Notice
4.2. Évolution et similarité de séquences
- document 1 document 2 document 3
- niveau 1 niveau 2 niveau 3
Descriptif
Avant de chercher à quantifier ce qu'est la similarité de séquence, on peut se poser la question même de savoir pourquoi des séquences de génome sont similaires entre organismes. La réponse tient dans la théorie de l'évolution que l'on doit à Charles Darwin. Que dit Charles Darwin et que disent les biologistes évolutionnistes actuellement ? Ils disent que les espèces évoluent. Une espèce, par spéciation, donne naissance à 2 autres espèces qui évoluent et ainsi de suite. D'où cet arbre du vivant qu'esquissait déjà Darwin, grand penseur, dans ses carnets.
En pratique, que cela signifie-t-il ? On peut figurer l'arbre des espèces sous la forme d'un arbre informatique, on y reviendra la semaine prochaine, où figurent aux nœuds, les espèces. Ici existe une espèce qui, par ce processus dit de spéciation, évolue sous la forme de 2 espèces distinctes. Celle-ci évolue encore sous forme de 2 espèces distinctes et ainsi de suite. Le temps figure là puisque cette espèce-là existe à un moment donné, donne lieu à 2 autres espèces de façon ultérieure et ainsi de suite...
Intervention / Responsable scientifique


Dans la même collection
-
4.6. Si un chemin est optimal, tous ses chemins partiels sont optimaux
RechenmannFrançoisParmentelatThierryNous cherchons à concevoir un algorithme capable de déterminer l'alignement optimal de 2 séquences. Et nous avons vu que ça revient à chercher un algorithme qui recherche un chemin optimal dans une
-
4.9. Éviter la récursivité : une version itérative
RechenmannFrançoisParmentelatThierryLa fonction récursive que nous avons obtenue est d'un code assez compact et plutôt élégant, mais effectivement peu efficace. Pourquoi ? Rappelons son fonctionnement. Cette fonction est d'abord appelée
-
4.4. L’alignement de séquences devient un problème d’optimisation
RechenmannFrançoisParmentelatThierryLa distance de Hamming nous donne une première possibilité de mesurer la similarité entre 2 séquences. Mais elle ne reflète pas suffisamment la réalité biologique. Qu'est-ce que j'entends par là ? On
-
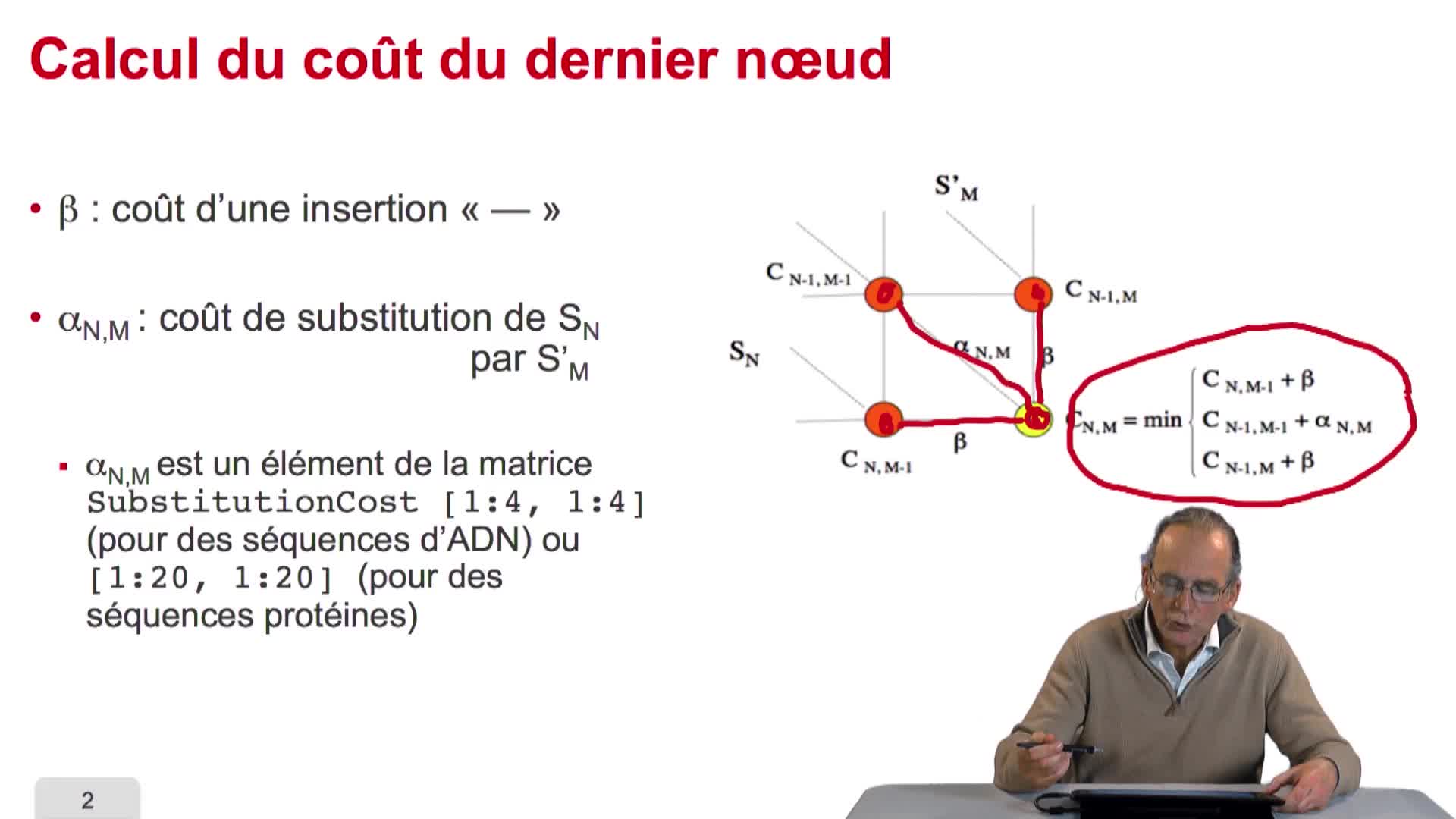
4.7. Coûts et alignement
RechenmannFrançoisParmentelatThierryNous avons vu l'ébauche de notre algorithme d'alignement optimal en considérant la possibilité de calculer le coût optimal, ou score optimal, de ce dernier noeud. Et nous avons vu que le coût de ce
-
4.1. Comment prédire les fonctions des gènes/protéines ?
RechenmannFrançoisParmentelatThierryAprès avoir regardé dans les yeux, les semaines précédentes, l'ADN, vu comment cet ADN par séquençage produisait des textes, des séquences génomiques, étudié la relation entre gènes et protéines,
-
4.10. Cet algorithme est-il efficace ?
RechenmannFrançoisParmentelatThierryLa version itérative de notre algorithme d'alignement optimal de séquences est indéniablement beaucoup plus efficace que sa version récursive, puisque nous avons vu qu'il permettait d'éviter que le
-
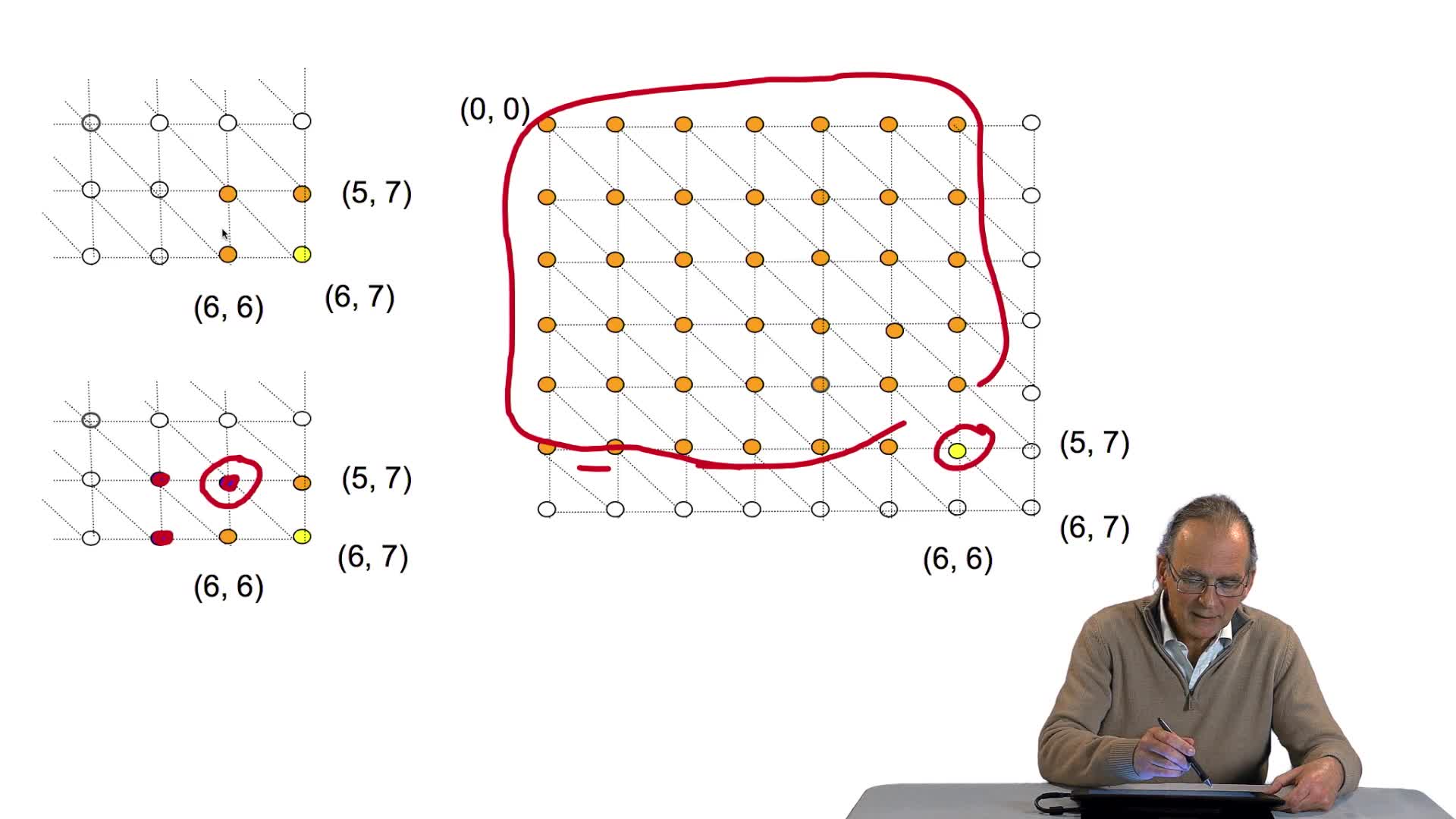
4.5. Un alignement de séquences vu comme un chemin dans une grille
RechenmannFrançoisParmentelatThierryPour comparer deux séquences entre elles, il faut donc les aligner. Aligner ces deux séquences suppose faire des hypothèses d'insertion, délétion, aux bons endroits. Ça signifie, d'un point de vue
-
4.8. Un algorithme récursif
RechenmannFrançoisParmentelatThierryNous avons désormais en main tous les éléments pour écrire notre algorithme de détermination d'un alignement optimal, ici d'un chemin optimal. Avec les notations que nous avons introduites, je vous
-
4.3. Quantifier la similarité de deux séquences
RechenmannFrançoisParmentelatThierryLe principe est donc de rechercher, dans les bases de données, des séquences similaires à celles que nous sommes en train d'étudier. Nous faisons aussi l'hypothèse que plus les séquences sont






Avec les mêmes intervenants et intervenantes
-
1.3. DNA codes for genetic information
RechenmannFrançoisRemember at the heart of any cell,there is this very long molecule which is called a macromolecule for this reason, which is the DNA molecule. Now we will see that DNA molecules support what is called
-
2.1. The sequence as a model of DNA
RechenmannFrançoisWelcome back to our course on genomes and algorithms that is a computer analysis ofgenetic information. Last week we introduced the very basic concept in biology that is cell, DNA, genome, genes
-
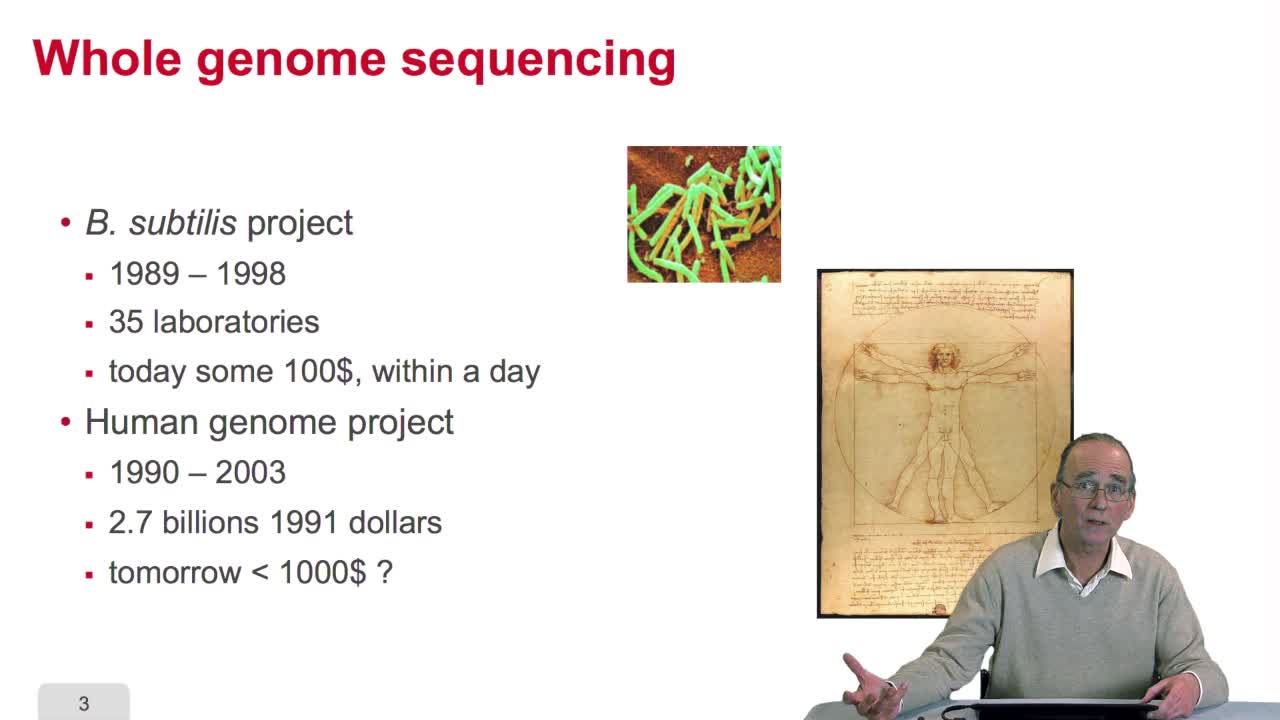
2.9. Whole genome sequencing
RechenmannFrançoisSequencing is anexponential technology. The progresses in this technologyallow now to a sequence whole genome, complete genome. What does it mean? Well let'stake two examples: some twenty years ago,
-
3.7. Index and suffix trees
RechenmannFrançoisWe have seen with the Boyer-Moore algorithm how we can increase the efficiency of spin searching through the pre-processing of the pattern to be searched. Now we will see that an alternative way of
-
4.4. Aligning sequences is an optimization problem
RechenmannFrançoisWe have seen a nice and a quitesimple solution for measuring the similarity between two sequences. It relied on the so-called hammingdistance that is counting the number of differencesbetween two
-
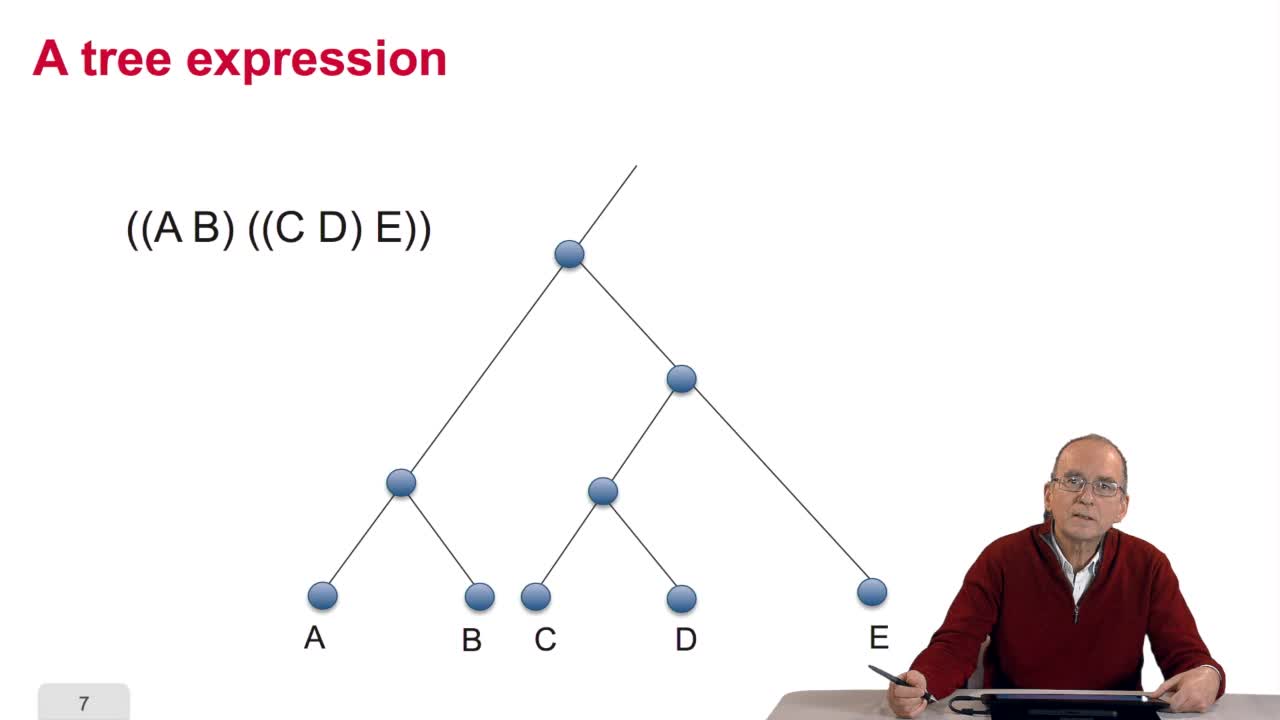
5.2. The tree, an abstract object
RechenmannFrançoisWhen we speak of trees, of species,of phylogenetic trees, of course, it's a metaphoric view of a real tree. Our trees are abstract objects. Here is a tree and the different components of this tree.
-
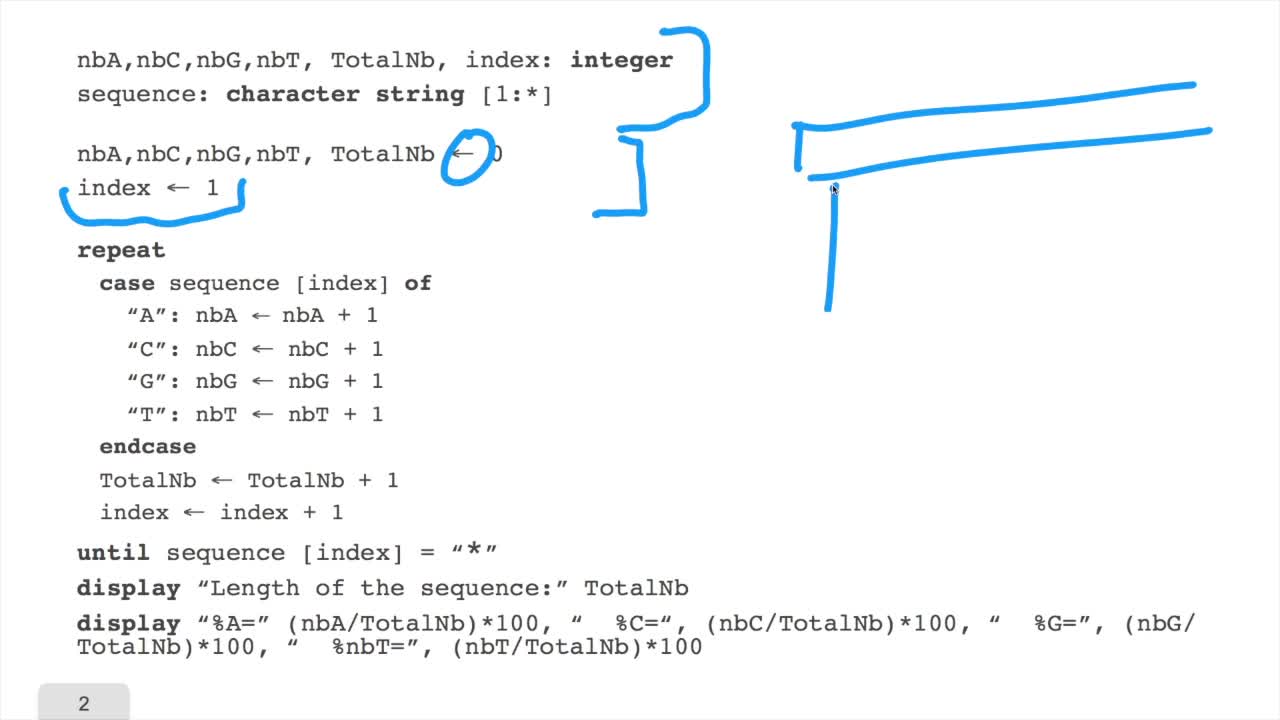
1.6. GC and AT contents of DNA sequence
RechenmannFrançoisWe have designed our first algorithmfor counting nucleotides. Remember, what we have writtenin pseudo code is first declaration of variables. We have several integer variables that are variables which
-
2.5. Implementing the genetic code
RechenmannFrançoisRemember we were designing our translation algorithm and since we are a bit lazy, we decided to make the hypothesis that there was the adequate function forimplementing the genetic code. It's now time
-
3.2. A simple algorithm for gene prediction
RechenmannFrançoisBased on the principle we statedin the last session, we will now write in pseudo code a firstalgorithm for locating genes on a bacterial genome. Remember first how this algorithm should work, we first
-
3.10. Gene prediction in eukaryotic genomes
RechenmannFrançoisIf it is possible to have verygood predictions for bacterial genes, it's certainly not the caseyet for eukaryotic genomes. Eukaryotic cells have manydifferences in comparison to prokaryotic cells. You
-
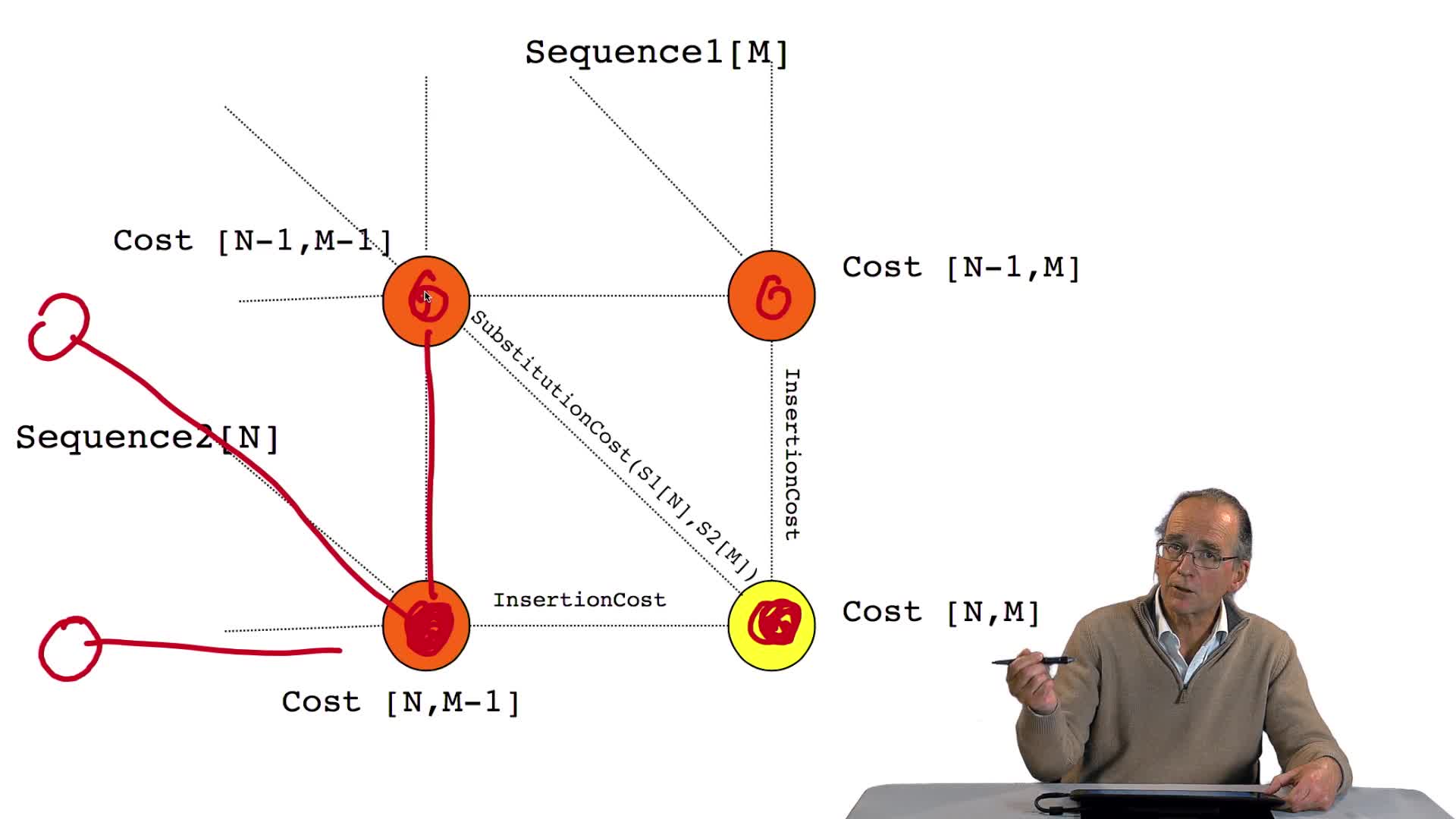
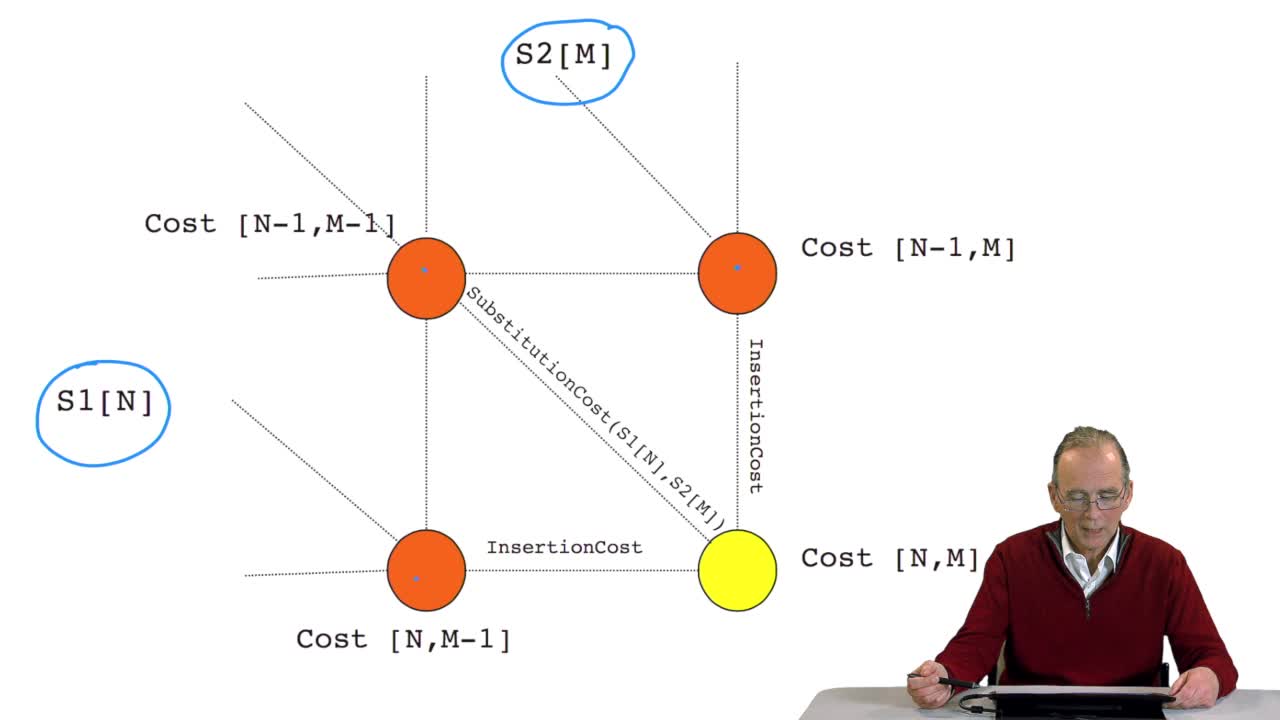
4.8. A recursive algorithm
RechenmannFrançoisWe have seen how we can computethe optimal cost, the ending node of our grid if we know the optimal cost of the three adjacent nodes. This is this computation scheme we can see here using the notation
-
5.6. The diversity of bioinformatics algorithms
RechenmannFrançoisIn this course, we have seen a very little set of bioinformatic algorithms. There exist numerous various algorithms in bioinformatics which deal with a large span of classes of problems. For example,







Sur le même thème
-
La voix, une donnée identifiante à protéger
VincentEmmanuelEmmanuel Vincent, chercheur au Centre Inria de l'Université de Lorraine et au Loria (Laboratoire lorrain de recherche en informatique et ses applications), présente sa recherche sur l'anonymisation de
-
Podcast 1/4 d'heure avec : Emmanuel Vincent, chercheur au Centre Inria de l'Université de Lorraine …
VincentEmmanuelRencontre avec Emmanuel Vincent - chercheur au Centre Inria de l'Université de Lorraine et Loria (Laboratoire lorrain de recherche en informatique et ses applications).
-
Stockage de données numériques sur ADN synthétique : Introduction au domaine
AntoniniMarcDuprazElsaLavenierDominiquePrésentation globale des différentes étapes du stockage de données sur des molécules d'ADN synthétique
-
Stockage de données numériques sur ADN synthétique : Production des données: synthèse, séquençage
LavenierDominiqueBarbryPascalDescription des opérations d'écriture et de lecture des molécules d'ADN : synthèse et séquençage.
-
Stockage de données numériques sur ADN synthétique : Reconstruction des données
LavenierDominiqueTraitement des données après séquençage
-
Stockage de données numériques sur ADN synthétique : Codage Canal
DuprazElsaTechniques de codage pour le stockage de données sur ADN
-
Stockage de données numériques sur ADN synthétique : Codage Source
AntoniniMarcCodage source pour le stockage de données sur ADN synthétique
-
Stockage de données numériques sur ADN synthétique : Théorie de l'information
Kas HannaSergeQuelle quantité d'information peut-on stocker et récupérer de manière fiable dans l'ADN ?
-
The tree of life
AbbySophieLes Rencontres Exobiologiques pour Doctorants (RED) sont une école de formation sur les « bases de l'astrobiologie ». L’édition 2025 s’est tenue du 16 au 21 mars au Parc Ornithologique du Teich.
-
Machines algorithmiques, mythes et réalités
MazenodVincentVincent Mazenod, informaticien, partage le fruit de ses réflexions sur l'évolution des outils numériques, en lien avec les problématiques de souveraineté, de sécurité et de vie privée...
-
Désassemblons le numérique - #Episode11 : Les algorithmes façonnent-ils notre société ?
SchwartzArnaudLima PillaLaércioEstériePierreSalletFrédéricFerbosAudeRoumanosRayyaChraibi KadoudIkramUn an après le tout premier hackathon sur les méthodologies d'enquêtes journalistiques sur les algorithmes, ce nouvel épisode part à la rencontre de différents points de vue sur les algorithmes.
-
Les machines à enseigner. Du livre à l'IA...
BruillardÉricQue peut-on, que doit-on déléguer à des machines ? C'est l'une des questions explorées par Éric Bruillard qui, du livre aux IA génératives, expose l'évolution des machines à enseigner...











