Notice
3.4. Predicting all the genes in a sequence
- document 1 document 2 document 3
- niveau 1 niveau 2 niveau 3
Descriptif
We have written an algorithm whichis able to locate potential genes on a sequence but only on one phase because we are looking triplets after triplets. Now remember that the genes maybe located on different phases and on the two strands. It means that to retrieve all the genes on a genome we have to look on six different sequences, three phases on each strand. Let's looknow how we can deal with this kind of search. First we have to modify a little bit our algorithm so that instead of starting at position One, I want to introduce a variable, a parameter which could be One or Two or Three so that I can run this algorithm starting on position One, first phase, or on position Two, second phase,or on position Three, third phase. Of course if you have Four, it's still the first phase again so it's unnecessary to test the numbers Four and Five and soon, you have only threepossible phases.

Thème
Documentation
Dans la même collection
-
3.2. A simple algorithm for gene prediction
RECHENMANN François
Based on the principle we statedin the last session, we will now write in pseudo code a firstalgorithm for locating genes on a bacterial genome. Remember first how this algorithm should work, we first
-
3.6. Boyer-Moore algorithm
RECHENMANN François
We have seen how we can make gene predictions more reliable through searching for all the patterns,all the occurrences of patterns. We have seen, for example, howif we locate the RBS, Ribosome
-
3.9. Benchmarking the prediction methods
RECHENMANN François
It is necessary to underline that gene predictors produce predictions. Predictions mean that you have no guarantees that the coding sequences, the coding regions,the genes you get when applying your
-
3.3. Searching for start and stop codons
RECHENMANN François
We have written an algorithm for finding genes. But you remember that we arestill to write the two functions for finding the next stop codonand the next start codon. Let's see how we can do that. We
-
3.7. Index and suffix trees
RECHENMANN François
We have seen with the Boyer-Moore algorithm how we can increase the efficiency of spin searching through the pre-processing of the pattern to be searched. Now we will see that an alternative way of
-
3.1. All genes end on a stop codon
RECHENMANN François
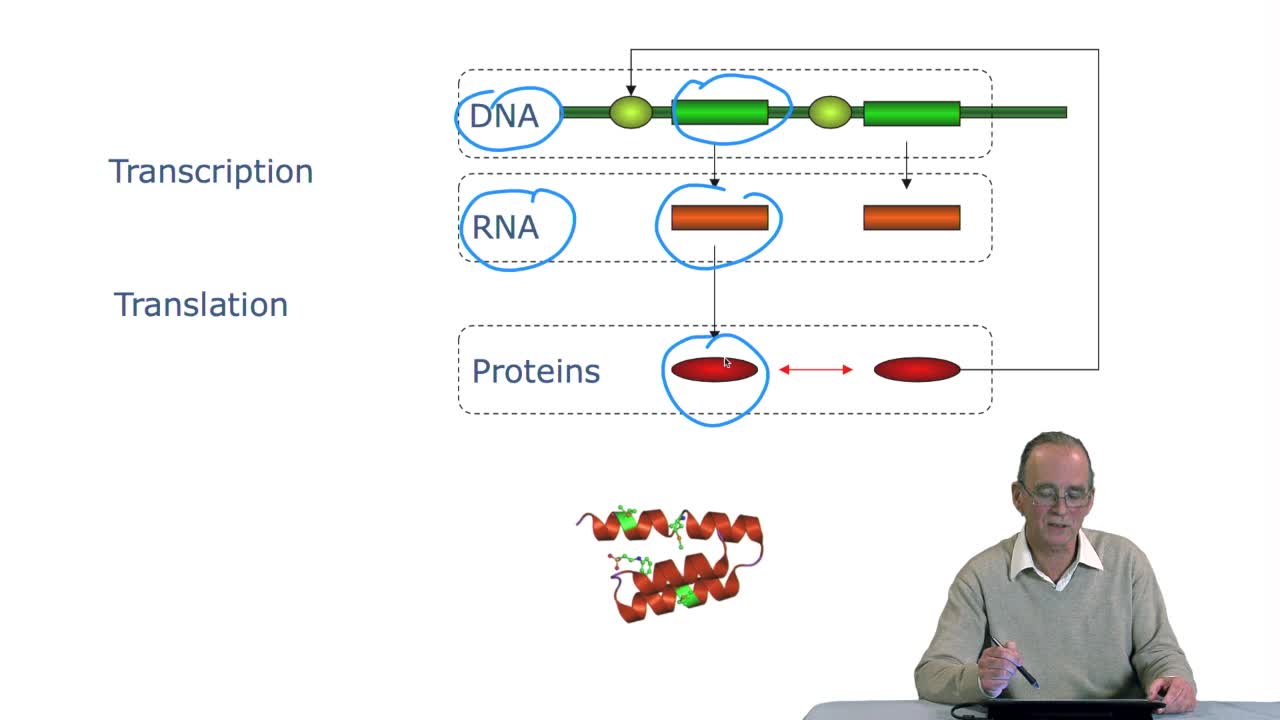
Last week we studied genes and proteins and so how genes, portions of DNA, are translated into proteins. We also saw the very fast evolutionof the sequencing technology which allows for producing
-
3.10. Gene prediction in eukaryotic genomes
RECHENMANN François
If it is possible to have verygood predictions for bacterial genes, it's certainly not the caseyet for eukaryotic genomes. Eukaryotic cells have manydifferences in comparison to prokaryotic cells. You
-
3.5. Making the predictions more reliable
RECHENMANN François
We have got a bacterial gene predictor but the way this predictor works is rather crude and if we want to have more reliable results, we have to inject into this algorithmmore biological knowledge. We
-
3.8. Probabilistic methods
RECHENMANN François
Up to now, to predict our gene,we only rely on the process of searching certain strings or patterns. In order to further improve our gene predictor, the idea is to use, to rely onprobabilistic methods









Avec les mêmes intervenants et intervenantes
-
1.7. DNA walk
RECHENMANN François
We will now design a more graphical algorithm which is called "the DNA walk". We shall see what does it mean "DNA walk". Walk on to DNA. Something like that, yes. But first, just have a look again at
-
2.6. Algorithms + data structures = programs
RECHENMANN François
By writing the Lookup GeneticCode Function, we completed our translation algorithm. So we may ask the question about the algorithm, does it terminate? Andthe answer is yes, obviously. Is it pertinent,
-
3.3. Searching for start and stop codons
RECHENMANN François
We have written an algorithm for finding genes. But you remember that we arestill to write the two functions for finding the next stop codonand the next start codon. Let's see how we can do that. We
-
4.7. Alignment costs
RECHENMANN François
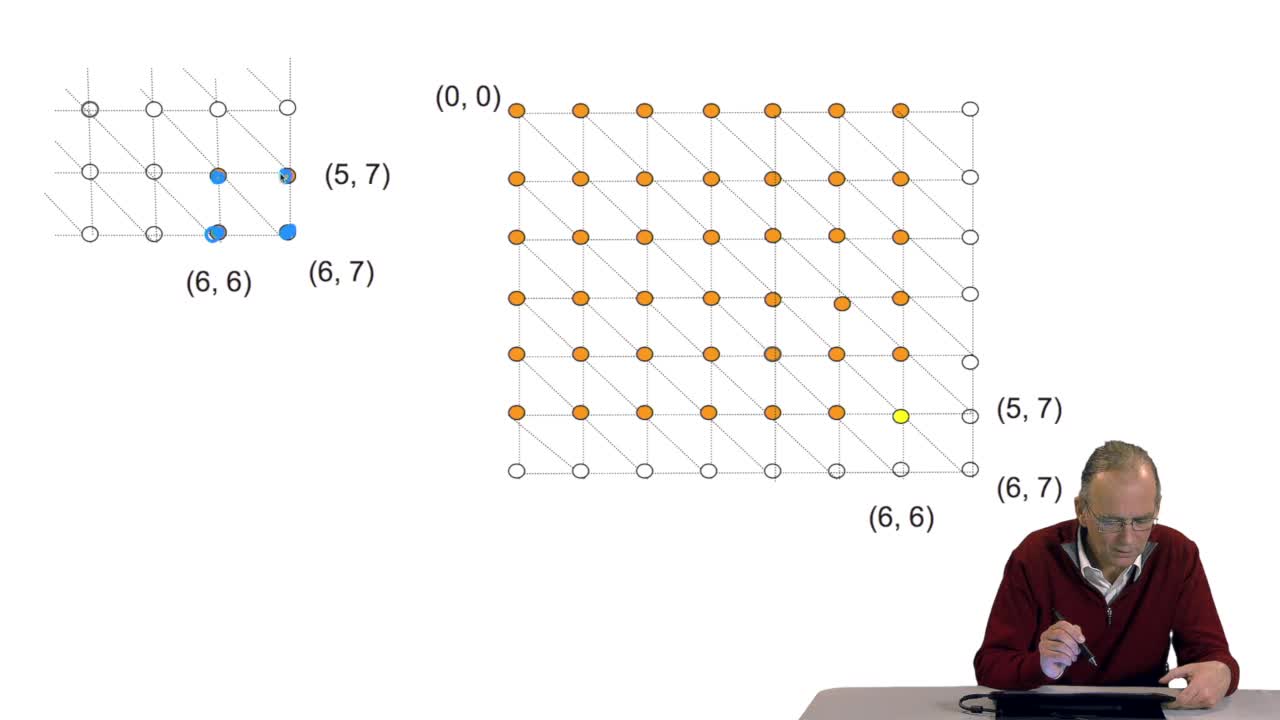
We have seen how we can compute the cost of the path ending on the last node of our grid if we know the cost of the sub-path ending on the three adjacent nodes. It is time now to see more deeply why
-
4.9. Recursion can be avoided: an iterative version
RECHENMANN François
We have written a recursive function to compute the optimal path that is an optimal alignment between two sequences. Here all the examples I gave were onDNA sequences, four letter alphabet. OK. The
-
1.2. At the heart of the cell: the DNA macromolecule
RECHENMANN François
During the last session, we saw how at the heart of the cell there's DNA in the nucleus, sometimes of cells, or directly in the cytoplasm of the bacteria. The DNA is what we call a macromolecule, that
-
1.10. Overlapping sliding window
RECHENMANN François
We have made some drawings along a genomic sequence. And we have seen that although the algorithm is quite simple, even if some points of the algorithmare bit trickier than the others, we were able to
-
2.3. The genetic code
RECHENMANN François
Genes code for proteins. What is the correspondence betweenthe genes, DNA sequences, and the structure of proteins? The correspondence isthe genetic code. Proteins have indeedsequences of amino acids.
-
3.7. Index and suffix trees
RECHENMANN François
We have seen with the Boyer-Moore algorithm how we can increase the efficiency of spin searching through the pre-processing of the pattern to be searched. Now we will see that an alternative way of
-
4.4. Aligning sequences is an optimization problem
RECHENMANN François
We have seen a nice and a quitesimple solution for measuring the similarity between two sequences. It relied on the so-called hammingdistance that is counting the number of differencesbetween two
-
5.2. The tree, an abstract object
RECHENMANN François
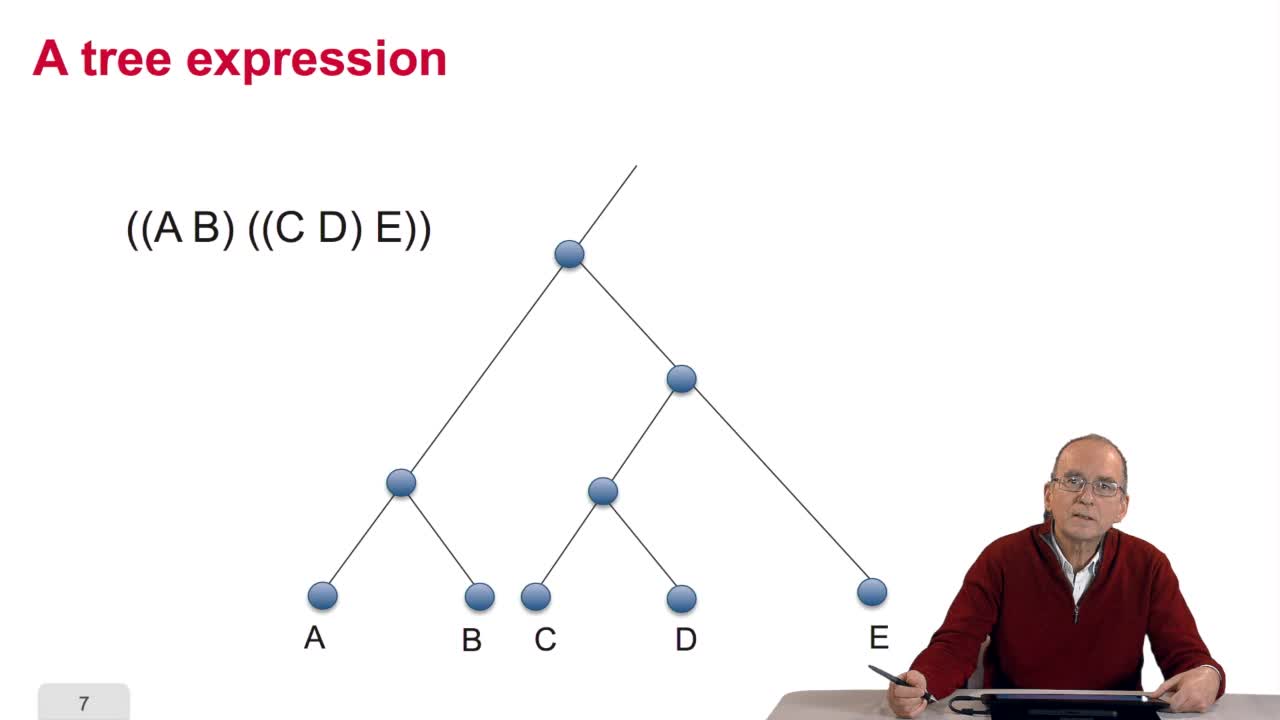
When we speak of trees, of species,of phylogenetic trees, of course, it's a metaphoric view of a real tree. Our trees are abstract objects. Here is a tree and the different components of this tree.
-
1.5. Counting nucleotides
RECHENMANN François
In this session, don't panic. We will design our first algorithm. This algorithm is forcounting nucleotides. The idea here is that as an input,you have a sequence of nucleotides, of bases, of letters,