Notice
Pannes de disque
- document 1 document 2 document 3
- niveau 1 niveau 2 niveau 3
Descriptif
Nous allons conclure cette partie 5 en examinant le cas de panne le plus grave qui est la perte d'un disque.
Intervention / Responsable scientifique



Thème
Documentation
Documents pédagogiques
Erratum
Il est indiqué dans la vidéo du cours qu'en cas de panne du disque contenant le log, il suffit d'arrêter proprement le serveur pour récupérer l'état de la base. C'est malheureusement faux: si des mises à jour ont été effectuées sur le disque de la base par des transactions avant leur validation, l'image avant a été écrasée. Dans un tel cas, la règle du write-ahead logging assure que l'image avant est dans le fichier journal, mais la perte de ce dernier entraine sa perte définitive.
L'affirmation faite dans le cours n'est donc valable qu'en cas de mise à jour différée, ce qui n'est pas le plus courant. La perte du disque du log implique en général une reprise depuis la dernière sauvegarde du log. D'où l'intérêt de sauvegarder ce dernier fréquemment ou, mieux, de répliquer le log.
Toutes nos excuses pour cette erreur.
Complément
Vers la très haute disponibilité
La reprise sur panne telle qu’elle est présentée dans le cours permet de s’assurer de l’absence de perte de données, ce qui est déjà beaucoup. En revanche, elle n’assure pas la disponibilité constante du serveur de données puisque ce dernier peut être arrêté pour cause de panne pendant une période allant de quelques secondes (par exemple, relance instantanée du processus serveur après plantage) à quelques heures (par exemple, perte d’un disque suivie d’un remplacement, suivie d’une restauration à partir de la sauvegarde).
De nombreux systèmes applicatifs ne peuvent pas tolérer une telle période d’indisponibilité. C’est le cas par exemple des grands sites de commerce électronique, ou plus généralement des applications dont dépendent de très nombreux utilisateurs (transports, banques, etc.). Il faut dans ce cas développer des méthodes de reprise sur panne pour diminuer le temps de restauration des services et arriver — idéalement — à la garantie d’une disponibilité totale, 24 heures sur 24, 365 jours par an.
Examinons la chaine complète des communications entre un client et les données. On peut imaginer par exemple un navigateur web accédant à une application de commerce électronique, lui-même s’appuyant sur un serveur de données gérant le catalogue, le stock, etc. Cette chaine est résumée sur la figure ci-dessous:

Comment assurer une disponibilité totale de cette chaîne ? Il est clair que la communication entre le client et l’application est hors de notre contrôle. Si le boitier ADSL de l’utilisateur est défaillant, la transaction sera perdue. Nous pouvons envisager d’agir, en revanche, sur la disponibilité de l’application et du serveur de données.
Les solutions de haute disponibilité s’appuient sur la redondance des données et des services. La reprise sur panne telle que nous l’avons exposée en cours s’appuie d’ailleurs également sur ce principe. Pour être capable de pallier immédiatement la défaillance d’un serveur, il faut un serveur de secours ; pour pallier la défaillance d’un disque, il faut un disque de secours.
Le schéma de base est donc celui présenté sur la figure suivante. Le serveur et la base disposent de copies « fantômes », inactives, mais prêtes à prendre le relais en cas de panne. En mode normal, le serveur fantôme se contente de surveiller l’état du serveur principal en échangeant avec lui des messages à intervalles réguliers (mécanisme dit de « heartbeat »). Une copie continue et de préférence synchrone de la base et du journal est effectuée par ailleurs depuis les disques principaux vers les disques fantômes.

Un petit composant complémentaire, le routeur, sert à orienter la connexion des applications. En mode normal, l’adresse fournie par le routeur est celle du serveur principal. En cas de panne de ce dernier, le serveur fantôme va détecter la panne grâce à l’absence de réponse aux messages heartbeat, et prendre immédiatement le relais en demandant au routeur de lui adresser les requêtes. Si la base et le journal sont des copies fidèles de la base initiale, le service peut continuer sans interruption et sans perturbation des applications.
Conceptuellement, c’est simple, mais en pratique c’est bien entendu assez compliqué, et donc... coûteux. Il faut doubler l’infrastructure (deux fois plus de disques, deux fois plus de serveurs). Il est essentiel de répartir ces infrastructures dans deux clouds séparés physiquement, pour éviter la dépendance à de grosses pannes électriques affectant tout un centre de données, des inondations, ou autres catastrophes naturelles. Il faut mettre en place une architecture logicielle assez lourde, avec le personnel, les procédures de contrôle et de test qui vont avec. Il faut enfin assurer la synchronisation des services fantômes et des services principaux grâce à des composants logiciels spécialisés.
Pour les bases de données (qui ne sont qu’un exemple particulier de service dont la disponibilité doit être assurée), la synchronisation des fichiers de base et du journal pose des problèmes spécifiques. Une solution prête à l’emploi est celle des disk arrays, qui assurent des écritures en parallèle sur plusieurs disques. Ces dispositifs permettent de se prémunir contre des pannes fréquentes venant de problèmes matériels sur les disques : il est peu probable que plusieurs disques soient affectés simultanément. En revanche, ils sont peu efficaces contre les événements externes plus exceptionnels, qui demandent d’autres solutions. Certains SGBD proposent une réplication basée sur les écritures dans le fichier journal. Les mises à jour de ce fichier sont transmises vers un disque miroir, ce qui assure une reprise sur panne rapide (mais pas instantanée) avec le serveur fantôme. Enfin, on peut ajouter des composants de réplication synchrone au niveau du système de fichiers lui-même.
Les architectures de haute disponibilité sont étroitement liées aux systèmes de gestion de données distribués. Il est en effet tentant d’utiliser le serveur fantôme pour satisfaire des requêtes au lieu de le confiner à un rôle essentiellement passif. Les systèmes relationnels, dans leur version distribuée, associent clairement les deux problématiques. Une des (rares) caractéristiques commune des systèmes dits « NoSQL » est cette combinaison des fonctionnalités de reprise sur panne et de passage à l’échelle par distribution, au prix de l’abandon de certaines fonctionnalités.
Pour conclure, on notera que le sujet de la haute disponibilité date des débuts de l’informatique. Par exemple, la NASA a fait fortement progresser le domaine dans les années soixante avec le projet Apollo. Il faut aussi noter que les exigences en terme de haute disponibilité dépendent de façon directe de l’application et des coûts induits par une interruption de service. Une panne même de moins d’une minute dans une base de données d’une centrale nucléaire peut avoir des coûts potentiels en vie humaine inacceptables. L’arrêt pendant plusieurs heures du système de paiement d’une entreprise de vente sur Internet peut avoir un coût financier lourd pour l’entreprise. En revanche, la non-disponibilité pendant plusieurs jours de la base de données d’une association locale de protection des grenouilles, si elle peut être gênante pour les membres de l’association, a des conséquences moins sérieuses. La très haute disponibilité coûte cher, on adaptera donc les solutions aux besoins de l’application.
Pour en savoir plus :
Dans la même collection
-
Algorithmes de reprise sur panne
AbiteboulSergeNguyenBenjaminRigauxPhilippeAvec le journal de transactions que nous avons présenté dans la séquence précédente, nous sommes maintenant en mesure d'avoir un algorithme de reprise sur panne qui est tout à fait robuste. Nous
-
Lectures et écritures, buffer et disque
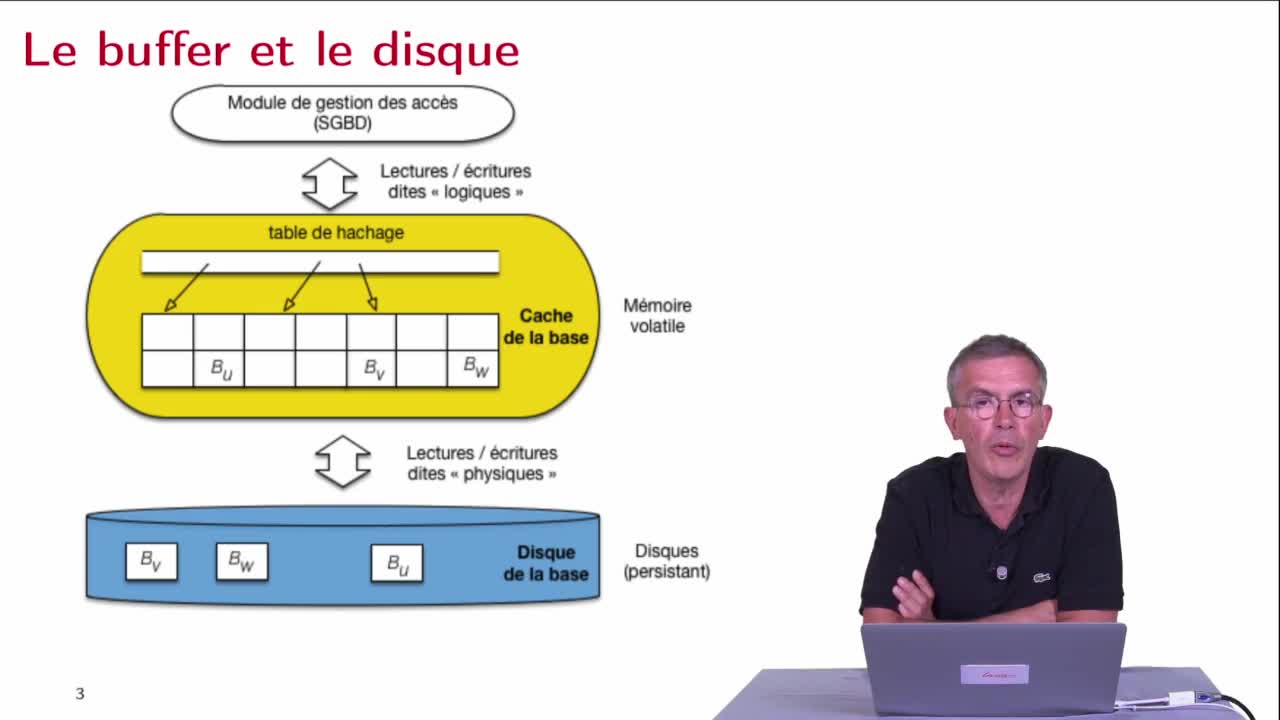
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette deuxième séquence, pour essayer de bien comprendre ce qu'implique une panne, on va revoir de manière assez détaillée les échanges entre les différents niveaux de mémoire précédemment
-
Le journal des transactions
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette séquence, nous allons étudier le mécanisme principal qui assure la reprise sur panne qui est le journal de transactions ou le log.
-
Reprise sur panne : introduction
AbiteboulSergeNguyenBenjaminRigauxPhilippeNous débutons la partie 5 de ce cours qui va être consacré à la reprise sur panne. La reprise sur panne est une fonctionnalité majeure des SGBD, elle est extrêmement apprciable puisqu'elle garantit la
-
Première approche
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette troisième séquence, nous allons regarder comment effectuer la reprise sur panne. Nous savons qu'il nous faut assurer deux garanties : la garantie de durabilité après un commit et la




Avec les mêmes intervenants et intervenantes
-
Présentation du cours de bases de données relationnelles
AbiteboulSergeNguyenBenjaminRigauxPhilippeBienvenue dans ce cours sur les bases de données relationnelles. Le but de cet enseignement est extrêmement simple, on vous veut vous faire comprendre les BDR pour que vous puissiez mieux les
-
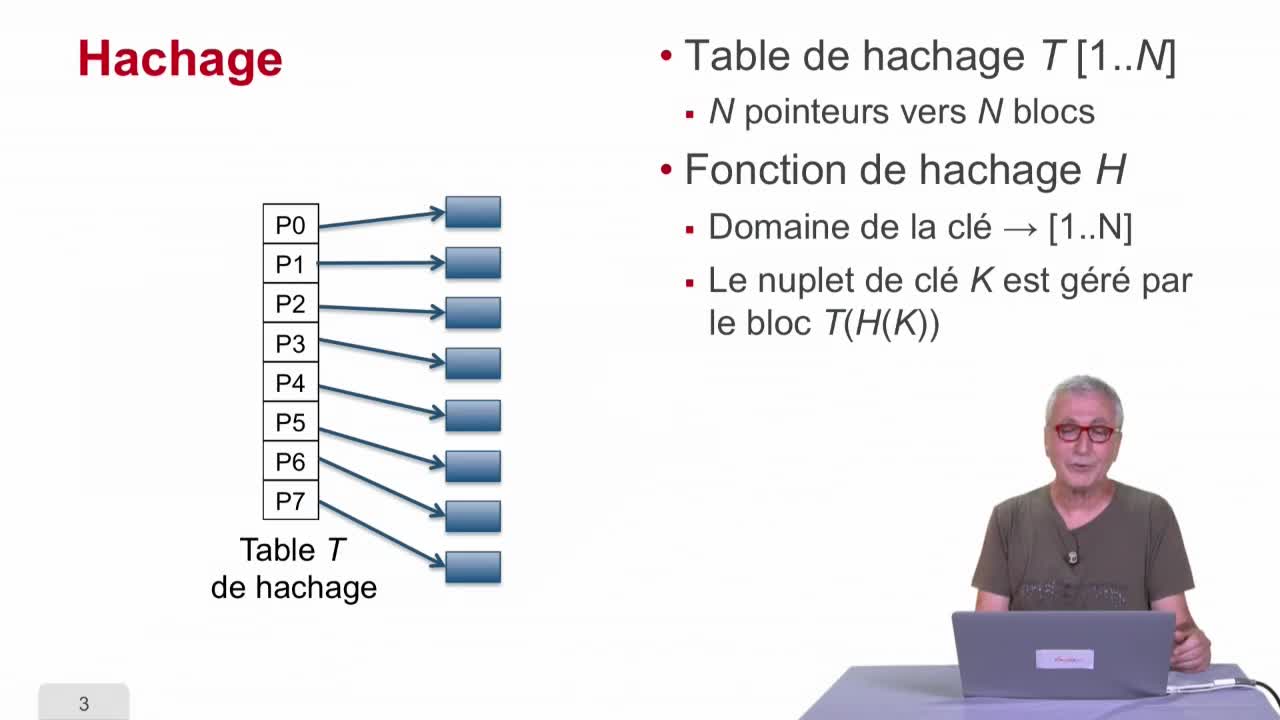
Hachage
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette séquence, nous allons étudier une technique qui s’appelle le hachage, fonction de hachage, qui à mon avis est une des techniques les plus cool de l’informatique.
-
Algorithmes de jointure
AbiteboulSergeNguyenBenjaminRigauxPhilippeNous continuons dans cette séquence 6 notre exploration du catalogue des opérateurs d’un SGBD en examinant un ensemble d’opérateurs très importants, ceux qui vont implanter les algorithmes de jointure
-
Première approche
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette troisième séquence, nous allons regarder comment effectuer la reprise sur panne. Nous savons qu'il nous faut assurer deux garanties : la garantie de durabilité après un commit et la
-
Concurrence
AbiteboulSergeNguyenBenjaminRigauxPhilippeOn a vu dans une séquence précédente, comment étendre l'optimisation de requête au cas distribué. Nous allons regarder maintenant comment étendre la concurrence au cas distribué.
-
Verrouillage hiérarchique
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette dernière séquence de la première partie, nous allons nous intéresser au verrouillage hiérarchique. C'était une autre manière d'améliorer les performances des transactions dans les bases de
-
Exécution et optimisation : introduction
AbiteboulSergeNguyenBenjaminRigauxPhilippeCette partie 3 du cours sera consacrée à l'exécution et à l'optimisation de requêtes. Nous avons vu, dans les semaines précédentes, comment les données étaient organisées physiquement dans des
-
Modèle de contrôle d'accès discrétionnaire (DAC)
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette séquence, nous allons nous intéresser au contrôle d'accès discrétionnaire c'est à dire à la discrétion du propriétaire de l'objet en question. Ce modèle a été définit au début des années 90
-
Bases de données distribuées : introduction
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette dernière partie, on va toucher à un sujet particulièrement à la mode, les bases de données distribuées. Vous allez voir qu'on va rencontrer plein de "buzzword". Alors on va parler des
-
Les problèmes
AbiteboulSergeNguyenBenjaminRigauxPhilippeDans cette deuxième séquence, nous allons discuter des problèmes qui vont apparaitre lorsque de nombreuses transactions sont mises en concurrence. En effet, dans le cas général une base de données n
-
Fichiers indexés
AbiteboulSergeNguyenBenjaminRigauxPhilippeDance cette séquence, nous allons parler de fichiers indexés. C’est une structure de données qui est utilisée essentiellement pour accélérer l’accès à l’information.
-
Plans d'exécution
AbiteboulSergeNguyenBenjaminRigauxPhilippeNous avons vu dans la séquence précédente, les opérateurs qui sont des composants de base avec lesquels nous allons construire nos programmes d’évaluation de requêtes. Dans cette quatrième séquence,