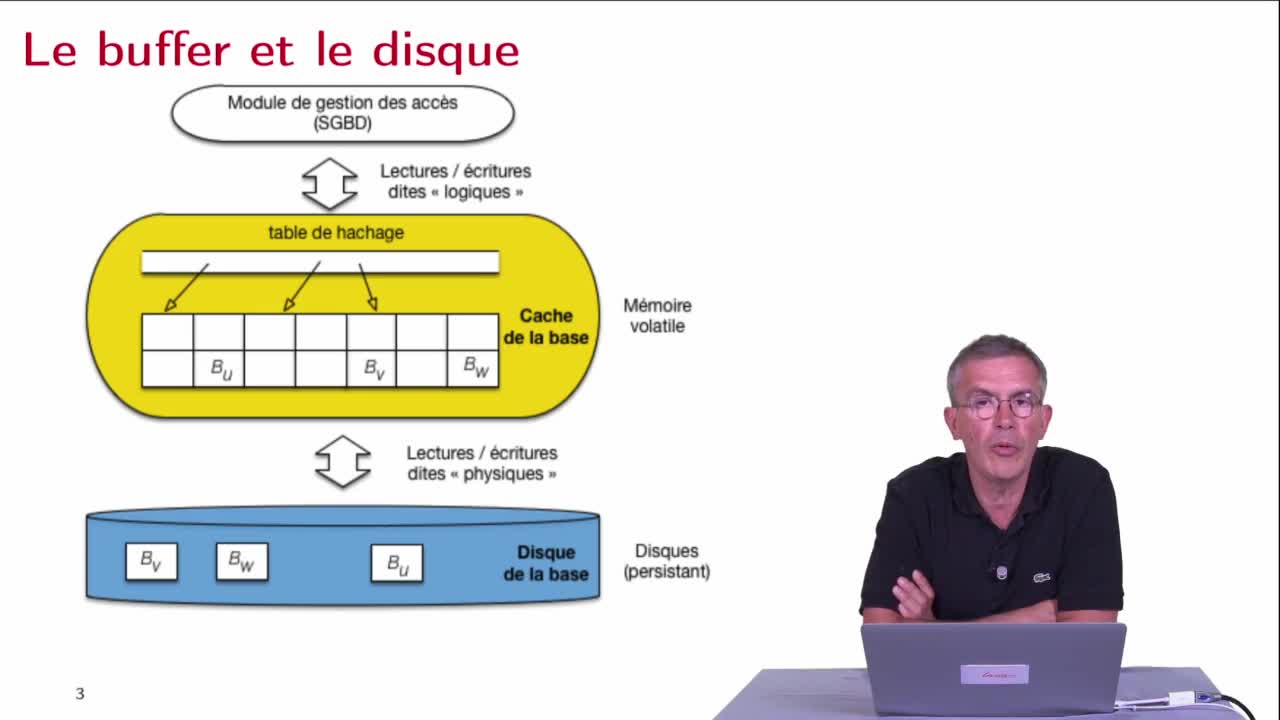
Lectures et écritures, buffer et disque
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette deuxième séquence, pour essayer de bien comprendre ce qu'implique une panne, on va revoir de manière assez détaillée les échanges entre les différents niveaux de mémoire précédemment
-
Réplication
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette cinquième séquence, nous allons étudier la réplication. L'idée à retenir : la raison essentielle à la réplication c'est la fiabilité.
-
Degrés d'isolation dans les SGBD
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette sixième séquence, nous allons nous intéresser au degré d'isolation dans les SGBD c'est-à-dire des manières d'accepter des transgressions sur le concept de serialisabilité en échange d'un
-
Multi-hachage
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette dernière séquence de le deuxième partie, nous allons parler du multi-hachage.
-
Contrôle d'accès : introduction
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette quatrième partie, nous nous intéressons au contrôle d'accès qui est une problématique de sécurité d'accès à l'information. Nous allons commencer dans cette première séquence par présenter