Notice
Biological Networks Entropies: examples in neural, genetic and social networks
- document 1 document 2 document 3
- niveau 1 niveau 2 niveau 3
Descriptif
The networks used in biological applications at different scales (molecular, cellular and populational) are of different types, genetic, neuronal, and social, but they share the same dynamical concepts, the notion of intercation graph G(J) associated to their Jacobian matrix J, and also the concepts of frustrated nodes, positive or negative circuits of G(J), kinetic energy, entropy, attractors, structural stability, etc...are relevant and useful for studying the dynamics and the robustness of these systems.
We will give some general results available for both continuous and discrete biologial networks and then, give some specific applications (a neural network involved in the memory evocation, a genetic network responsible of the Iron control and a social network accounting for the obesity spread in a high school environment).

Thème
Documentation
Documents pédagogiques
Liens
Sur le même thème
-
Le projet dnarXiv : Stockage de données sur des molécules d'ADN
LavenierDominiqueDuprazElsaLeblancJulienCoatrieuxGouenouDominique Lavenier, Elsa Dupraz, Julien Leblanc et Gouenou Coatrieux nous présentent le projet dnarXiv, un projet porté par le LabEx CominLabs qui explore le stockage de données sur des molécules d
-
21 Molecular Algorithms Using Reprogrammable DNA Self-Assembly
WoodsDamienThe history of computing tells us that computers can be made of almost anything: silicon, gears and levers, neurons, flowing water, interacting particles or even light. Although lithographically
-
Des métiers de la bio-informatique
Courtes vidéos pour sensibiliser le jeune public aux débouchés/métiers de la filière numérique et pour promouvoir les sciences du numérique, plus globalement les carrières scientifiques.L'objectif est
-
Reasoning over large-scale biological systems with heterogeneous and incomplete data
SiegelAnneData produced by the domain of life sciences in the next decade are expected to be highly challenging. In addition to scalability issues which are shared with other applications domains, data produced
-
Génomique et informatique
RislerJean-LoupLa presse généraliste, et bien entendu la presse spécialisée, se font régulièrement l'écho du séquençage complet d'un nouveau génome. Il est cependant impossible pour le grand public de se rendre
-
Apport de l'informatique à la génomique des cancers
ViariAlainLa plupart des gènes de notre génome sont présents en deux copies (une sur chaque chromosome homologue). Dans un génome tumoral, en revanche, il est fréquent d'observer soit des pertes soit, au
-
1.4. Qu’est-ce qu’un algorithme ?
RechenmannFrançoisParmentelatThierryLes génomes peuvent donc être vus comme une longue suite de lettres écrites dans l'alphabet : A, C, G et T. Comment interpréter ces textes ? Ça va être le sujet de la bio-informatique à l'aide d
-
2.2. Les gènes, de Mendel à la biologie moléculaire
RechenmannFrançoisParmentelatThierryLa séquence de caractères est un bon modèle de l'ADN, un des modèles possibles de l'ADN et il est bon parce qu'il est utile. On va voir en particulier que ce modèle simple peut servir de support à de
-
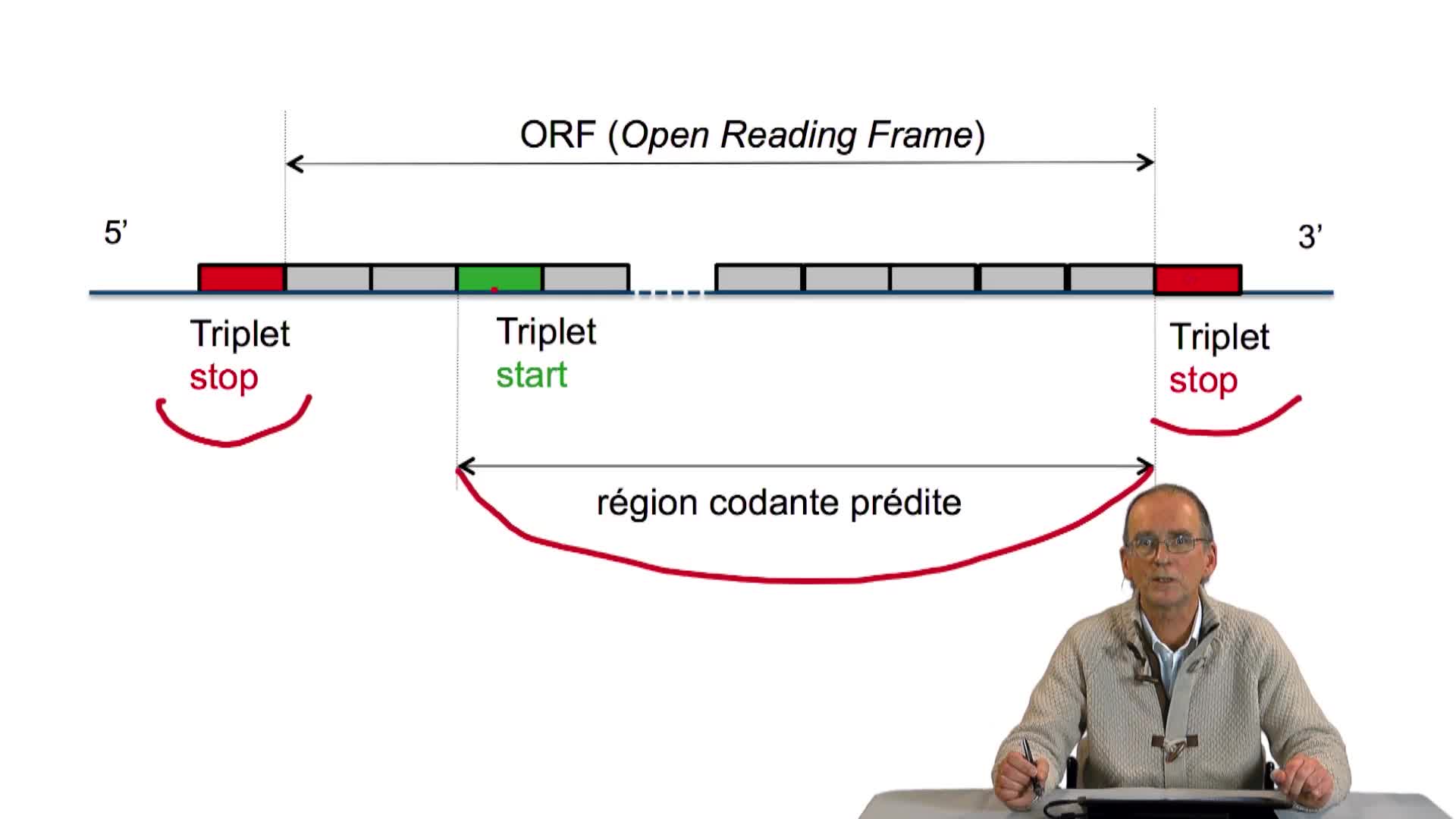
3.1. Tous les gènes se terminent sur un codon stop
RechenmannFrançoisParmentelatThierryUne fois la séquence d'un génome complet obtenue, débute la phase d'annotation. L'annotation elle-même consiste tout d'abord à rechercher la localisation, c'est-à-dire la position des gènes sur cette
-
3.2. Un algorithme simple de prédiction de gènes
RechenmannFrançoisParmentelatThierrySur la base des principes énoncés précédemment, nous allons écrire un premier algorithme de prédiction de gènes sur un texte génomique procaryote. Je rappelle ces principes. L'idée est la suivante :
-
4.2. Évolution et similarité de séquences
RechenmannFrançoisParmentelatThierryAvant de chercher à quantifier ce qu'est la similarité de séquence, on peut se poser la question même de savoir pourquoi des séquences de génome sont similaires entre organismes. La réponse tient dans
-
4.4. L’alignement de séquences devient un problème d’optimisation
RechenmannFrançoisParmentelatThierryLa distance de Hamming nous donne une première possibilité de mesurer la similarité entre 2 séquences. Mais elle ne reflète pas suffisamment la réalité biologique. Qu'est-ce que j'entends par là ? On