Notice
4.4. Aligning sequences is an optimization problem
- document 1 document 2 document 3
- niveau 1 niveau 2 niveau 3
Descriptif
We have seen a nice and a quitesimple solution for measuring the similarity between two sequences. It relied on the so-called hammingdistance that is counting the number of differencesbetween two sequences. But the real situation is a bitmore complex as we'll see now, it needs an adequatesolution and algorithm. Why is it a bit more complex? Let's have a look at thispair of two sequences. If we apply the hamming distance,compute the hamming between these two sequences,we find ten differences. OK. But you must remember thatmutation may be substitution, deletion and insertion. So if wetake into account the deletion and insertion, the situation isvery different in the case of these two sequences. Let's see why. We can compare now that it isthe same set of sequences but here and here we made the hypothesisof insertion or deletion. Insertion or deletion depend on thesequence you take into account and one substitution. Instead ofhaving ten differences, the same sequences show only twoinsertions/deletions and one substitution. It's because we have taken into accountthe notion of insertion/deletion by inserting this character,this blank character.
Intervention / Responsable scientifique

Thème
Documentation
Dans la même collection
-
4.1. How to predict gene/protein functions?
RechenmannFrançoisLast week we have seen that annotating a genome means first locating the genes on the DNA sequences that is the genes, the region coding for proteins. But this is indeed the first step,the next very
-
4.10. How efficient is this algorithm?
RechenmannFrançoisWe have seen the principle of an iterative algorithm in two paths for aligning and comparing two sequences of characters, here DNA sequences. And we understoodwhy the iterative version is much more
-
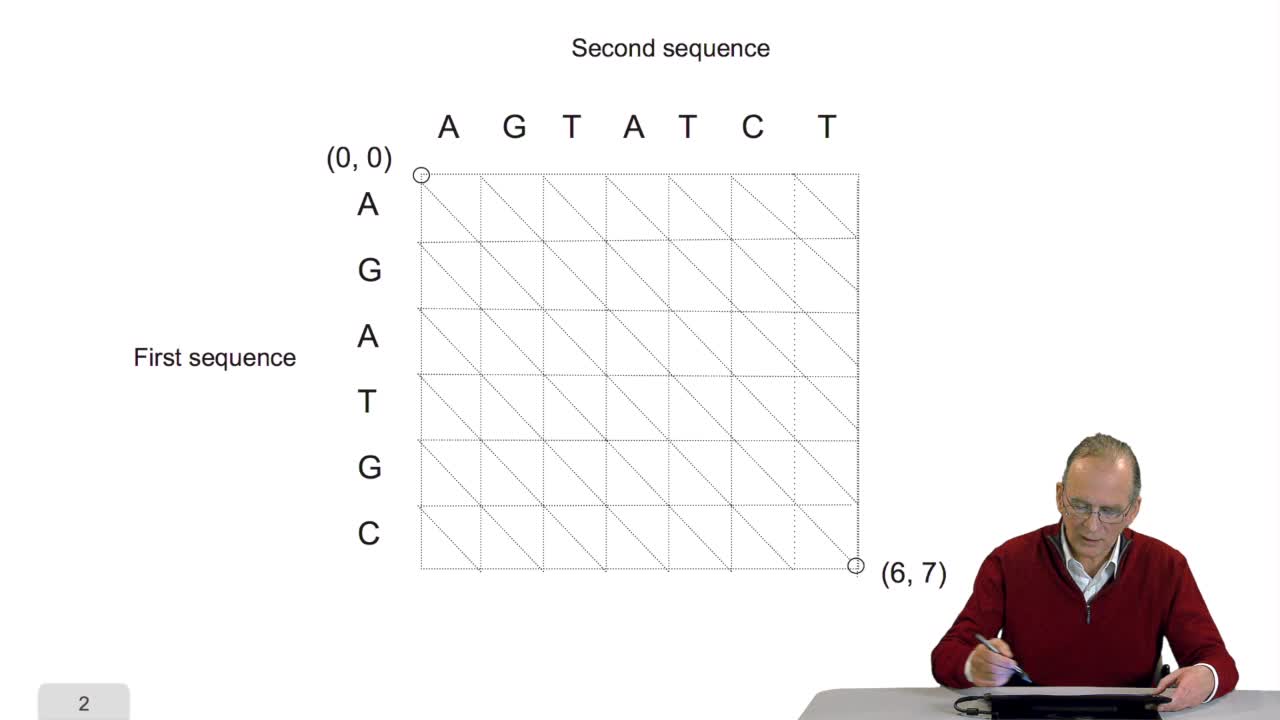
4.5. A sequence alignment as a path
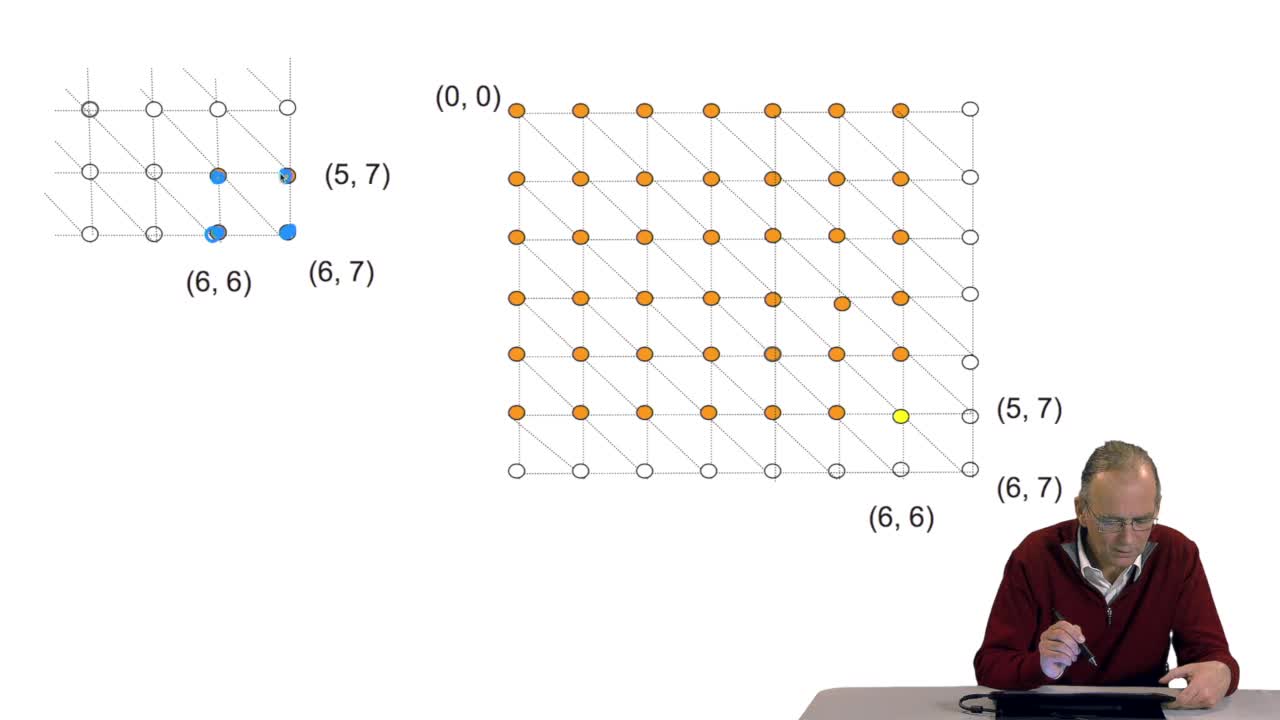
RechenmannFrançoisComparing two sequences and thenmeasuring their similarities is an optimization problem. Why? Because we have seen thatwe have to take into account substitution and deletion. During the alignment, the
-
4.8. A recursive algorithm
RechenmannFrançoisWe have seen how we can computethe optimal cost, the ending node of our grid if we know the optimal cost of the three adjacent nodes. This is this computation scheme we can see here using the notation
-
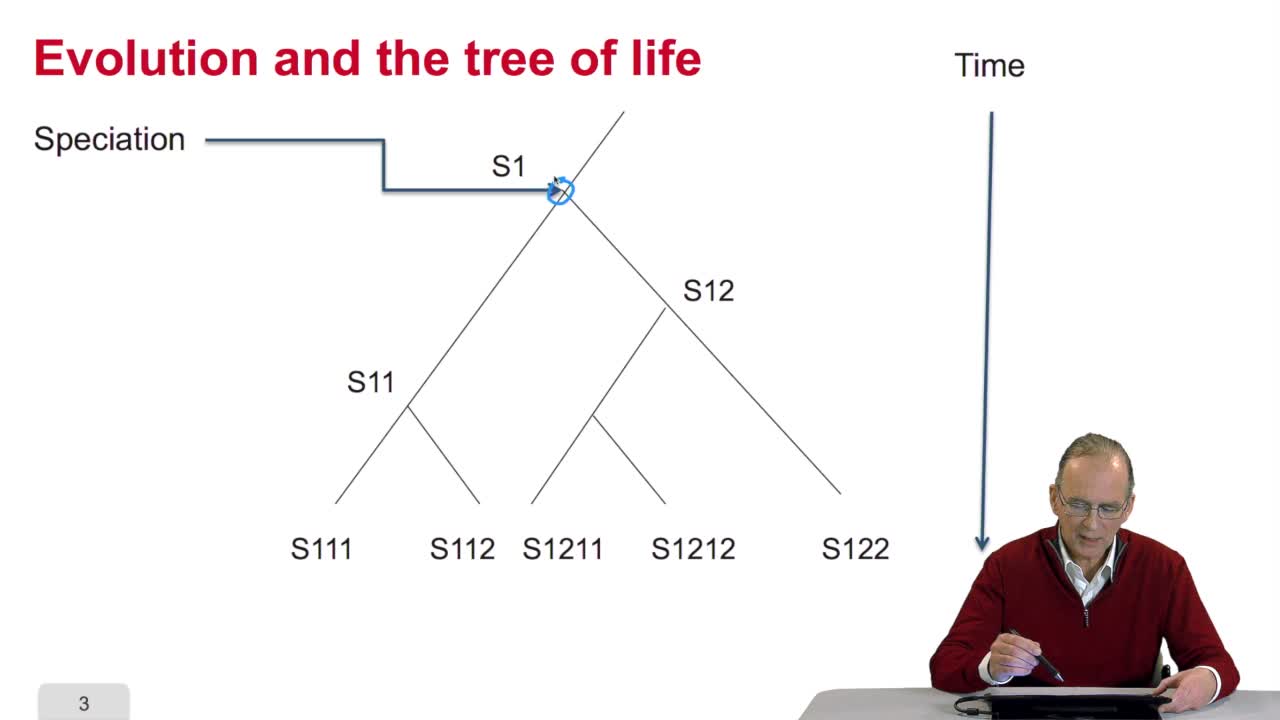
4.2. Why gene/protein sequences may be similar?
RechenmannFrançoisBefore measuring the similaritybetween the sequences, it's interesting to answer the question: why gene or protein sequences may be similar? It is indeed veryinteresting because the answer is related
-
4.6. A path is optimal if all its sub-paths are optimal
RechenmannFrançoisA sequence alignment between two sequences is a path in a grid. So that, an optimal sequence alignmentis an optimal path in the same grid. We'll see now that a property of this optimal path provides
-
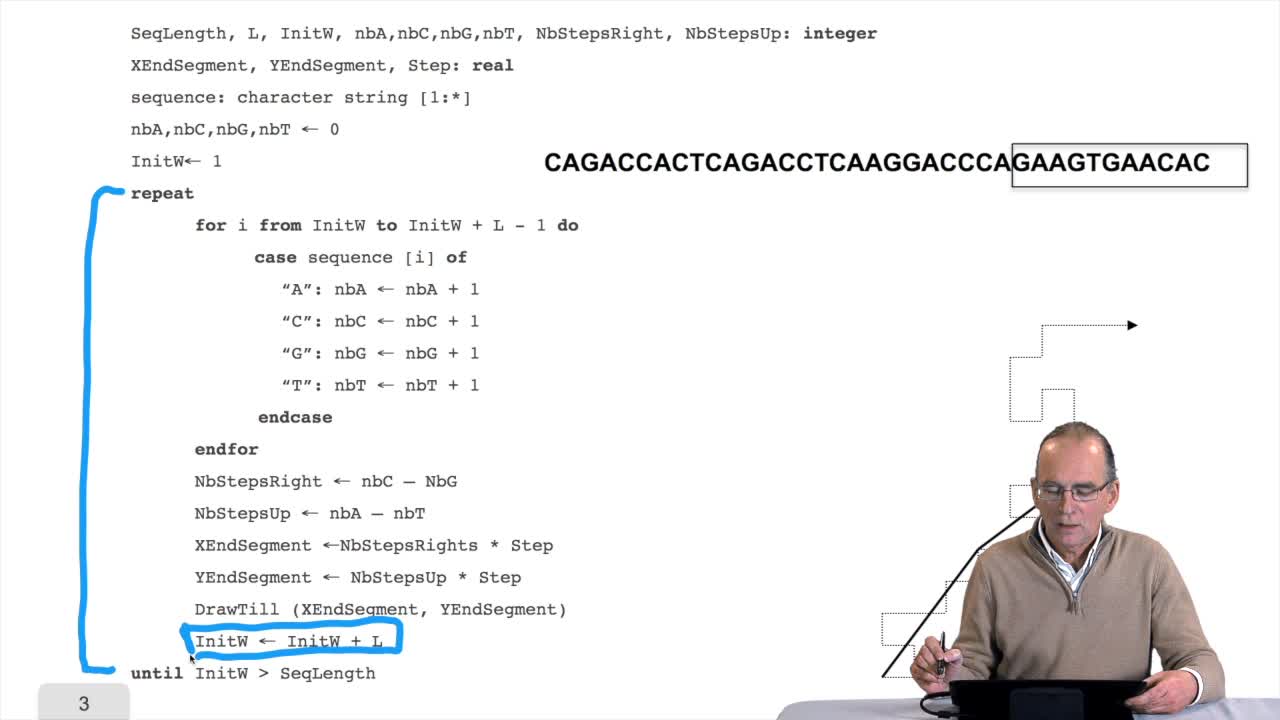
4.9. Recursion can be avoided: an iterative version
RechenmannFrançoisWe have written a recursive function to compute the optimal path that is an optimal alignment between two sequences. Here all the examples I gave were onDNA sequences, four letter alphabet. OK. The
-
4.3. Measuring sequence similarity
RechenmannFrançoisSo we understand why gene orprotein sequences may be similar. It's because they evolve togetherwith the species and they evolve in time, there aremodifications in the sequence and that the sequence
-
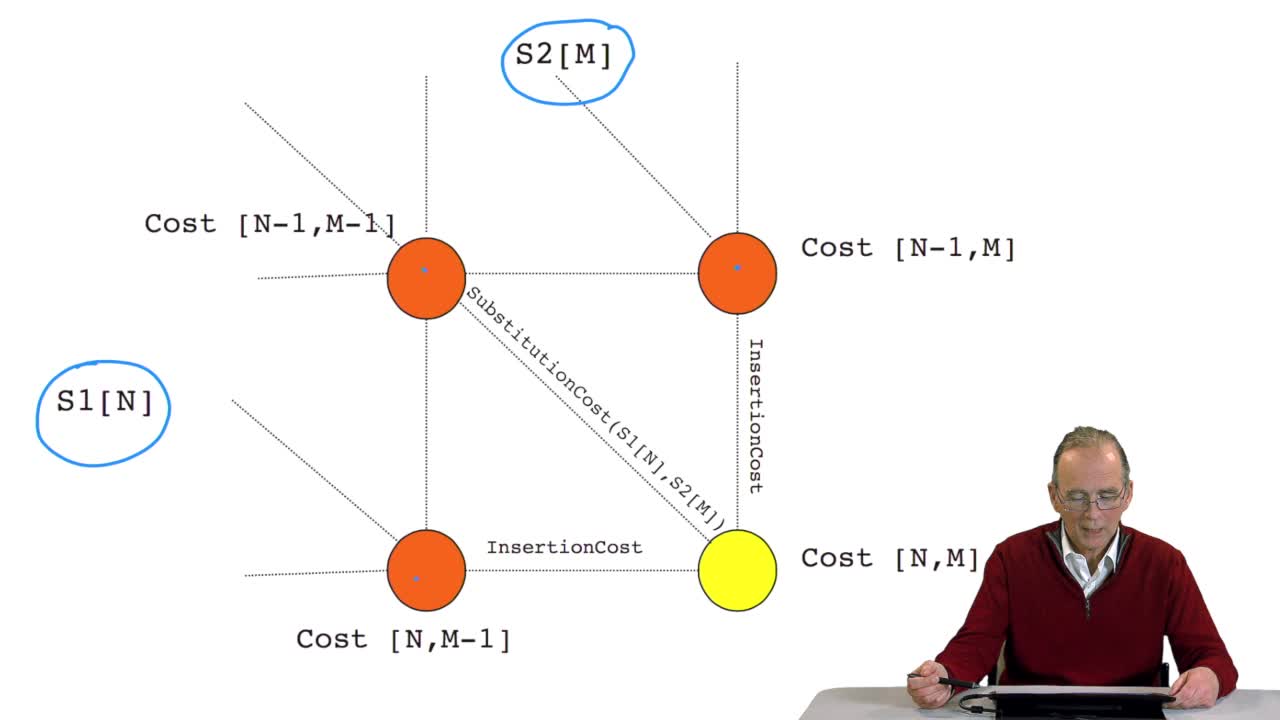
4.7. Alignment costs
RechenmannFrançoisWe have seen how we can compute the cost of the path ending on the last node of our grid if we know the cost of the sub-path ending on the three adjacent nodes. It is time now to see more deeply why





Avec les mêmes intervenants et intervenantes
-
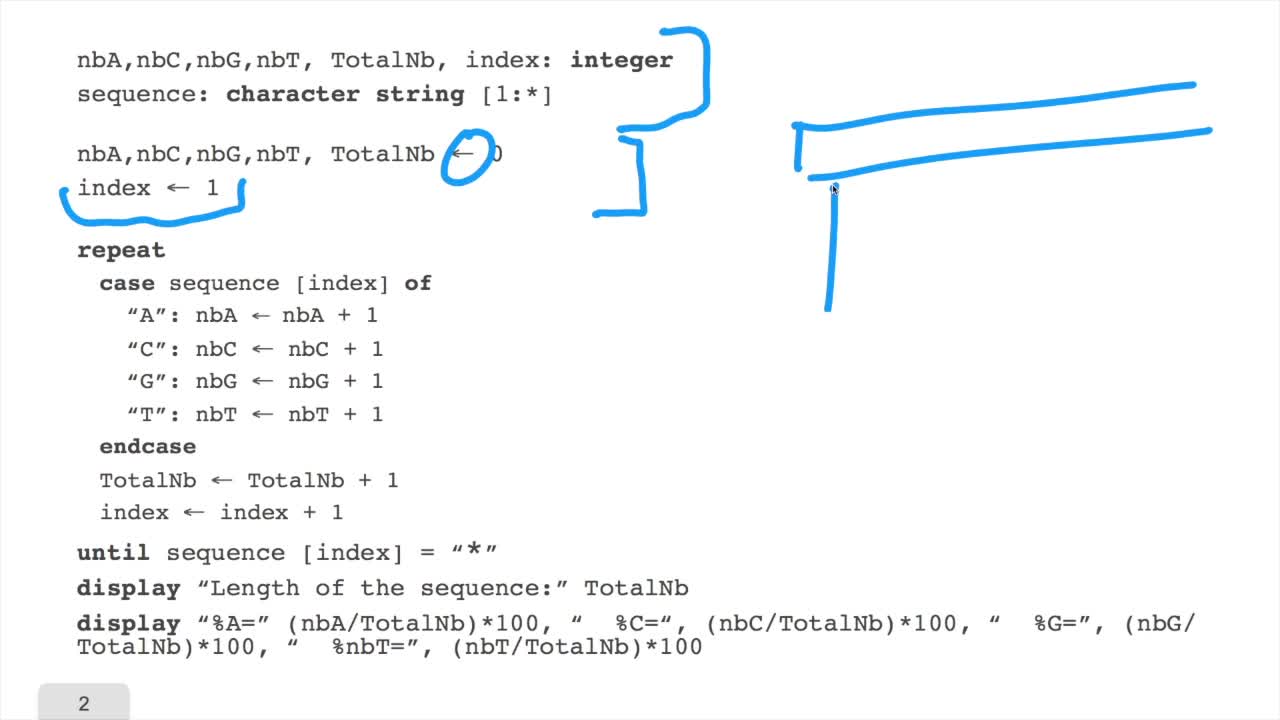
1.6. GC and AT contents of DNA sequence
RechenmannFrançoisWe have designed our first algorithmfor counting nucleotides. Remember, what we have writtenin pseudo code is first declaration of variables. We have several integer variables that are variables which
-
2.5. Implementing the genetic code
RechenmannFrançoisRemember we were designing our translation algorithm and since we are a bit lazy, we decided to make the hypothesis that there was the adequate function forimplementing the genetic code. It's now time
-
3.2. A simple algorithm for gene prediction
RechenmannFrançoisBased on the principle we statedin the last session, we will now write in pseudo code a firstalgorithm for locating genes on a bacterial genome. Remember first how this algorithm should work, we first
-
3.10. Gene prediction in eukaryotic genomes
RechenmannFrançoisIf it is possible to have verygood predictions for bacterial genes, it's certainly not the caseyet for eukaryotic genomes. Eukaryotic cells have manydifferences in comparison to prokaryotic cells. You
-
4.10. How efficient is this algorithm?
RechenmannFrançoisWe have seen the principle of an iterative algorithm in two paths for aligning and comparing two sequences of characters, here DNA sequences. And we understoodwhy the iterative version is much more
-
5.7. The application domains in microbiology
RechenmannFrançoisBioinformatics relies on many domains of mathematics and computer science. Of course, algorithms themselves on character strings are important in bioinformatics, we have seen them. Algorithms and
-
1.1. The cell, atom of the living world
RechenmannFrançoisWelcome to this introduction to bioinformatics. We will speak of genomes and algorithms. More specifically, we will see how genetic information can be analysed by algorithms. In these five weeks to
-
1.9. Predicting the origin of DNA replication?
RechenmannFrançoisWe have seen a nice algorithm to draw, let's say, a DNA sequence. We will see that first, we have to correct a little bit this algorithm. And then we will see how such as imple algorithm can provide
-
2.8. DNA sequencing
RechenmannFrançoisDuring the last session, I explained several times how it was important to increase the efficiency of sequences processing algorithm because sequences arevery long and there are large volumes of
-
3.5. Making the predictions more reliable
RechenmannFrançoisWe have got a bacterial gene predictor but the way this predictor works is rather crude and if we want to have more reliable results, we have to inject into this algorithmmore biological knowledge. We
-
4.6. A path is optimal if all its sub-paths are optimal
RechenmannFrançoisA sequence alignment between two sequences is a path in a grid. So that, an optimal sequence alignmentis an optimal path in the same grid. We'll see now that a property of this optimal path provides
-
5.5. Differences are not always what they look like
RechenmannFrançoisThe algorithm we have presented works on an array of distance between sequences. These distances are evaluated on the basis of differences between the sequences. The problem is that behind the