Notice
Extraction automatique de termes traduits et enregistrés dans des langues (gallo-)romanes : focus sur les parlers du Croissant
- document 1 document 2 document 3
- niveau 1 niveau 2 niveau 3
Descriptif
Le traitement automatique de données audio collectées dans des variétés de langues peu dotées, n’est pas aisé. En témoigne la tâche consistant à extraire des paradigmes verbaux à partir de listes de conjugaisons enregistrées in situ, dans plusieurs parlers du Croissant. Nous partirons du travail que nous avons mené, poursuivant cet objectif (Knyazeva et al. 2020), pour l’étendre à un travail plus large de cartographie linguistique. Cherchant à économiser l’effort des linguistes, la difficulté est que les algorithmes d’apprentissage automatique en vogue depuis quelques années nécessitent des quantités de données dont nous ne disposons pas pour les langues minoritaires.
Nous décrirons, dans cette communication, une méthode d’extraction (semi-)automatique de mots à partir d’une même fable d’Ésope (« La bise et le soleil ») traduite en dialectes romans de France, notamment dans le Croissant. La première tâche consistait à déterminer comment une douzaine de mots tels que « bise » ou « soleil » avaient été traduits dans près de 200 versions recueillies sur le terrain— tirant parti de la similitude orthographique, du contexte et de la position des mots. Des occurrences des mots traduits ont ensuite été extraites des enregistrements alignés en phonèmes. Les résultats ont été jugés corrects dans 96–97 % des cas, à la fois sur le corpus de développement et sur un ensemble de tests de données non-vues. Les alignements corrigés ont enfin été cartographiés et des fonds de carte ont été dessinés, avec différents codes couleurs, pour rendre immédiatement visibles divers phénomènes linguistiques. Nous illustrerons comment des expressions régulières peuvent être utilisées à cette fin. Le résultat final, qui prend la forme d’un atlas sonore en ligne (enrichissant le site https://atlas.limsi.fr (Boula de Mareüil et al. 2017)), permet d’illustrer la variation lexicale, morphologique et phonétique.
Références
Knyazeva, Elena, Gilles Adda, Philippe Boula de Mareüil, Maximilien Guérin, Nicolas Quint. 2020. Automatic Extraction of Verb Paradigms in Regional Languages: the case of the Linguistic Crescent varieties, 1st Joint Workshop on Spoken Language Technologies for Under-resourced languages (SLTU) and Collaboration and Computing for Under-Resourced Languages (CCURL), Marseille. 245-249. Boula de Mareüil, Philippe, Frédéric Vernier, Albert Rilliard. 2017. Enregistrements et transcriptions pour un atlas sonore des langues régionales de France. Géolinguistique 17. 23–48.
Thème
Dans la même collection
-
Les langues régionales en Nouvelle-Aquitaine
Jean-Luc Armand (Région Nouvelle-Aquitaine) Les langues régionales en Nouvelle-Aquitaine
-
À la recherche de la limite orientale des parlers poitevin-saintongeais, aux confins des parlers be…
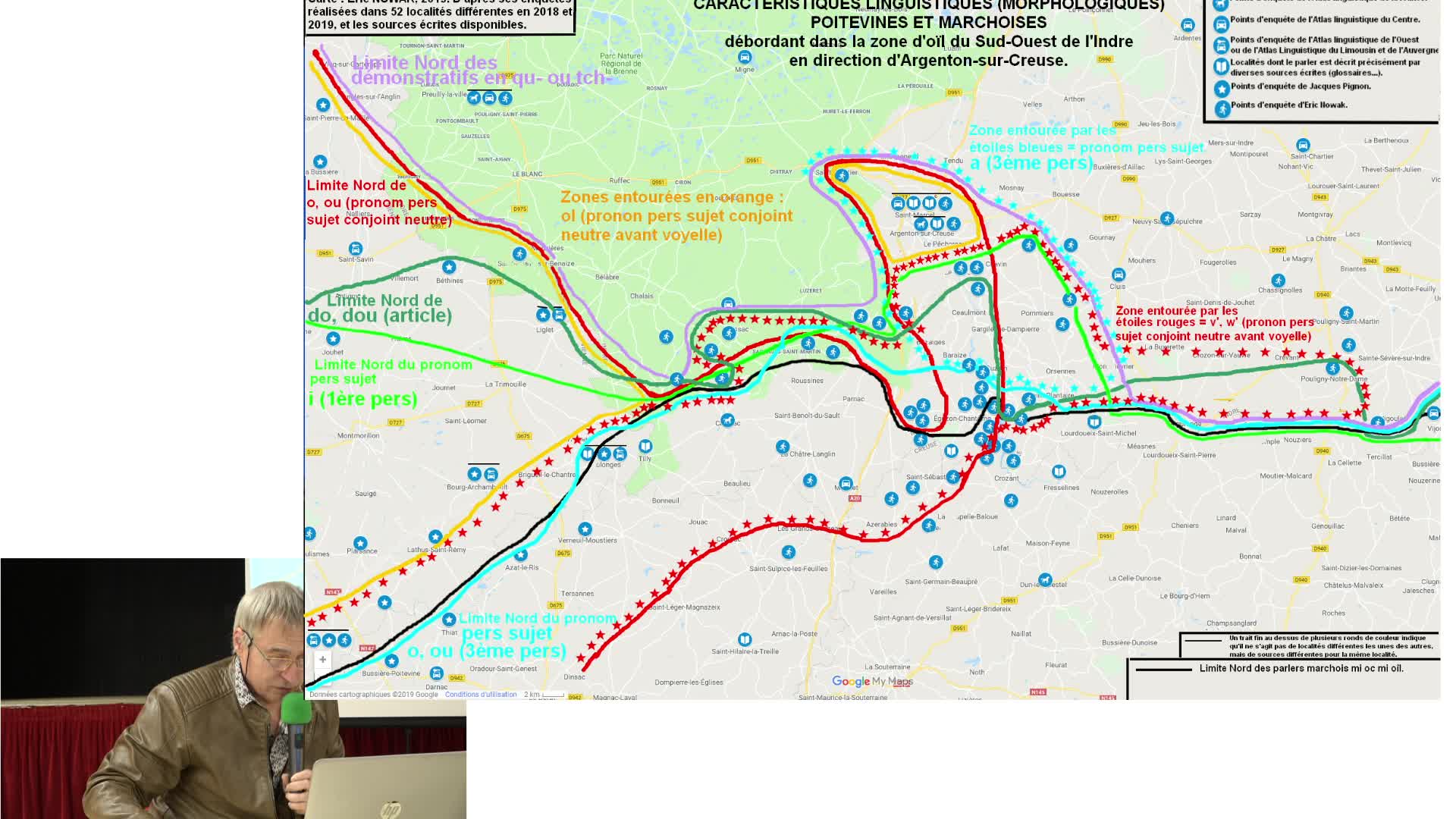
Dans l’Est et le centre du domaine marchois (ouest de l’Allier, Est de l’Indre), la limite entre les parlers berrichons (d’oïl) et les parlers marchois (pour dire vite : mi oc mi oïl) est constituée
-
Le Petit Prince dans l’Encrier
Dans notre intervention, nous ferons le point sur l’évolution de notre maison d’édition depuis ses débuts, en mettant l’accent sur les éditions du Petit Prince dans les parlers du Croissant.
-
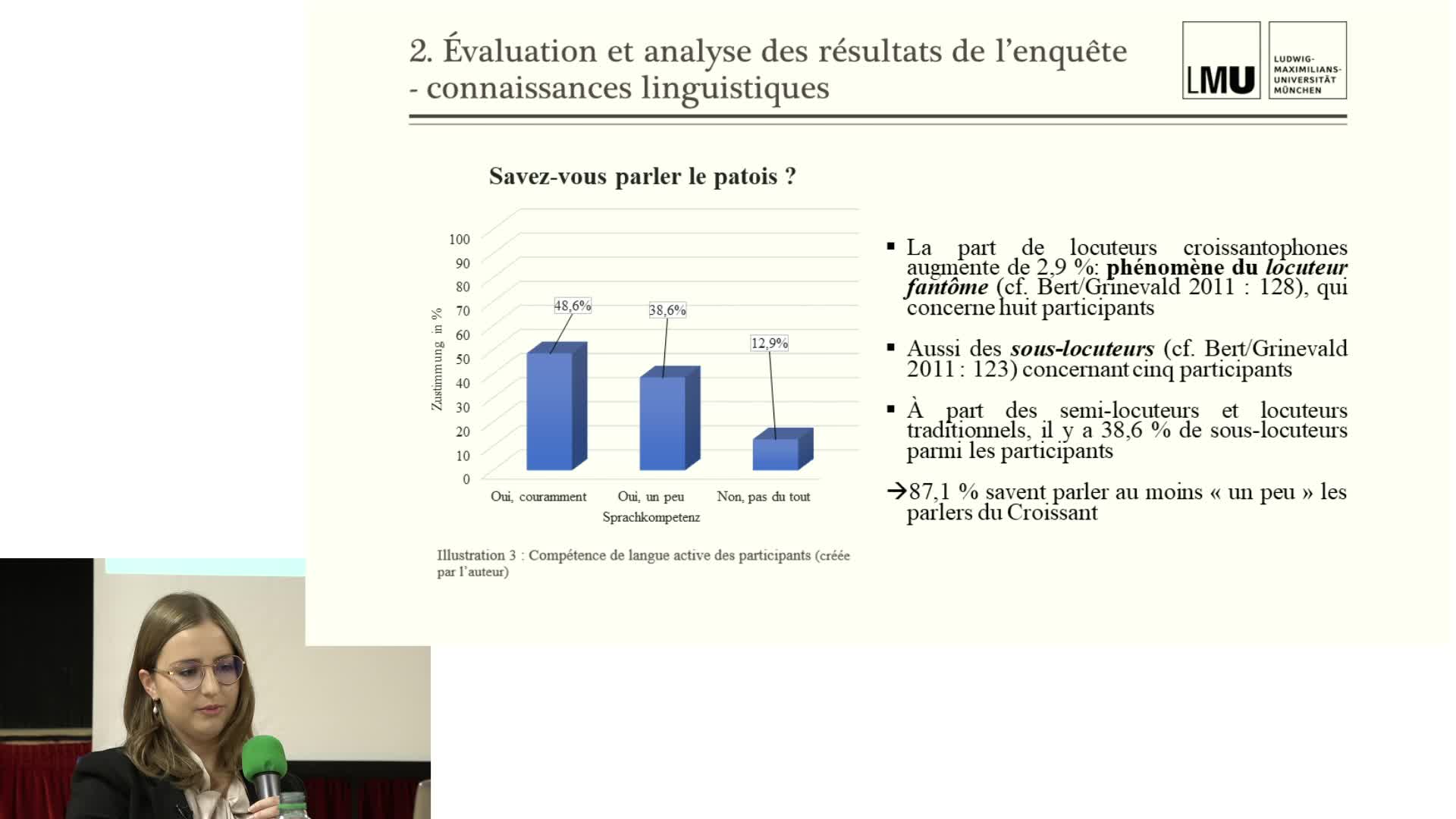
Entre langue d’oc, langues d’oïl, marginalisation et redécouverte : une enquête sociolinguistique d…
Cette communication a pour but de présenter, d’analyser et de discuter les résultats de l’enquête sociolinguistique que j’ai effectuée dans le cadre de mon mémoire de licence.
-
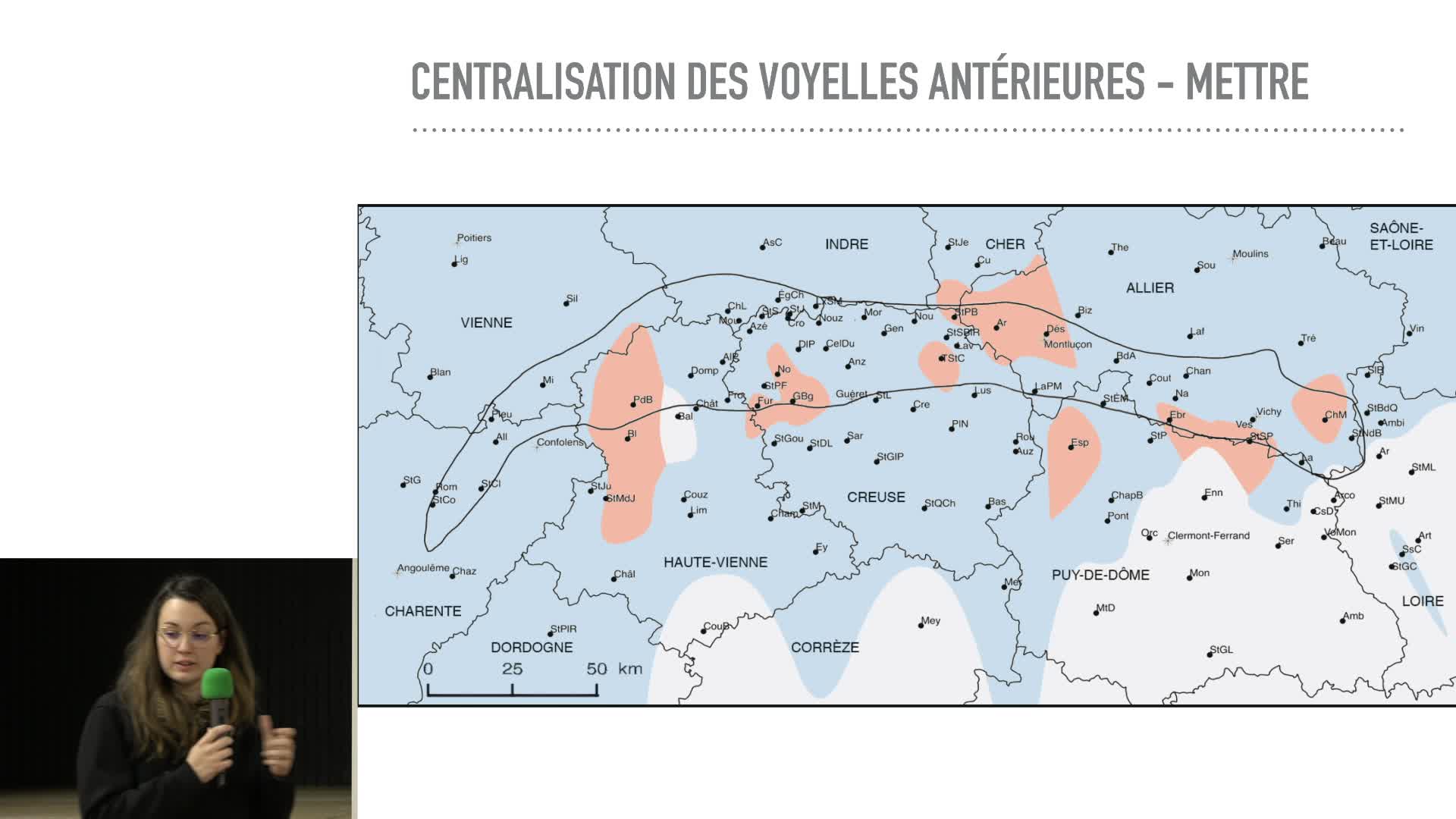
L’intérêt de la cartographie et ce qu’elle nous révèle sur les parlers du Croissant
DeparisAmélieLe Croissant linguistique, nommé ainsi par Ronjat (1913) est une zone de contact entre les langues d’oïl au nord (poitevin-saintongeais, berrichon et bourbonnais) et l’occitan au sud (limousin, et
-
Constitution d’un corpus TAL occitan : états des lieux et perspectives
Bien qu’elle soit une langue minorisée, la langue occitane jouit d'une production abondante autant à l'écrit qu’à l'oral. L'intérêt de bâtir un corpus spécifique au traitement automatique des langues
-
Scripturalité juridique et variétés régionales : la langues des « Comptes consulaires » de Montferr…
Le rôle de l'empreinte régionale, voire locale, de la scripturalité occitane est sujet de controverse. Les défenseurs du caractère intrinsèquement dialectalisé de l'occitan écrit et ceux qui au
-
Des attaques branchantes dans le Croissant
Dans les verbes des parlers de Nouzerines et Saint-Pierre-le-Bost (Creuse), une séquence finale Consonne-Liquide (CL) est séparée par une voyelle accentuée [œ] (en gras dans 1i, cf. 1ii,iii)
-
Graphies et productions autochtones : les différentes options disponibles pour les auteurs
Les questions graphiques sont centrales à l’élaboration de tout ouvrage. En nous aidant d'une analyse qualitative et ethnographique d'une dizaine d'ouvrages autochtones réalisés par certains locaux du
-
Y’a une lèbre dans la cherbe : étude de la variation du genre dans les parlers du Croissant, d’aprè…
Suite à une étude sur les parlers francoprovençaux (Sauzet et Brun-Trigaud, à par.) et à des travaux sur l’assignation des noms en genre dans différentes langues du monde (Allassonnière-Tang et al.
-
Le Croissant d’Indre : un aperçu des parlers marchois de l’extrême-nord
QuintNicolasÀ l’exception peut-être de quelques rares points situés en Allier (p.ex. Viplaix), c’est en Indre (Tourtoulon et Bringuier 1876) que l’on rencontre les parlers croissantins les plus septentrionaux.
-
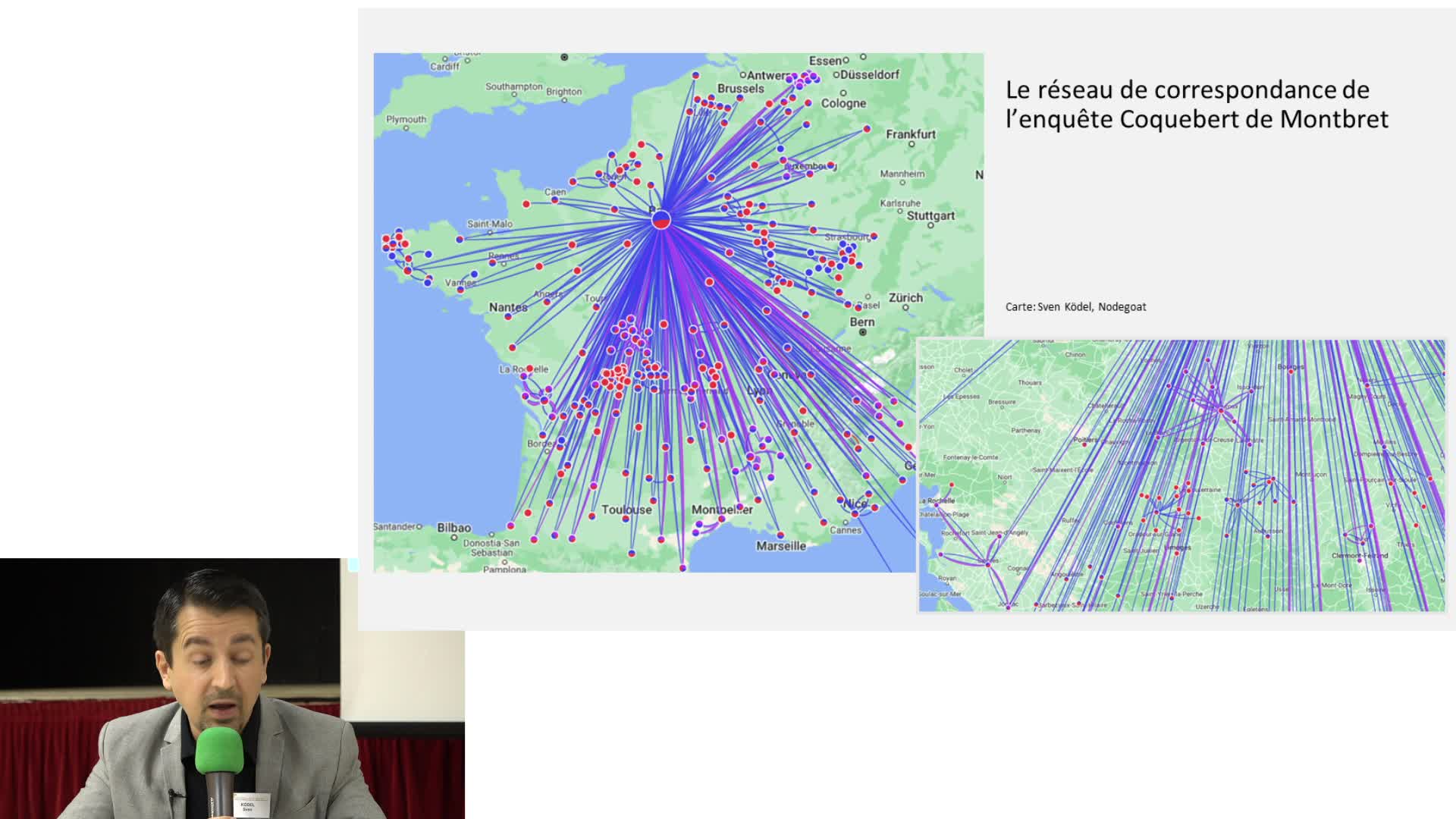
Perception de la variation linguistique des parlers du Croissant dans l’enquête des Coquebert de Mo…
KödelSvenDans le cadre de l’enquête du Premier Empire sur les langues et dialectes de France, le territoire du Croissant est couvert dès 1806 afin de déterminer la limite entre Oc et Oïl. Mais alors que







Avec les mêmes intervenants et intervenantes
-
Classification des dialectes romans fondée sur les innovations par rapport au latin
Boula de MareüilPhilippeClassification des dialectes romans fondée sur les innovations par rapport au latin. Philippe Boula de Mareuil (CNRS - LISN)
-
Le croissant et le traitement automatique du langage
Boula de MareüilPhilippeCette aire linguistique qu'on appelle croissant, est particulièrement intéressant parce qu'on y observe une grande variation des formes hybrides entre oïl et oc, d'où un premier problème pratique qui
-
Le croissant dans l’atlas sonore des langues régionales de France
Boula de MareüilPhilippeDepuis quelques années, dans le laboratoire LISN du CNRS, on développe un atlas sonore des langues régionales de France qui prend la forme d'un site web présentant une carte interactive de France,

