Notice
5.1. The tree of life
- document 1 document 2 document 3
- niveau 1 niveau 2 niveau 3
Descriptif
Welcome to this fifth and last week of our course on genomes and algorithms that is the computer analysis of genetic information. During this week, we will firstsee what phylogenetic trees are and how we can reconstruct these trees from the available data. Then to conclude this week and this course, we will present an overview, a larger overview of bioinformatic algorithms and we will conclude on the application of bioinformatics at least in the microbial world. So first the tree of life, we have already seen that due to the ideas of Darwin, we know that species evolve and the evolution of these species canbe seen as a tree. Each note of the tree is aspecies, there are some specific events which are called speciation when one species evolves into two different species and so on. Over time new species appeared and we have at the leaves of the tree the species which are known presently. The problem here is: is it possible to reconstruct the phylogenetic tree of a set of species knowing that we have at our disposal only the data on what we see now? We have to reconstruct a story using the available information and data. The answer is Yes, of course, we have no mean to be sure that the tree we will reconstruct isthe real one but we can make assumptions, hypothesis and usealgorithms to build phylogenetic trees from available information. Two classes of information can beused, the so-called phenotypic information, that is to say, the phenotype is what we see of a living system. The aspect of it, its characteristic, anatomy and so on.
Intervention / Responsable scientifique

Thème
Documentation
Dans la même collection
-
5.7. The application domains in microbiology
RechenmannFrançoisBioinformatics relies on many domains of mathematics and computer science. Of course, algorithms themselves on character strings are important in bioinformatics, we have seen them. Algorithms and
-
5.2. The tree, an abstract object
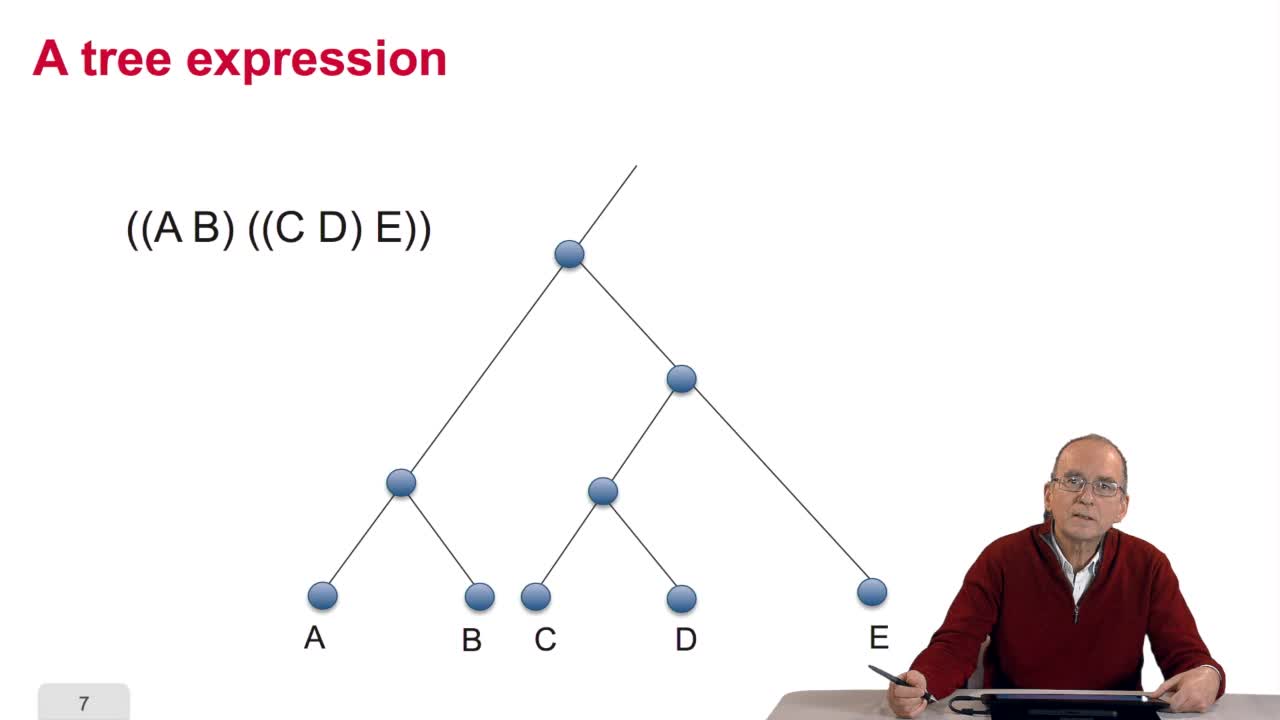
RechenmannFrançoisWhen we speak of trees, of species,of phylogenetic trees, of course, it's a metaphoric view of a real tree. Our trees are abstract objects. Here is a tree and the different components of this tree.
-
5.5. Differences are not always what they look like
RechenmannFrançoisThe algorithm we have presented works on an array of distance between sequences. These distances are evaluated on the basis of differences between the sequences. The problem is that behind the
-
5.3. Building an array of distances
RechenmannFrançoisSo using the sequences of homologous gene between several species, our aim is to reconstruct phylogenetic tree of the corresponding species. For this, we have to comparesequences and compute distances
-
5.6. The diversity of bioinformatics algorithms
RechenmannFrançoisIn this course, we have seen a very little set of bioinformatic algorithms. There exist numerous various algorithms in bioinformatics which deal with a large span of classes of problems. For example,
-
5.4. The UPGMA algorithm
RechenmannFrançoisWe know how to fill an array with the values of the distances between sequences, pairs of sequences which are available in the file. This array of distances will be the input of our algorithm for





Avec les mêmes intervenants et intervenantes
-
1.3. DNA codes for genetic information
RechenmannFrançoisRemember at the heart of any cell,there is this very long molecule which is called a macromolecule for this reason, which is the DNA molecule. Now we will see that DNA molecules support what is called
-
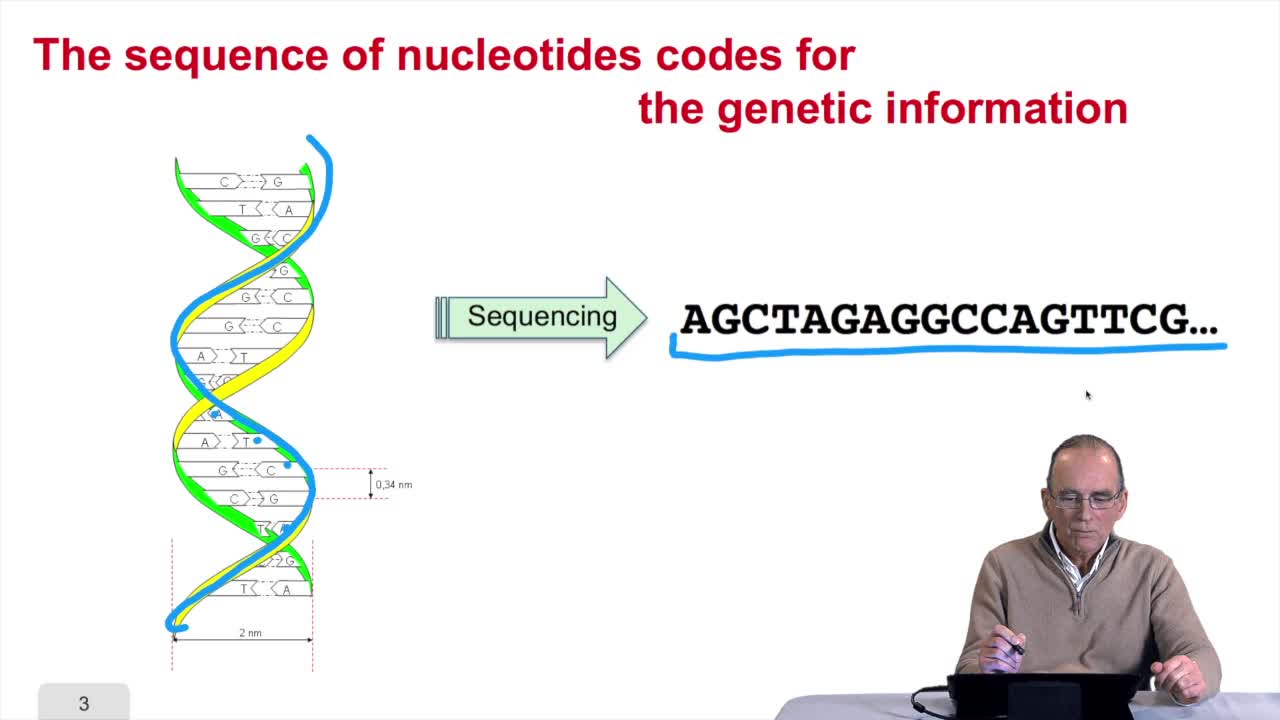
2.1. The sequence as a model of DNA
RechenmannFrançoisWelcome back to our course on genomes and algorithms that is a computer analysis ofgenetic information. Last week we introduced the very basic concept in biology that is cell, DNA, genome, genes
-
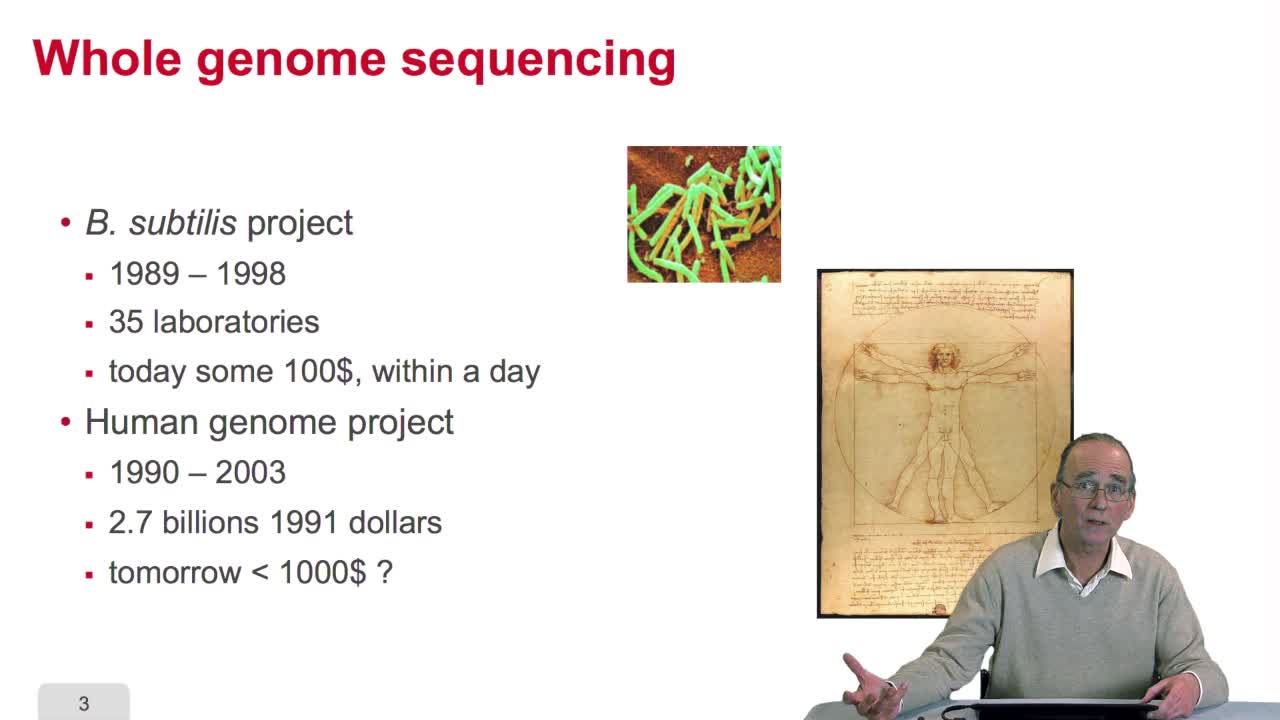
2.9. Whole genome sequencing
RechenmannFrançoisSequencing is anexponential technology. The progresses in this technologyallow now to a sequence whole genome, complete genome. What does it mean? Well let'stake two examples: some twenty years ago,
-
3.7. Index and suffix trees
RechenmannFrançoisWe have seen with the Boyer-Moore algorithm how we can increase the efficiency of spin searching through the pre-processing of the pattern to be searched. Now we will see that an alternative way of
-
4.4. Aligning sequences is an optimization problem
RechenmannFrançoisWe have seen a nice and a quitesimple solution for measuring the similarity between two sequences. It relied on the so-called hammingdistance that is counting the number of differencesbetween two
-
5.3. Building an array of distances
RechenmannFrançoisSo using the sequences of homologous gene between several species, our aim is to reconstruct phylogenetic tree of the corresponding species. For this, we have to comparesequences and compute distances
-
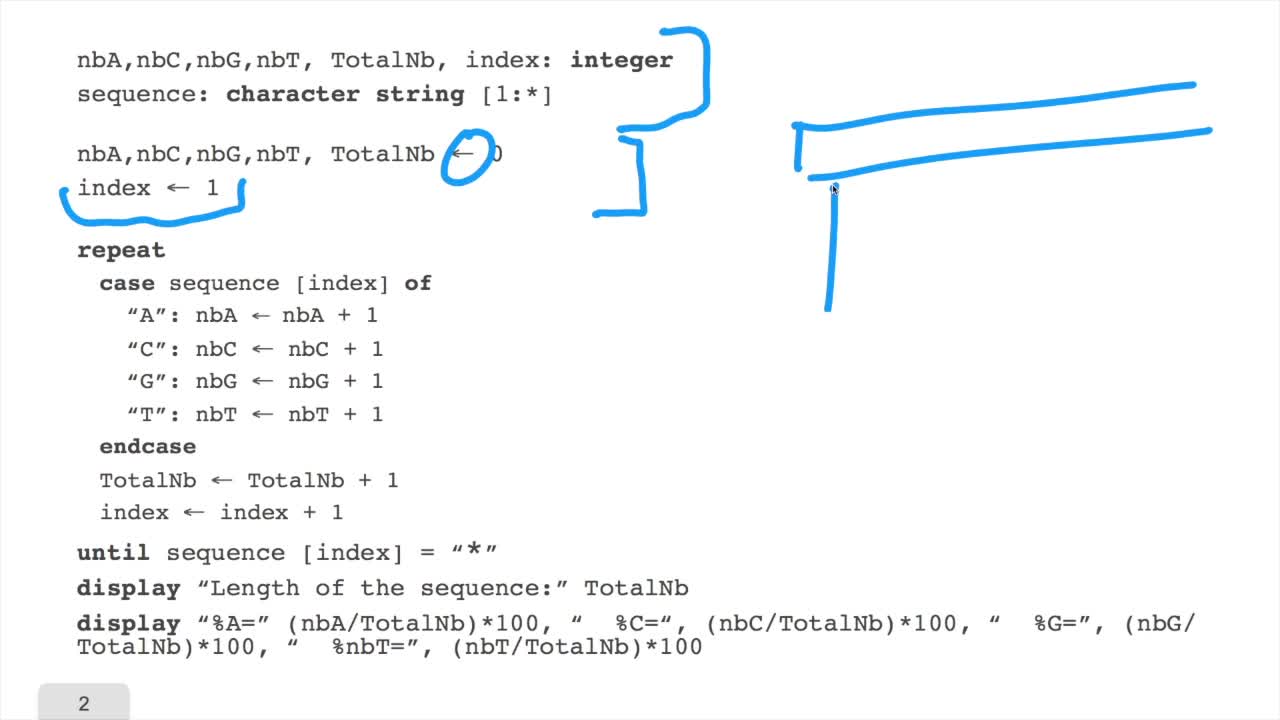
1.6. GC and AT contents of DNA sequence
RechenmannFrançoisWe have designed our first algorithmfor counting nucleotides. Remember, what we have writtenin pseudo code is first declaration of variables. We have several integer variables that are variables which
-
2.5. Implementing the genetic code
RechenmannFrançoisRemember we were designing our translation algorithm and since we are a bit lazy, we decided to make the hypothesis that there was the adequate function forimplementing the genetic code. It's now time
-
3.2. A simple algorithm for gene prediction
RechenmannFrançoisBased on the principle we statedin the last session, we will now write in pseudo code a firstalgorithm for locating genes on a bacterial genome. Remember first how this algorithm should work, we first
-
3.10. Gene prediction in eukaryotic genomes
RechenmannFrançoisIf it is possible to have verygood predictions for bacterial genes, it's certainly not the caseyet for eukaryotic genomes. Eukaryotic cells have manydifferences in comparison to prokaryotic cells. You
-
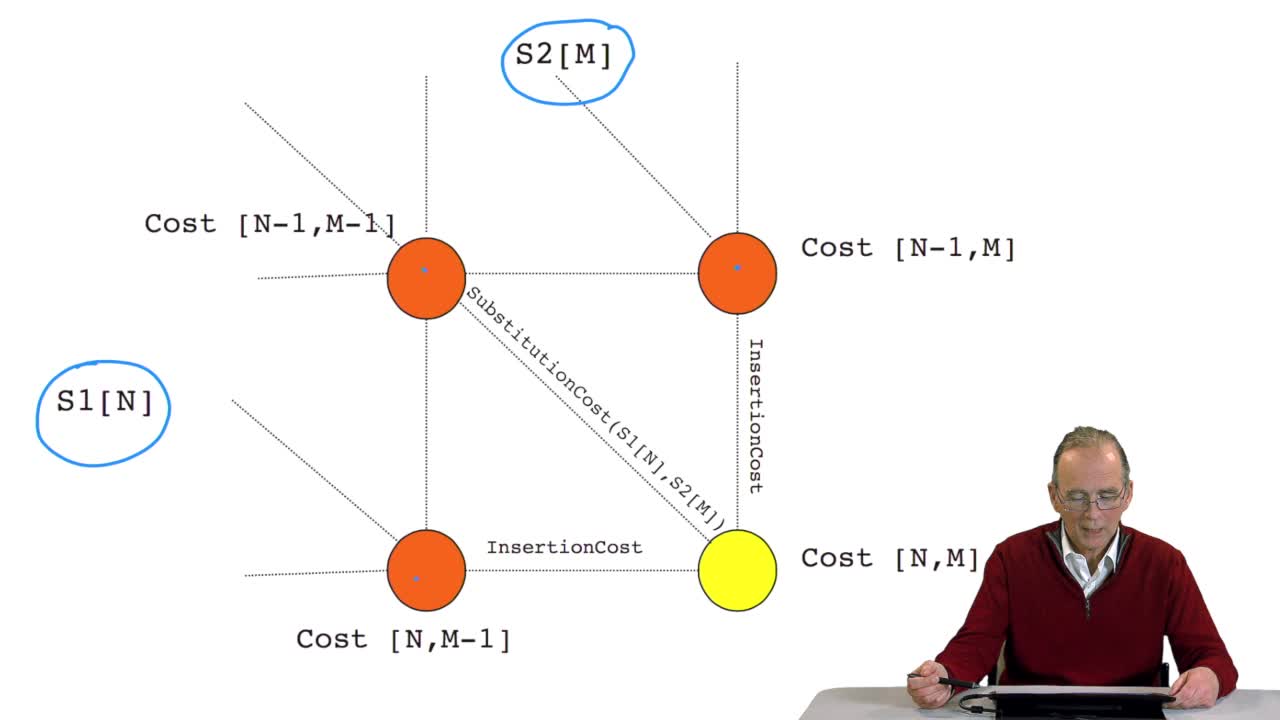
4.8. A recursive algorithm
RechenmannFrançoisWe have seen how we can computethe optimal cost, the ending node of our grid if we know the optimal cost of the three adjacent nodes. This is this computation scheme we can see here using the notation
-
5.7. The application domains in microbiology
RechenmannFrançoisBioinformatics relies on many domains of mathematics and computer science. Of course, algorithms themselves on character strings are important in bioinformatics, we have seen them. Algorithms and