Notice
2.2. Genes: from Mendel to molecular biology
- document 1 document 2 document 3
- niveau 1 niveau 2 niveau 3
Descriptif
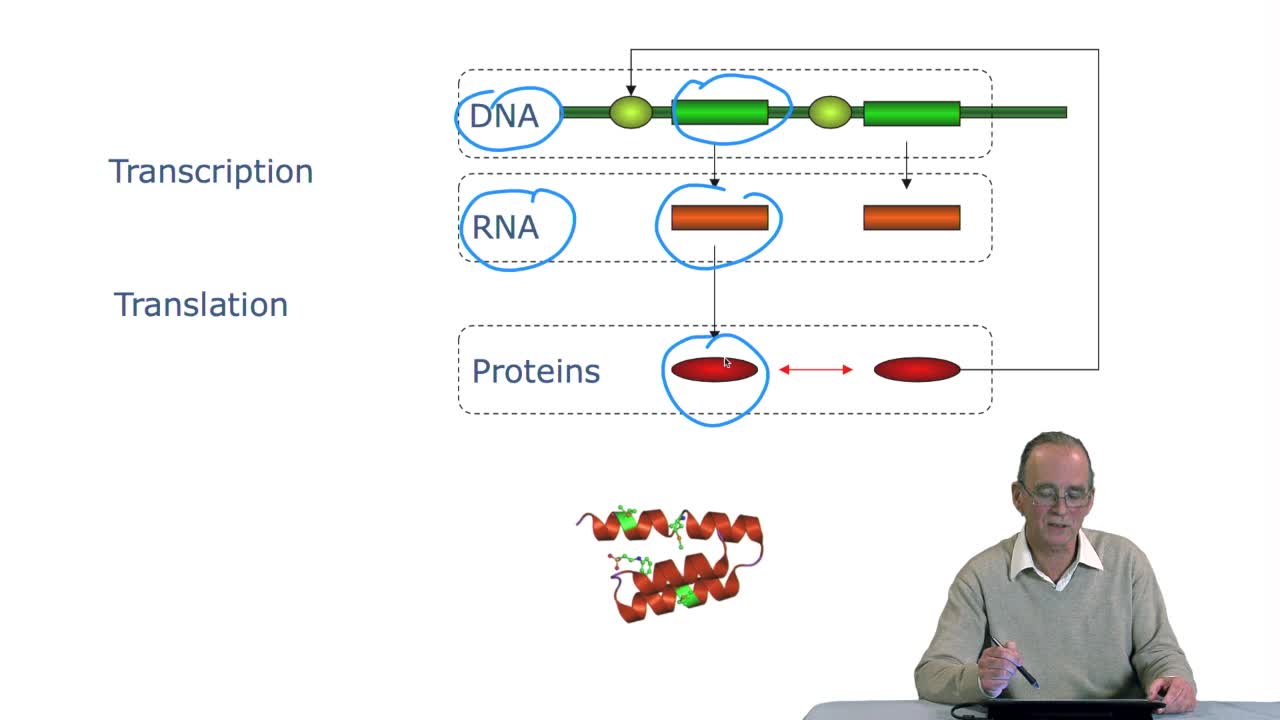
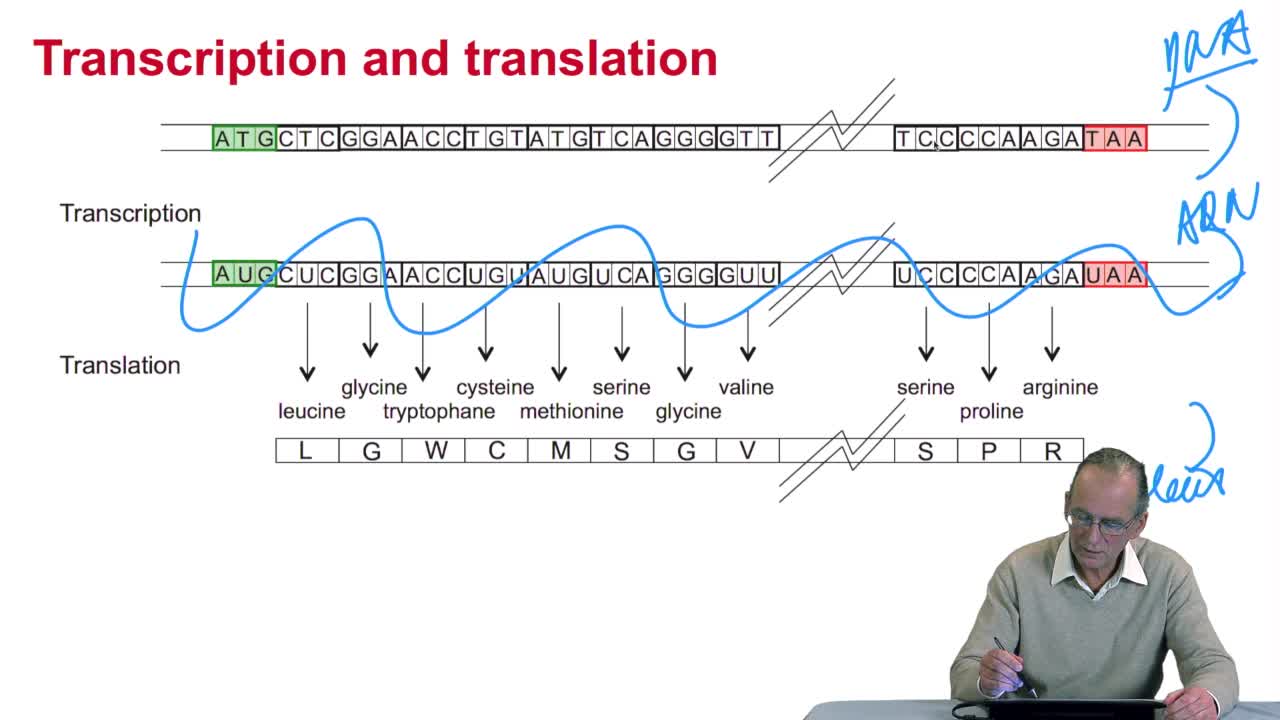
The notion of gene emerged withthe works of Gregor Mendel. Mendel studied the inheritance on some traits like the shape of pea plant seeds,through generations. He stated the famous laws of inheritance which, by the way, were rediscovered 50 years later. The important thing here tounderline is that these concepts of inheritance of genes and so on were very abstract. No physical supports ofthese genes were clarified. So, it's something which appearedlater through molecular biology. We now know that genes are thoseregions of DNA which code the
information used by the cell to produce proteins. And, this is what Francis Crick stated as the central dogma of molecular biology. One gene codes for one protein. We know now that this dogma is not valid anymore. We have several counter examples. But at that time, it was quite a reasonable hypothesis. A view of the central dogma is here. You have DNA and you have proteins. And a gene codes for one protein. Again it's not the whole truthbut it's a good approximation, especially for bacterial genome. But, there's this step here where DNA is first transcribed into RNA. And then, RNA is used by thecell to produce proteins.
Intervention / Responsable scientifique

Thème
Documentation
Dans la même collection
-
2.7. The algorithm design trade-off
RechenmannFrançoisWe saw how to increase the efficiencyof our algorithm through the introduction of a data structure. Now let's see if we can do even better. We had a table of index and weexplain how the use of these
-
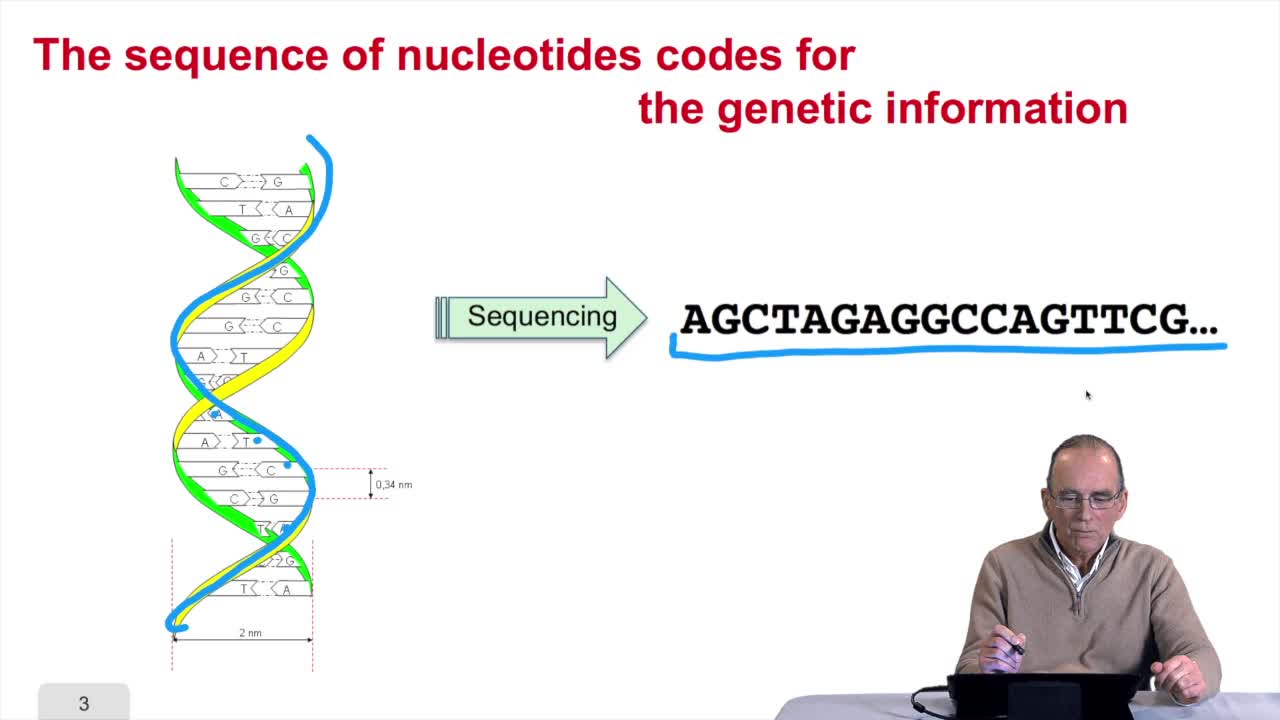
2.1. The sequence as a model of DNA
RechenmannFrançoisWelcome back to our course on genomes and algorithms that is a computer analysis ofgenetic information. Last week we introduced the very basic concept in biology that is cell, DNA, genome, genes
-
2.10. How to find genes?
RechenmannFrançoisGetting the sequence of the genome is only the beginning, as I explained, once you have the sequence what you want to do is to locate the gene, to predict the function of the gene and maybe study the
-
2.5. Implementing the genetic code
RechenmannFrançoisRemember we were designing our translation algorithm and since we are a bit lazy, we decided to make the hypothesis that there was the adequate function forimplementing the genetic code. It's now time
-
2.8. DNA sequencing
RechenmannFrançoisDuring the last session, I explained several times how it was important to increase the efficiency of sequences processing algorithm because sequences arevery long and there are large volumes of
-
2.3. The genetic code
RechenmannFrançoisGenes code for proteins. What is the correspondence betweenthe genes, DNA sequences, and the structure of proteins? The correspondence isthe genetic code. Proteins have indeedsequences of amino acids.
-
2.6. Algorithms + data structures = programs
RechenmannFrançoisBy writing the Lookup GeneticCode Function, we completed our translation algorithm. So we may ask the question about the algorithm, does it terminate? Andthe answer is yes, obviously. Is it pertinent,
-
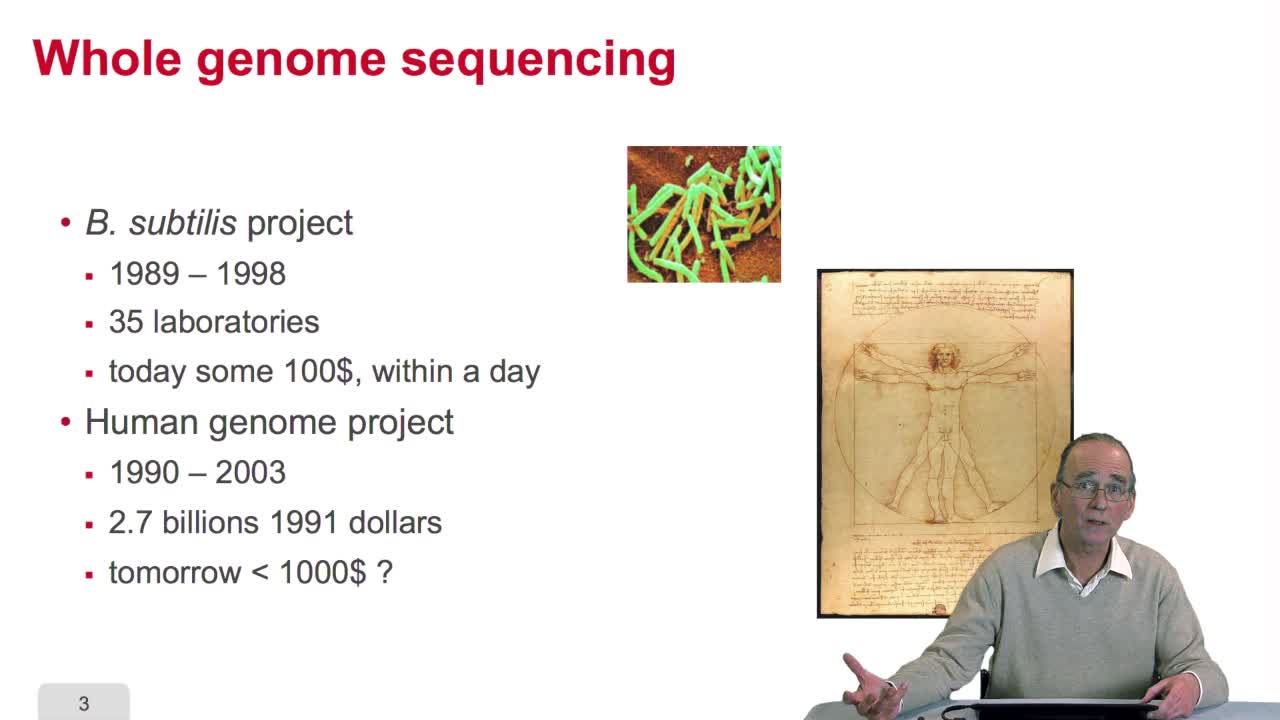
2.9. Whole genome sequencing
RechenmannFrançoisSequencing is anexponential technology. The progresses in this technologyallow now to a sequence whole genome, complete genome. What does it mean? Well let'stake two examples: some twenty years ago,
-
2.4. A translation algorithm
RechenmannFrançoisWe have seen that the genetic codeis a correspondence between the DNA or RNA sequences and aminoacid sequences that is proteins. Our aim here is to design atranslation algorithm, we make the






Avec les mêmes intervenants et intervenantes
-
1.3. DNA codes for genetic information
RechenmannFrançoisRemember at the heart of any cell,there is this very long molecule which is called a macromolecule for this reason, which is the DNA molecule. Now we will see that DNA molecules support what is called
-
2.1. The sequence as a model of DNA
RechenmannFrançoisWelcome back to our course on genomes and algorithms that is a computer analysis ofgenetic information. Last week we introduced the very basic concept in biology that is cell, DNA, genome, genes
-
2.10. How to find genes?
RechenmannFrançoisGetting the sequence of the genome is only the beginning, as I explained, once you have the sequence what you want to do is to locate the gene, to predict the function of the gene and maybe study the
-
3.8. Probabilistic methods
RechenmannFrançoisUp to now, to predict our gene,we only rely on the process of searching certain strings or patterns. In order to further improve our gene predictor, the idea is to use, to rely onprobabilistic methods
-
4.3. Measuring sequence similarity
RechenmannFrançoisSo we understand why gene orprotein sequences may be similar. It's because they evolve togetherwith the species and they evolve in time, there aremodifications in the sequence and that the sequence
-
5.3. Building an array of distances
RechenmannFrançoisSo using the sequences of homologous gene between several species, our aim is to reconstruct phylogenetic tree of the corresponding species. For this, we have to comparesequences and compute distances
-
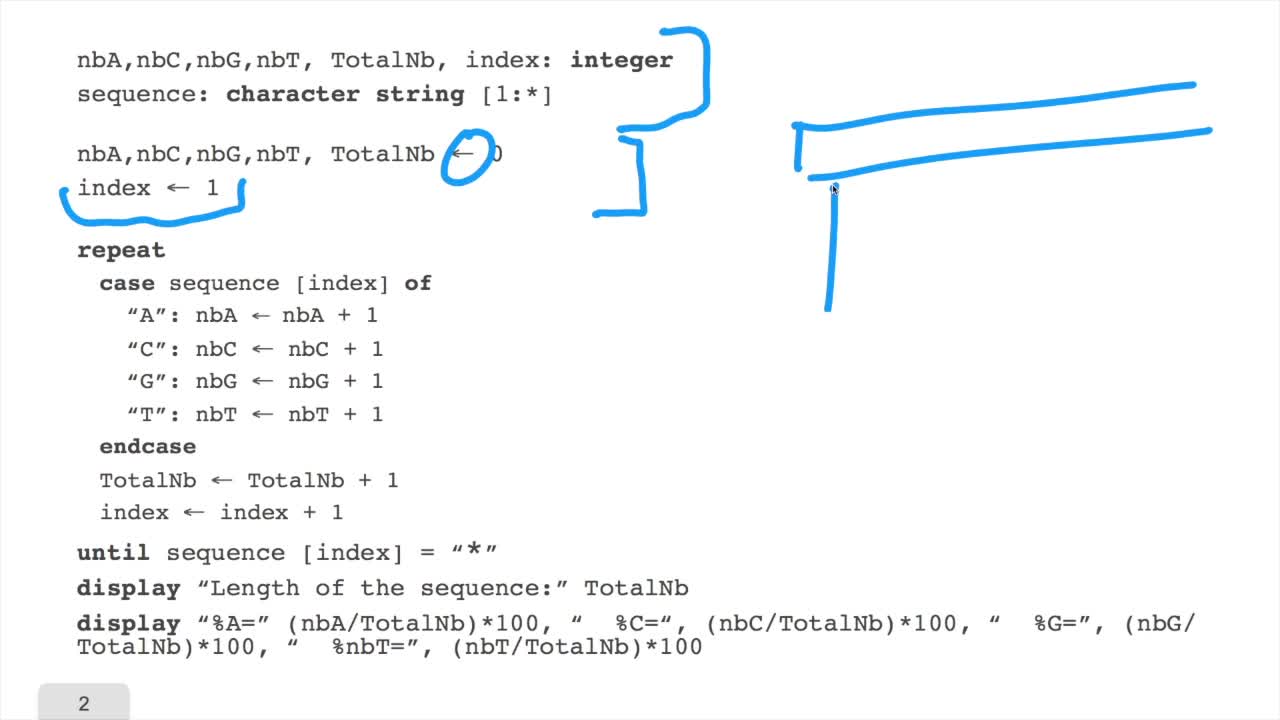
1.6. GC and AT contents of DNA sequence
RechenmannFrançoisWe have designed our first algorithmfor counting nucleotides. Remember, what we have writtenin pseudo code is first declaration of variables. We have several integer variables that are variables which
-
2.6. Algorithms + data structures = programs
RechenmannFrançoisBy writing the Lookup GeneticCode Function, we completed our translation algorithm. So we may ask the question about the algorithm, does it terminate? Andthe answer is yes, obviously. Is it pertinent,
-
3.3. Searching for start and stop codons
RechenmannFrançoisWe have written an algorithm for finding genes. But you remember that we arestill to write the two functions for finding the next stop codonand the next start codon. Let's see how we can do that. We
-
4.1. How to predict gene/protein functions?
RechenmannFrançoisLast week we have seen that annotating a genome means first locating the genes on the DNA sequences that is the genes, the region coding for proteins. But this is indeed the first step,the next very
-
4.10. How efficient is this algorithm?
RechenmannFrançoisWe have seen the principle of an iterative algorithm in two paths for aligning and comparing two sequences of characters, here DNA sequences. And we understoodwhy the iterative version is much more
-
5.7. The application domains in microbiology
RechenmannFrançoisBioinformatics relies on many domains of mathematics and computer science. Of course, algorithms themselves on character strings are important in bioinformatics, we have seen them. Algorithms and