Notice
4. Linked Data Principles
- document 1 document 2 document 3
- niveau 1 niveau 2 niveau 3
Descriptif
In this fourth part, we're going to see the principles behind Linked Data.
What we're going to do is to change slightly how we use the Web architecture. The principles say we're going to use HTTP URIs to allow dereferencing the address for naming everything around us. For instance, if I gave a URI to my necktie, I will use an HTTP URI for that, so that if you find that URI, you can call that URI to get data and discover what it is about. Then when a URI is accessed, we provide data about the resource it represents, for instance we provide data about the necktie. Finally, in the data we provide as many links as possible to other data on the Web, for instance to my suit...
Intervention / Responsable scientifique



Thème
Documentation
Documents pédagogiques
Discover who rents a domain name
The Web application below allows you to provide a domain name to see who controls this domain and to which machine calls to this address are routed. Here for instance we called that service on the domain name “dbpedia.org”
https://who.is/whois/dbpedia.org
Choosing a scheme for your URIs
An HTTP URI is a URI created to name anything we want to talk about
but that uses the HTTP in order to be “dereferenceable” i.e. so that a
person or a software finding that URI (e.g. a Web crawler)
may easily learn more about the resource represented by that URI by
just making and HTTP call to the HTTP address it provides. We don’t use
the term URL (locator) because the thing that is being represented may
not be itself on the Web at this address.
For example, I may want to
give an HTTP URI to Mytsie (my cat). No matter how hard I try, Mytsie
itself will never be “located” on the Web (it is a not a URL) but this
adorable cat can be identified on the Web by an HTTP URI and if you ever
go to that address you will be provided with a description on the Web
about the resource represented by that URI, i.e. my cat.
Now, how
do we choose the URIs we are going to use to talk about the things we
want to describe? What should be their structure or schema?
The generic form of a URI is
scheme:[//[user:password@]host[:port]][/]path[?query][#fragment]
For classical HTTP URIs we will have a schema of the form:
http://host[:port]][/]path[?query][#fragment]
We already mentioned the importance of choosing well the domain name for the host par of the identifier. But what about the rest of the address?
There is no unique correct answer to that question and here are two documents that discuss the different options with pros and cons. As you will see the answer is neither simple nor closed:
- Cool URIS: http://www.w3.org/TR/cooluris/
- Issue 57: http://www.w3.org/2001/tag/awwsw/issue57/latest/
In
many cases, the objects we want to describe already have some kind of
identifier. In theory, you can transform any identifier into an HTTP
URI, for instance, just by choosing a transformation (URI scheme) of the
form
http:///
For example, if I want to identify cats, I could choose the following minting scheme:
cat;1278 → http://animals.org/cat/1278
Then HTTP content negotiation (conneg)
and, possibly, redirections are configured on the server to provide
content in XML, RDF, HTML, JSON, etc. to whoever accesses that address.
Of
course, depending on the type of identifier you initially had, you may
need to use the URI encoding mechanism we introduced before.
To illustrate that first step, we can mention the real example of the digital object identifier (DOI). There is a way to lookup any DOI on the Web through a service implementing a mapping from DOIs to HTTP URIs.
If you take the following DOI for instance:
You can transform it into the following HTTP URI following the URI minting scheme implemented by doi.org:
http://dx.doi.org/10.1007/3-540-45741-0_18
This HTTP URI will then redirect you to a description of the object identify by the DOI.
So, choosing the URIs will strongly depend on the domain to which the objects you want to describe belong.
However, there are two families of HTTP URIs that can be considered every time you want to choose a naming scheme: the “hash URIs” (long story) and the “slash URIs” and the discussion they led to.
When a URI contains a hash (i.e. the symbol # ), this indicates a fragment in the URI:
The HTTP standard requires the Web client to remove the fragment before making a request so if you make an HTTP call on this URI it will in fact be performed on the address:
http://my.domain.name/my/pathThe use of a fragment has two advantages:
- To immediately differentiate, for instance, the name (URL) of a file on the Web containing descriptions and the names (URIs with fragments) of the resources it describes;
- The grouping of several descriptions in one file that can be cached and avoid several calls to discover different linked resources.
For example, in one source at the address:
http://fabien.gandon.me/my/objects/carsI can describe several things:
http://fabien.gandon.me/my/objects/cars#bmw1http://fabien.gandon.me/my/objects/cars#smart1http://fabien.gandon.me/my/objects/cars#tesla1…
It
has "the disadvantages of its advantages ": one cannot obtain the
description of only one resource since the whole document is retrieved
every time the address is accessed and this could be costly in terms of
network traffic, memory and processing when the file is large.
The alternative is to use only the path with slashes (i.e. the symbol / ) to generate identifiers. For instance:
In that case the server needs to implement a redirection to respond to these addresses with an HTTP 303 error code "See Other". This is to indicate that this URI identifies a resource that is not directly available on the Web and to redirect the requester to another URL where a description about that resource is available. A server should not answer directly (HTTP 200 OK) because it would mean the object (the car for instance here) is available on the Web and it can be retrieved through HTTP which is not true. So the server should redirect ( HTTP 303 error code "See Other") the requester to another address where to find data about the object (the car in our example). Again the content negotiation is used to redirect the requester to a URL corresponding to the requested content format. For instance in HTML:
http://fabien.gandon.me/my/objects/cars/bmw1.htmlor in XML:
http://fabien.gandon.me/my/objects/cars/bmw1.xmlThis alternative, using slashes, allows us to be much more modular in the storage and transfer of descriptions. Here, a Web client can retrieve only the description it is interested in.
Disadvantages include
the multiplication (by two) of HTTP calls (the first access and the
second one after the redirection) and the fragmentation of the data that
requires multiple calls when one wants to retrieve a collection of
them.
To summarize, fragments can be used for small datasets
where grouping makes sense (unity of content, linked, same life cycle).
This option is also the simplest one as it can be implemented, for
instance, just by hosting a file on a Web server. The redirection by
HTTP 303 is more technical but allows more control over the data served.
Finally, nothing prevents you from using and mixing these two options
even inside the same dataset.
FREE BOOK ONLINE
Tom
Heath and Christian Bizer (2011) Linked Data: Evolving the Web into a
Global Data Space (1st edition). Synthesis Lectures on the Semantic Web:
Theory and Technology, 1:1, 1-136. Morgan & Claypool. http://linkeddatabook.com/
To go further...
- The Web site "Linking Open Data cloud diagram" provides an overview of the linked open data cloud on the Web.
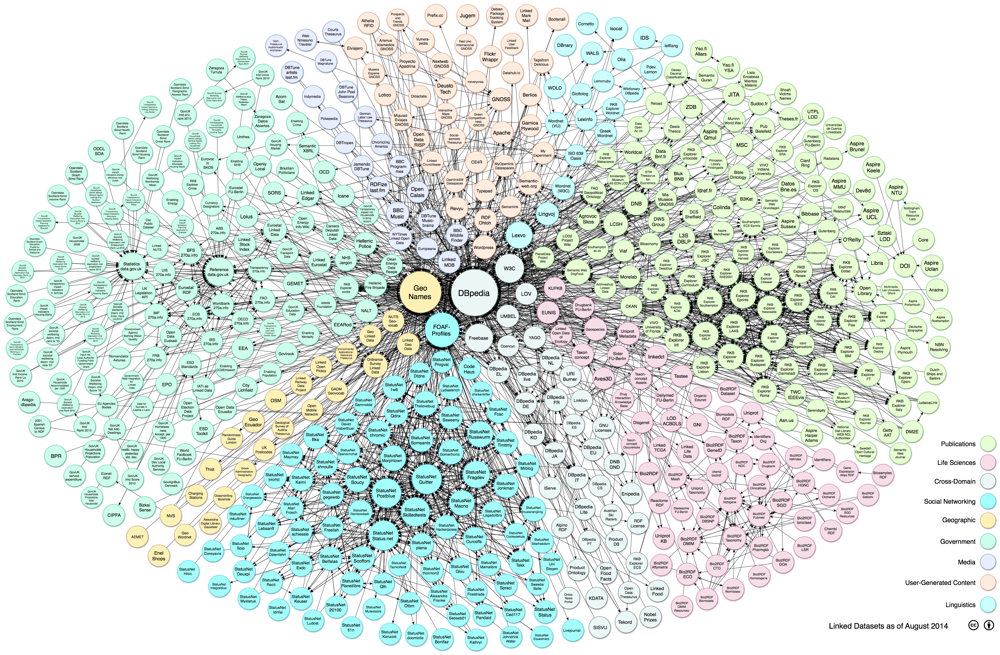
- LODStats based on the CKAN dataset metadata registry to obtain a comprehensive picture of the current state of the Data Web
- The free HTML version of the book by Tom Heath & Christian Bizer (2011) "Linked Data: Evolving the Web into a Global Data Space". Synthesis Lectures on the Semantic Web: Theory and Technology, 1:1, 1-136. Morgan & Claypool.

- The initial document about Linked Data by Tim Berners-Lee, Design Issues, W3C, 2006

- Data on the Web Best Practices, W3C Recommendation 31 January 2017:
best practices for publication and usage of data on the Web to
facilitate interaction between publishers and consumers. This document
from 2017 also shows the evolution of W3C activity to facilitate data on
the Web in general: https://www.w3.org/TR/dwbp/
Dans la même collection
-
1. Historical Introduction to the Web Architecture
GandonFabienFaronCatherineCorbyOlivierGoing back in history, back in 1945, Vannevar Bush wrote an article entitled "As we may think". In this article, he
-
3. From pages to resources
GandonFabienFaronCatherineCorbyOlivierIn this third part, we will see another evolution of the Web, or more precisely, an evolution of the way we use the Web. We will
-
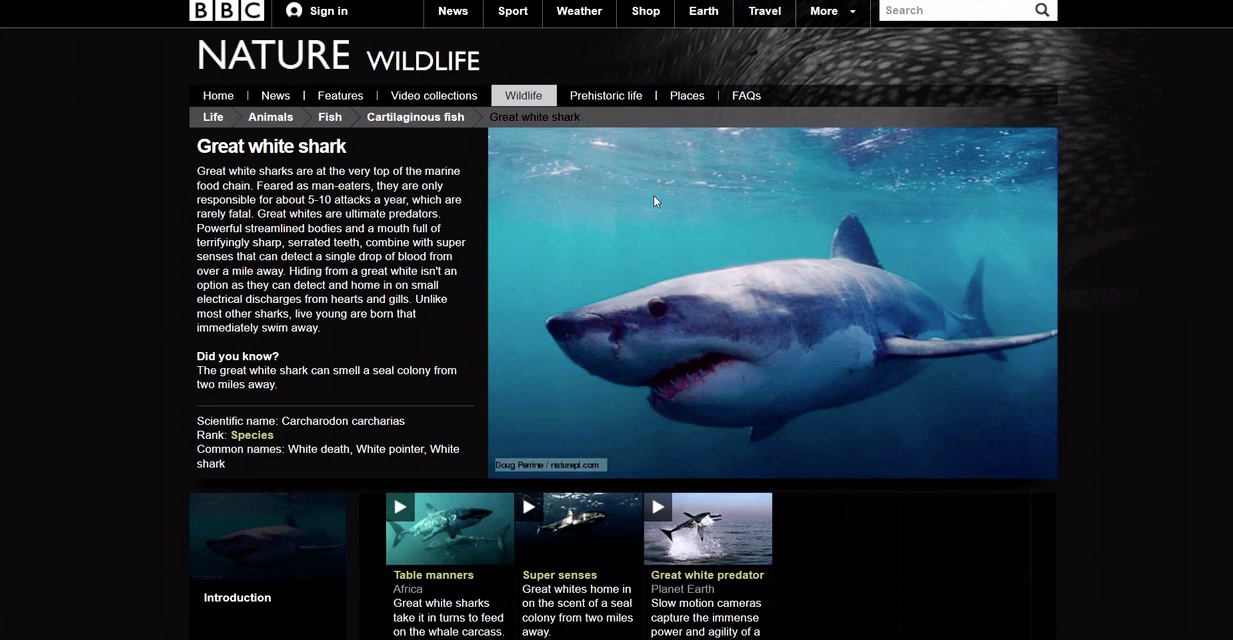
Demos about a Web of Linked data
GandonFabienFaronCatherineCorbyOlivierThe BBC Web site uses linked (open) data The Wildlife documentary catalog on the Web site of BBC The Web site of BBC is structured and augmented with both internal and public linked data. In
-
2. Separating Presentation and Content
GandonFabienFaronCatherineCorbyOlivierWe now consider one of the first evolutions of the web, to separate the presentation and the content. In 1996, CSS, standing for
-
5. Stack of Standards and Languages
GandonFabienFaronCatherineCorbyOlivierLet us now conclude this first part with an overview of the stack of standards and languages that are used to publish data on the



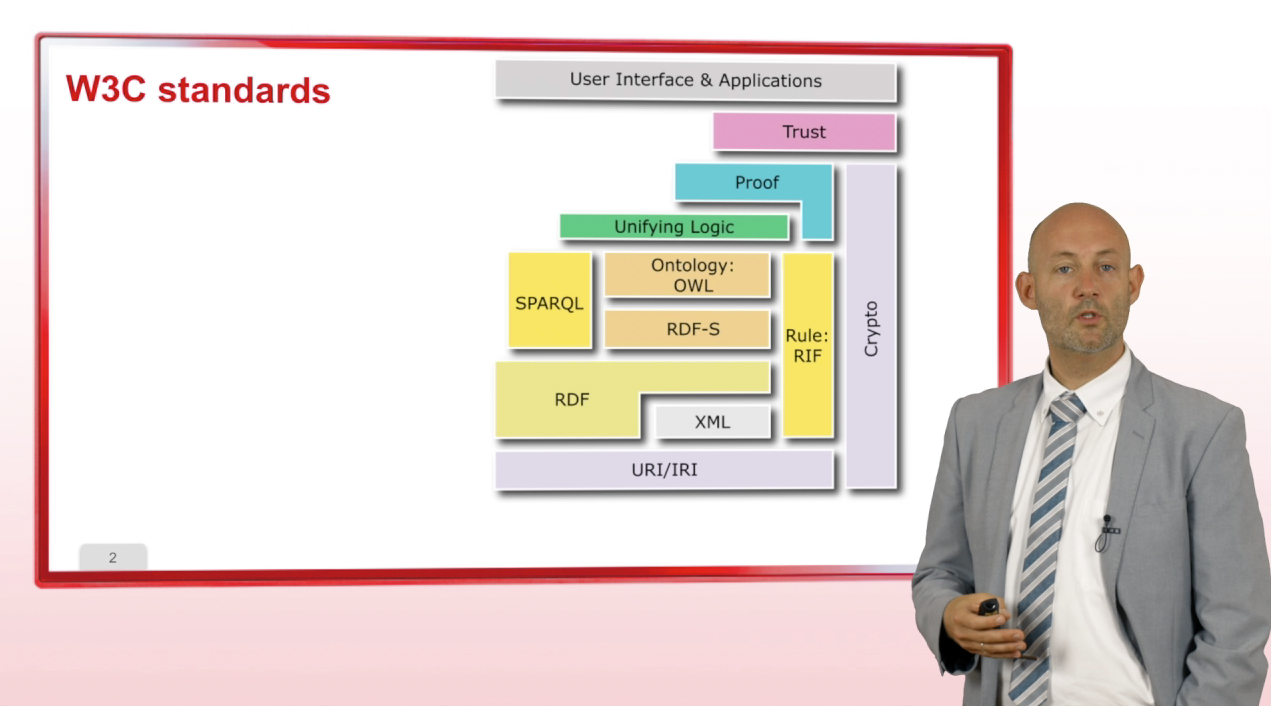
Avec les mêmes intervenants et intervenantes
-
3. Serialization Syntaxes
GandonFabienFaronCatherineCorbyOlivierWe saw in the previous sequence the principles of the RDF model by using an abstract syntax. This sequence will present you the
-
6. Results and Update
GandonFabienFaronCatherineCorbyOlivierIn the last part, we will see the result format and Update query. The format of SPARQL query results are also standardized by the
-
Demos about Integration with Other Data Formats and Sources
GandonFabienFaronCatherineCorbyOlivierAugmenting Web browser with data in the pages This demonstration show an extension to the browser called Operator. This extension allows the browser to actually look at the data inside the page
-
1. RDF Graph Pattern Matching
GandonFabienFaronCatherineCorbyOlivierThis third part presents the SPARQL (pronounced sparkle) Query Language that enables users to query RDF triple stores. The SPARQL query language enables us to access data
-
2. Separating Presentation and Content
GandonFabienFaronCatherineCorbyOlivierWe now consider one of the first evolutions of the web, to separate the presentation and the content. In 1996, CSS, standing for
-
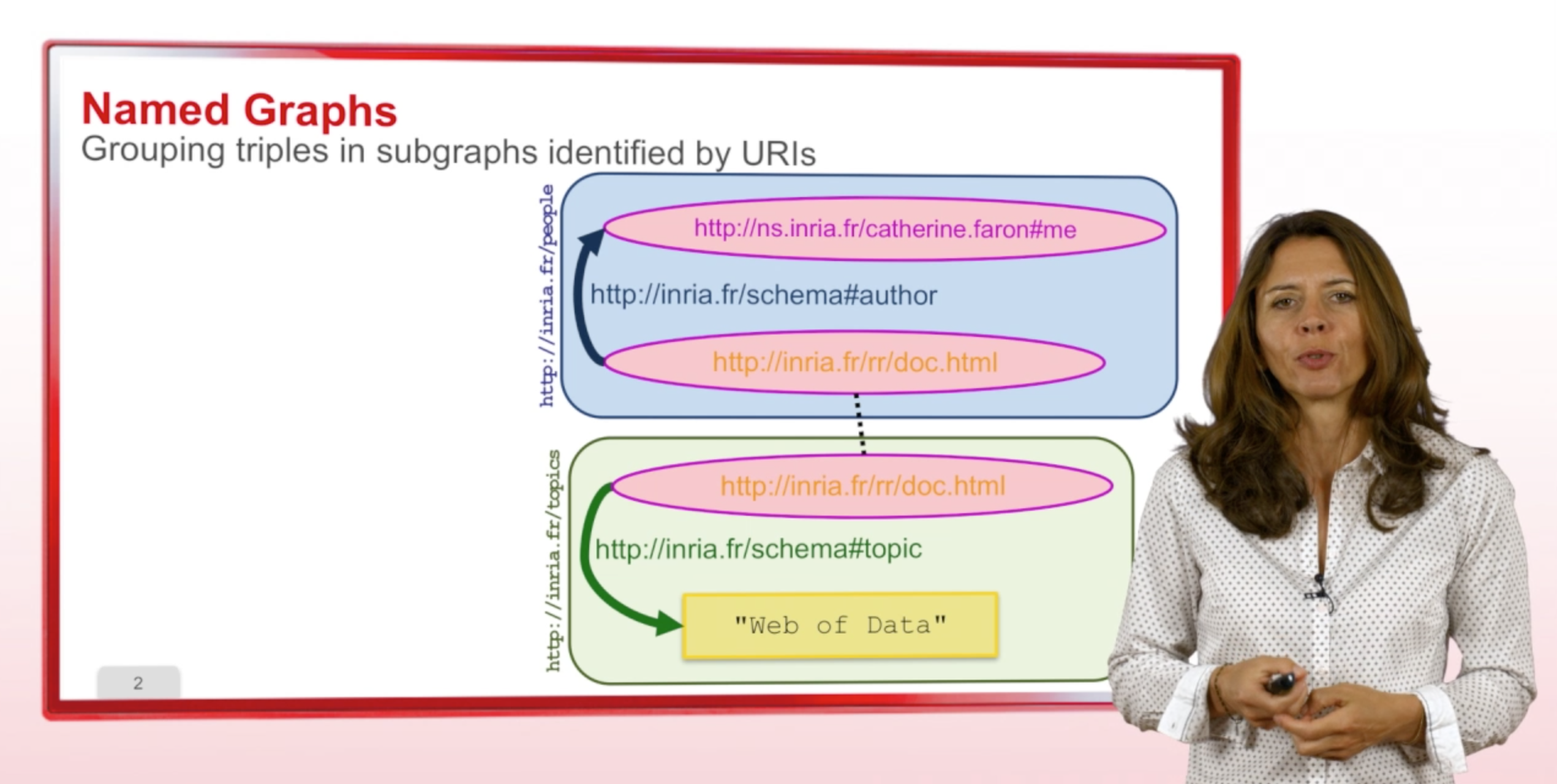
6.Naming graphs
GandonFabienFaronCatherineCorbyOlivierThis sequence explain how to name graphs in the RDF model and what is the utility of it. In many applications it is very useful to be
-
1. RDFa: an RDF syntax inside HTML
GandonFabienFaronCatherineCorbyOlivierThe idea of the integration of the web of linked data with other data formats and sources is determined by the fact that the Web is evolving towards all forms of
-
1. Describing resources
GandonFabienFaronCatherineCorbyOlivierIn this second part we will focus on RDF. RDF is the first brick of the Semantic Web Standards Stack and comprises both a model and several serialization syntaxes, to publish data about anything on
-
3.Filter, Constraint and Function
GandonFabienFaronCatherineCorbyOlivierIn the third part, we will see the filters, constraints and functions. It is possible to filter the results of query using
-
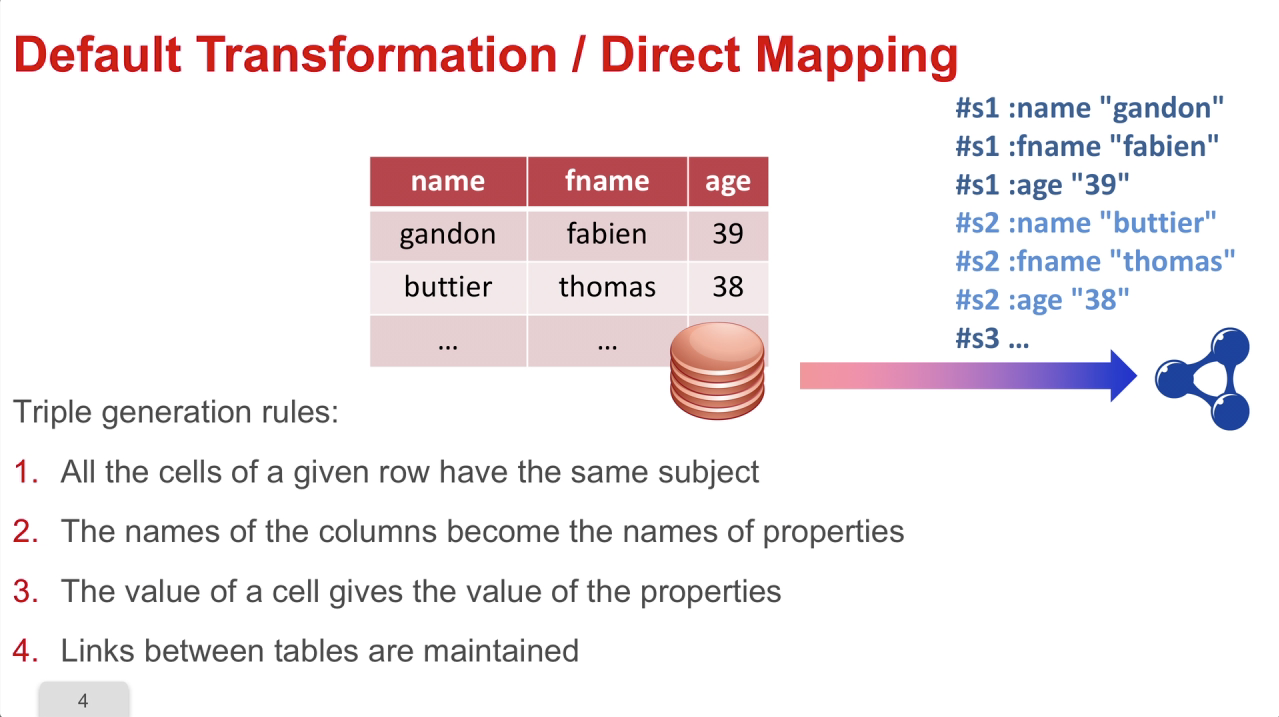
5. R2RML: integration with databases
GandonFabienFaronCatherineCorbyOlivierR2RML allows us to integrate data from databases into RDF. There are two ways of transforming a relational database into RDF using R2RML.
-
4. Values, Types and Languages
GandonFabienFaronCatherineCorbyOlivierThis sequence is about the specificities of the RDF model related to typing literal values and resources in an RDF graph and indicating the
-
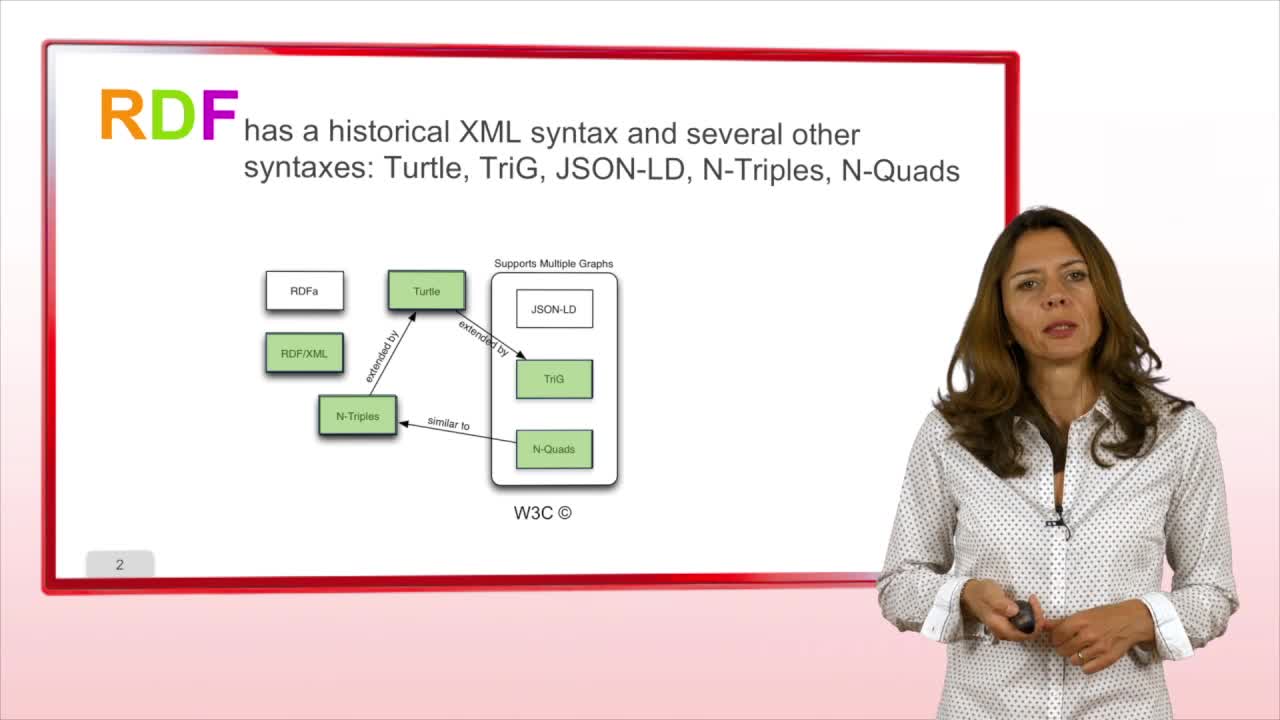
Demos about SPARQL
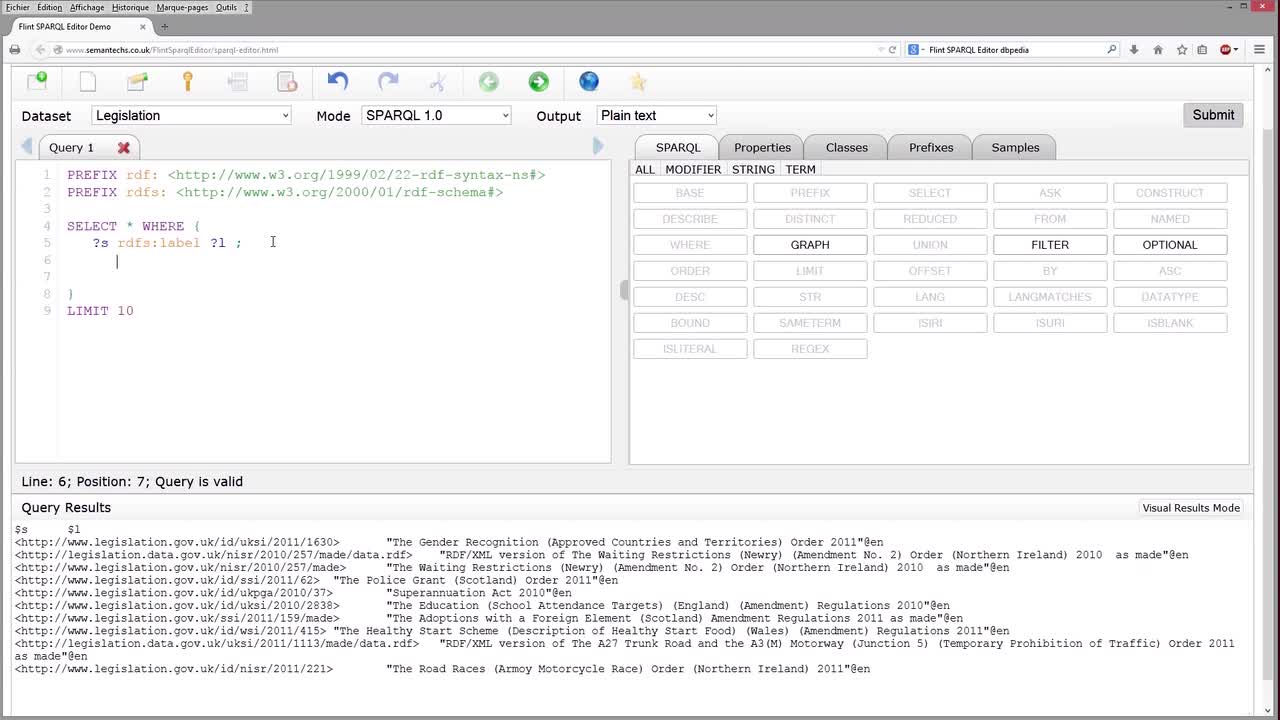
GandonFabienFaronCatherineCorbyOlivierFlint, a SPARQL Query Editor Editors are now available for SPARQL. We present the Flint structured editor which provides syntactic coloration. The editor proposes SPARQL keywords according to the






Sur le même thème
-
Participation et citoyenneté en régime numérique : vers de nouvelles dynamiques de recherche ? Vidé…
BoutéÉdouardMabiClémentLupoviciRaphaëlMichelLouiseDilé-ToustouJulesAubertRomainMobilisées en politique depuis plusieurs décennies (Vedel, 2006), les technologies de l’information et de la communication numérique (TICN), et notamment internet et le web connaissent au tournant des
-
Participation et citoyenneté en régime numérique : vers de nouvelles dynamiques de recherche ? Vide…
BoutéÉdouardDespontin LefèvreIrèneMabiClémentLupoviciRaphaëlMichelLouiseMobilisées en politique depuis plusieurs décennies (Vedel, 2006), les technologies de l’information et de la communication numérique (TICN), et notamment internet et le web connaissent au tournant des
-
L'art contemporain en temps de confinement
GirelSylviaLe 14 mars 2020 tous les lieux d’exposition sont sommés par décret de fermer leurs portes. L’art contemporain n’y échappe pas et comme la majorité des secteurs d’activités en France ce sera plusieurs
-
Controverses et médiatisation autour du halal
RigoniIsabelleSéance : Controverses et médiatisation " Vous avez dit halal ? " Normativités islamiques, mondialisation et sécularisation Colloque international, 7-8 novembre 2013, IISMM-EHESS, Salle Claude Lévi
-
Contourner la frontière par la toile. La fabrique d’un territoire communautaire par les nouvelles t…
MerzaEleonorePalestiniens et Israéliens deux décennies après Oslo : anatomie, vécus et mouvements d'une séparation Colloque du 17, 18 et 19 Février 2011, Maison méditerranéenne des sciences de l'homme, Aix-en
-
-
-
[COLLOQUE] FrenchTech Grande Provence and LIAvignon : L’IA de demain 2em partie
L’IA doit être éthique mais peut-elle être bienveillante ?
-
[COLLOQUE] Festival de l’intelligence artificielle Avignon 2021 table ronde 2
FESTIVAL de L’intelligence Artificielle le 18 et 19 Novembre 2021
-
[COLLOQUE] FrenchTech Grande Provence and LIAvignon : L’IA de demain
FESTIVAL de L’intelligence Artificielle le 18 et 19 Novembre2021
-
[COLLOQUE] Festival de l’intelligence artificielle Avignon 2021 table ronde 1
FESTIVAL de L’intelligence Artificielle le 18 et 19 Novembre 2021
-
[COLLOQUE] Festival de l’intelligence artificielle Avignon 2021 - Les assistants personnels vocaux,…
FESTIVAL de L’intelligence Artificielle le 18 et 19 Novembre 2021. Table ronde 3. Les assistants personnels vocaux, généralistes ou spécifiques ? Jusqu’où personnaliser les services ?






![[COLLOQUE] Festival de l’intelligence artificielle Avignon 2021 Présentation de La chaire LIA Avignon](https://vod.canal-u.tv/videos/media/images/universite_d_avignon_et_des_pays_de_vaucluse/.colloque.festival.de.l.intelligence.artificielle.avignon.2021.presentation.de.la.chaire.lia.avignon_64811/vignette.jpg)
![[COLLOQUE] FrenchTech Grande Provence & LIAvignon : L’IA de demain 2em partie](https://vod.canal-u.tv/videos/media/images/universite_d_avignon_et_des_pays_de_vaucluse/.colloque.frenchtech.grande.provence.liavignon.l.ia.de.demain.2em.partie_64819/vignette.jpg)
![[COLLOQUE] Festival de l’intelligence artificielle Avignon 2021 table ronde 2](https://vod.canal-u.tv/videos/media/images/universite_d_avignon_et_des_pays_de_vaucluse/.colloque.festival.de.l.intelligence.artificielle.avignon.2021.table.ronde.2_64807/vignette.jpg)
![[COLLOQUE] FrenchTech Grande Provence & LIAvignon : L’IA de demain](https://vod.canal-u.tv/videos/media/images/universite_d_avignon_et_des_pays_de_vaucluse/.colloque.frenchtech.grande.provence.liavignon.l.ia.de.demain_64813/vignette.jpg)
![[COLLOQUE] Festival de l’intelligence artificielle Avignon 2021 table ronde 1](https://vod.canal-u.tv/videos/media/images/universite_d_avignon_et_des_pays_de_vaucluse/.colloque.festival.de.l.intelligence.artificielle.avignon.2021_64135/vignette.jpg)
![[COLLOQUE] Festival de l’intelligence artificielle Avignon 2021 table ronde 3](https://vod.canal-u.tv/videos/media/images/universite_d_avignon_et_des_pays_de_vaucluse/.colloque.festival.de.l.intelligence.artificielle.avignon.2021.table.ronde.3_64809/vignette.jpg)