Notice
3.3. Searching for start and stop codons
- document 1 document 2 document 3
- niveau 1 niveau 2 niveau 3
Descriptif
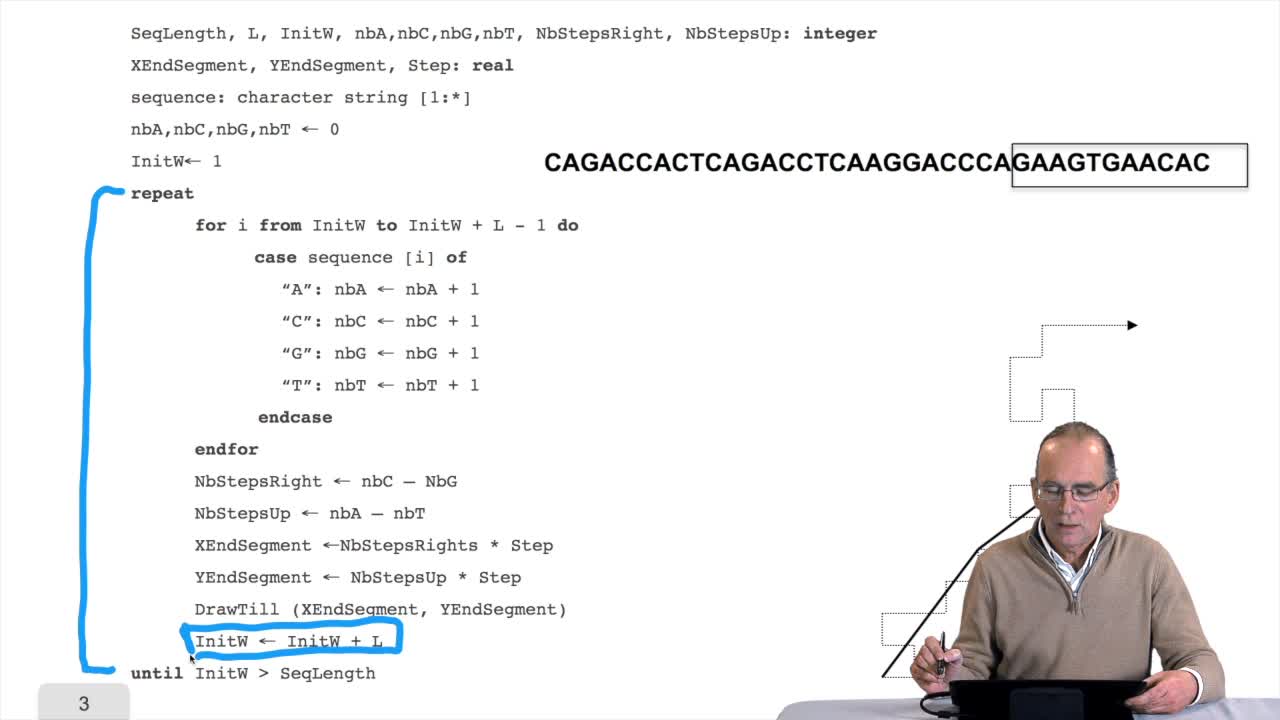
We have written an algorithm for finding genes. But you remember that we arestill to write the two functions for finding the next stop codonand the next start codon. Let's see how we can do that. We are looking for triplets. We use the term triplets as long as wehave no proof that they are codons. You can have triplets outside genes. Within genes, they are called codons. In general, we arelooking for triplets. If you have a sequence like thisone and you are looking for occurrences of this triplet, whatyou have to do is: position your triplet at the beginning of the sequence. Compare the first letter. If it is not the same, skip tothe second triplet, this one. Make the comparison. Again here, the first comparison works. So, you may do the second comparison, it works. But the third doesn't. Again, you progress and then youhave, here, a match, a second match and a third match. So, you have found an occurrence of the triplets on the sequence. That means that the number of comparisons, in the worst case, for one of the three stop codonsis the length of the text.
Intervention / Responsable scientifique

Thème
Documentation
Dans la même collection
-
3.7. Index and suffix trees
RechenmannFrançoisWe have seen with the Boyer-Moore algorithm how we can increase the efficiency of spin searching through the pre-processing of the pattern to be searched. Now we will see that an alternative way of
-
3.1. All genes end on a stop codon
RechenmannFrançoisLast week we studied genes and proteins and so how genes, portions of DNA, are translated into proteins. We also saw the very fast evolutionof the sequencing technology which allows for producing
-
3.10. Gene prediction in eukaryotic genomes
RechenmannFrançoisIf it is possible to have verygood predictions for bacterial genes, it's certainly not the caseyet for eukaryotic genomes. Eukaryotic cells have manydifferences in comparison to prokaryotic cells. You
-
3.5. Making the predictions more reliable
RechenmannFrançoisWe have got a bacterial gene predictor but the way this predictor works is rather crude and if we want to have more reliable results, we have to inject into this algorithmmore biological knowledge. We
-
3.8. Probabilistic methods
RechenmannFrançoisUp to now, to predict our gene,we only rely on the process of searching certain strings or patterns. In order to further improve our gene predictor, the idea is to use, to rely onprobabilistic methods
-
3.2. A simple algorithm for gene prediction
RechenmannFrançoisBased on the principle we statedin the last session, we will now write in pseudo code a firstalgorithm for locating genes on a bacterial genome. Remember first how this algorithm should work, we first
-
3.6. Boyer-Moore algorithm
RechenmannFrançoisWe have seen how we can make gene predictions more reliable through searching for all the patterns,all the occurrences of patterns. We have seen, for example, howif we locate the RBS, Ribosome
-
3.9. Benchmarking the prediction methods
RechenmannFrançoisIt is necessary to underline that gene predictors produce predictions. Predictions mean that you have no guarantees that the coding sequences, the coding regions,the genes you get when applying your
-
3.4. Predicting all the genes in a sequence
RechenmannFrançoisWe have written an algorithm whichis able to locate potential genes on a sequence but only on one phase because we are looking triplets after triplets. Now remember that the genes maybe located on









Avec les mêmes intervenants et intervenantes
-
1.1. The cell, atom of the living world
RechenmannFrançoisWelcome to this introduction to bioinformatics. We will speak of genomes and algorithms. More specifically, we will see how genetic information can be analysed by algorithms. In these five weeks to
-
1.9. Predicting the origin of DNA replication?
RechenmannFrançoisWe have seen a nice algorithm to draw, let's say, a DNA sequence. We will see that first, we have to correct a little bit this algorithm. And then we will see how such as imple algorithm can provide
-
2.8. DNA sequencing
RechenmannFrançoisDuring the last session, I explained several times how it was important to increase the efficiency of sequences processing algorithm because sequences arevery long and there are large volumes of
-
3.6. Boyer-Moore algorithm
RechenmannFrançoisWe have seen how we can make gene predictions more reliable through searching for all the patterns,all the occurrences of patterns. We have seen, for example, howif we locate the RBS, Ribosome
-
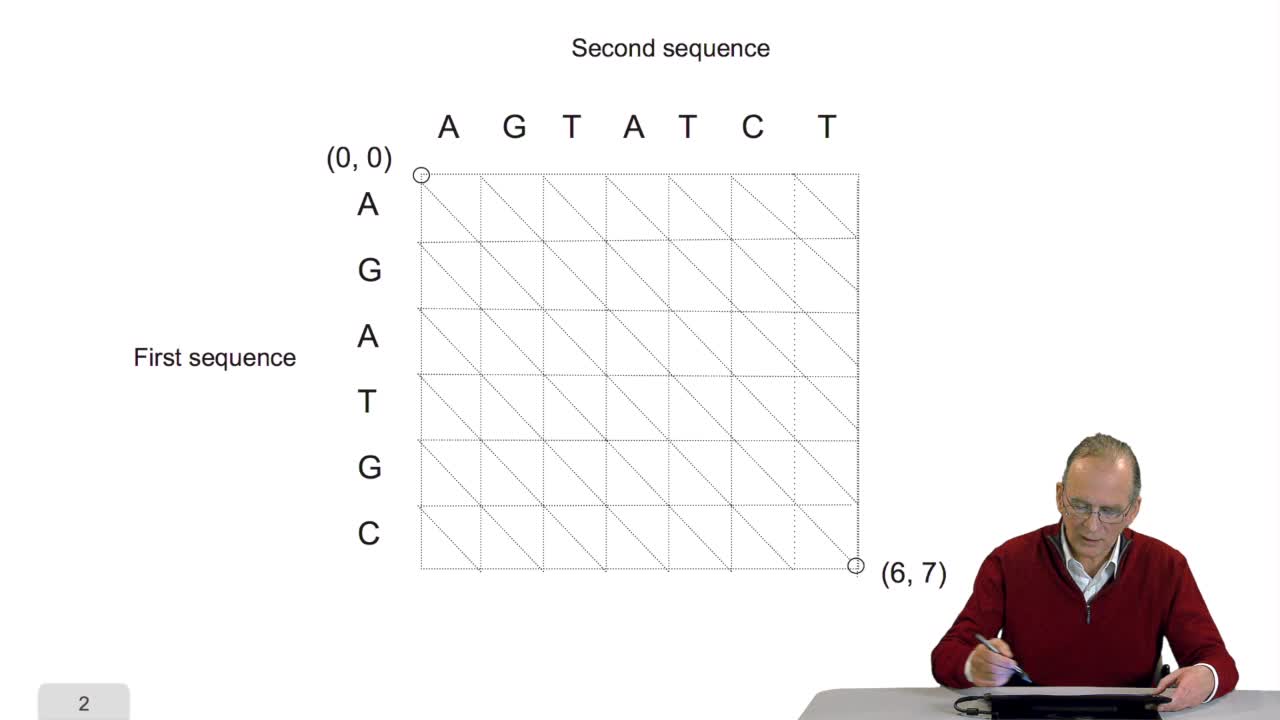
4.5. A sequence alignment as a path
RechenmannFrançoisComparing two sequences and thenmeasuring their similarities is an optimization problem. Why? Because we have seen thatwe have to take into account substitution and deletion. During the alignment, the
-
5.5. Differences are not always what they look like
RechenmannFrançoisThe algorithm we have presented works on an array of distance between sequences. These distances are evaluated on the basis of differences between the sequences. The problem is that behind the
-
1.4. What is an algorithm?
RechenmannFrançoisWe have seen that a genomic textcan be indeed a very long sequence of characters. And to interpret this sequence of characters, we will need to use computers. Using computers means writing program.
-
2.2. Genes: from Mendel to molecular biology
RechenmannFrançoisThe notion of gene emerged withthe works of Gregor Mendel. Mendel studied the inheritance on some traits like the shape of pea plant seeds,through generations. He stated the famous laws of inheritance
-
2.10. How to find genes?
RechenmannFrançoisGetting the sequence of the genome is only the beginning, as I explained, once you have the sequence what you want to do is to locate the gene, to predict the function of the gene and maybe study the
-
3.9. Benchmarking the prediction methods
RechenmannFrançoisIt is necessary to underline that gene predictors produce predictions. Predictions mean that you have no guarantees that the coding sequences, the coding regions,the genes you get when applying your
-
4.2. Why gene/protein sequences may be similar?
RechenmannFrançoisBefore measuring the similaritybetween the sequences, it's interesting to answer the question: why gene or protein sequences may be similar? It is indeed veryinteresting because the answer is related
-
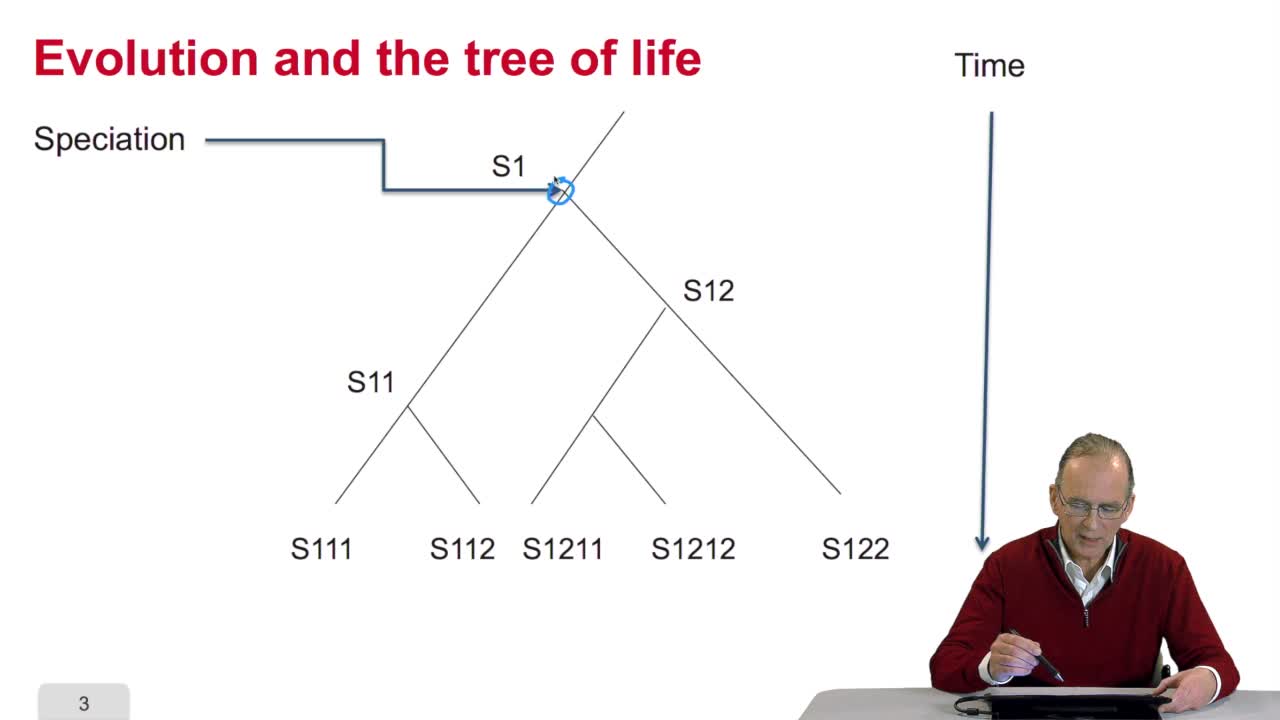
5.4. The UPGMA algorithm
RechenmannFrançoisWe know how to fill an array with the values of the distances between sequences, pairs of sequences which are available in the file. This array of distances will be the input of our algorithm for