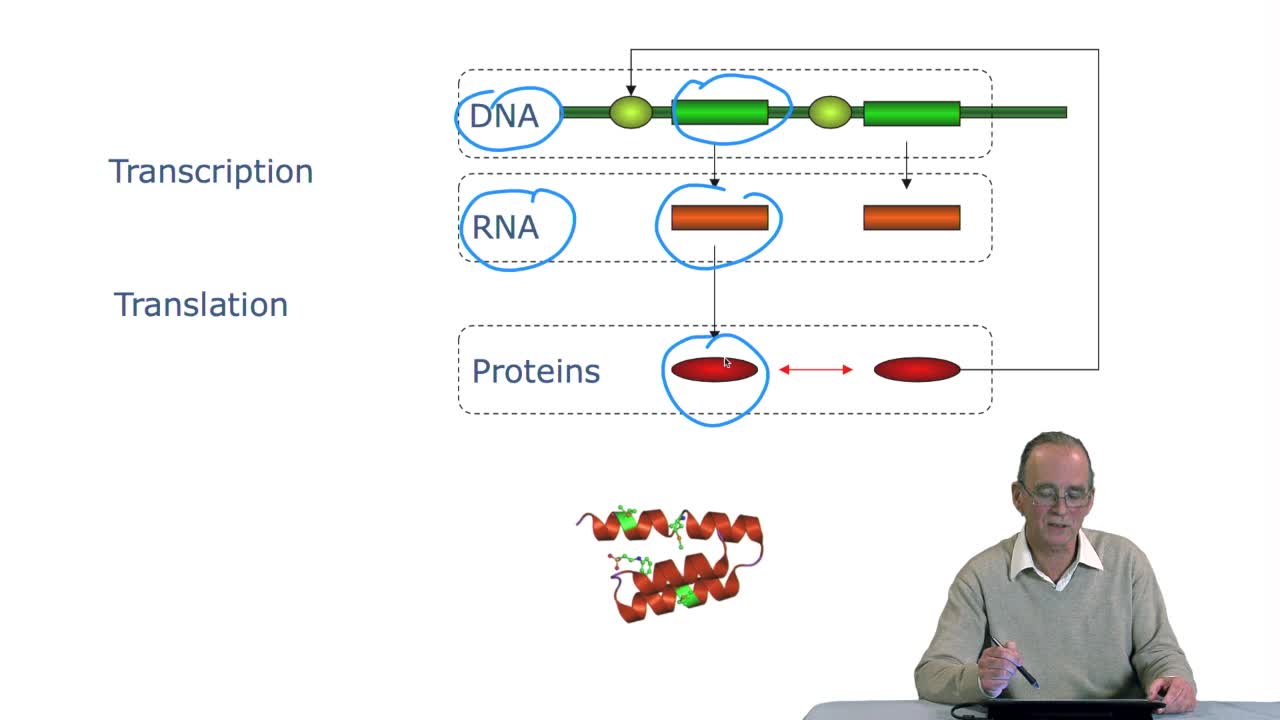
Notice
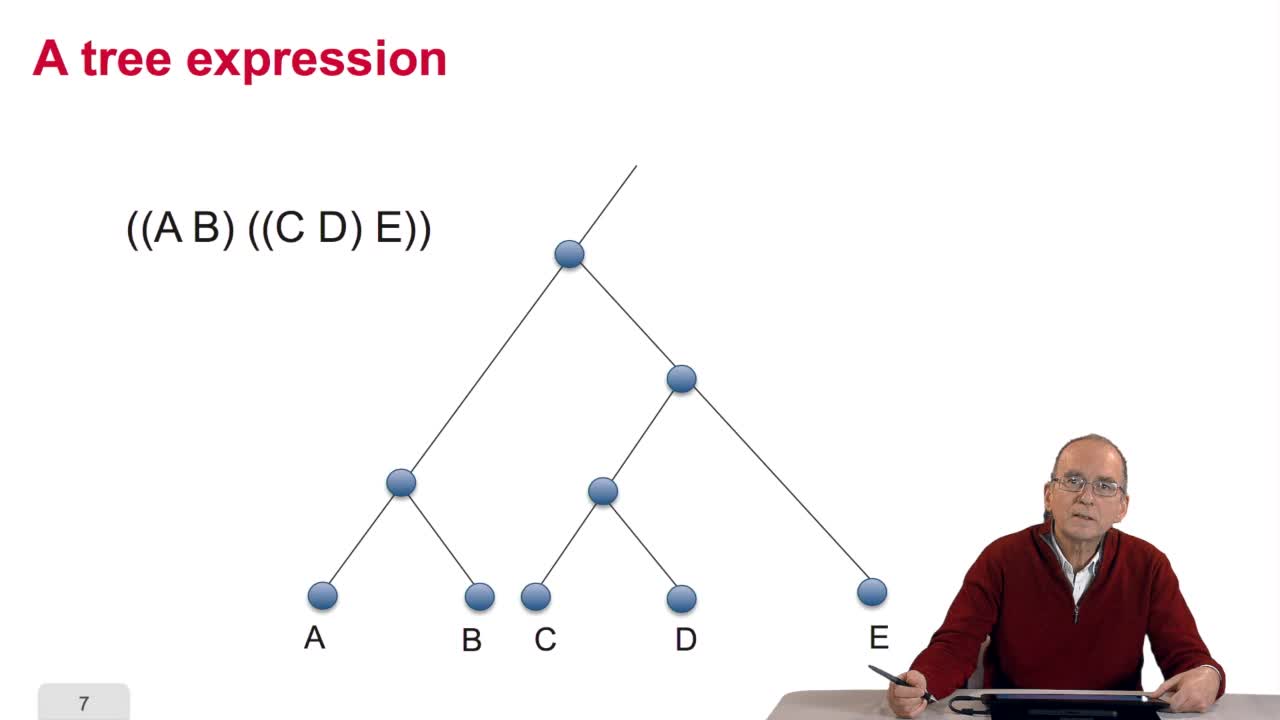
4.5. A sequence alignment as a path
- document 1 document 2 document 3
- niveau 1 niveau 2 niveau 3
Descriptif
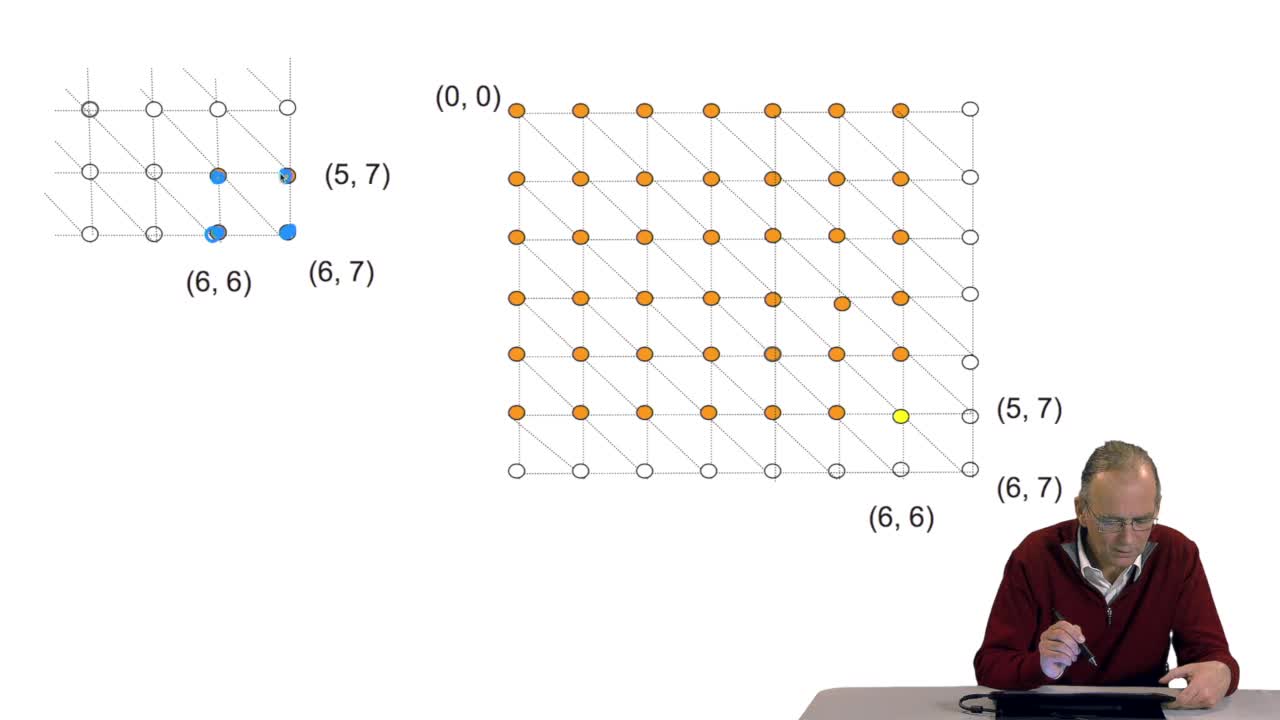
Comparing two sequences and thenmeasuring their similarities is an optimization problem. Why? Because we have seen thatwe have to take into account substitution and deletion. During the alignment, the comparison of the two sequences, we haveto insert blank characters at a certain position in order tohave an optimal score that is we want the sequence to be themore similar as possible. So the problem is to find whereto locate the blank character. There are many solutions and wewant to find the best one, it is an optimization problem. How do we deal with thisoptimization problem? We will consider an alignmentbetween two sequences as a path in that kind of grid. Here we havethe characters of the first sequence and there, the charactersof the second sequence. The path starts from this nodeand must arrive on that node. What are the rules of the game? You may have unitary path likethat or like that or like that, along, horizontal or vertical linesor diagonal lines and so on. The idea is to arrive to the lastnode and we'll see that the "S" corresponds to one alignment,one possible alignment between these two sequences. Why? Simply because drawing a diagonallike that means taking into account a substitution. Thisis the first sequence.
Intervention / Responsable scientifique

Thème
Documentation
Dans la même collection
-
4.2. Why gene/protein sequences may be similar?
RechenmannFrançoisBefore measuring the similaritybetween the sequences, it's interesting to answer the question: why gene or protein sequences may be similar? It is indeed veryinteresting because the answer is related
-
4.6. A path is optimal if all its sub-paths are optimal
RechenmannFrançoisA sequence alignment between two sequences is a path in a grid. So that, an optimal sequence alignmentis an optimal path in the same grid. We'll see now that a property of this optimal path provides
-
4.9. Recursion can be avoided: an iterative version
RechenmannFrançoisWe have written a recursive function to compute the optimal path that is an optimal alignment between two sequences. Here all the examples I gave were onDNA sequences, four letter alphabet. OK. The
-
4.3. Measuring sequence similarity
RechenmannFrançoisSo we understand why gene orprotein sequences may be similar. It's because they evolve togetherwith the species and they evolve in time, there aremodifications in the sequence and that the sequence
-
4.7. Alignment costs
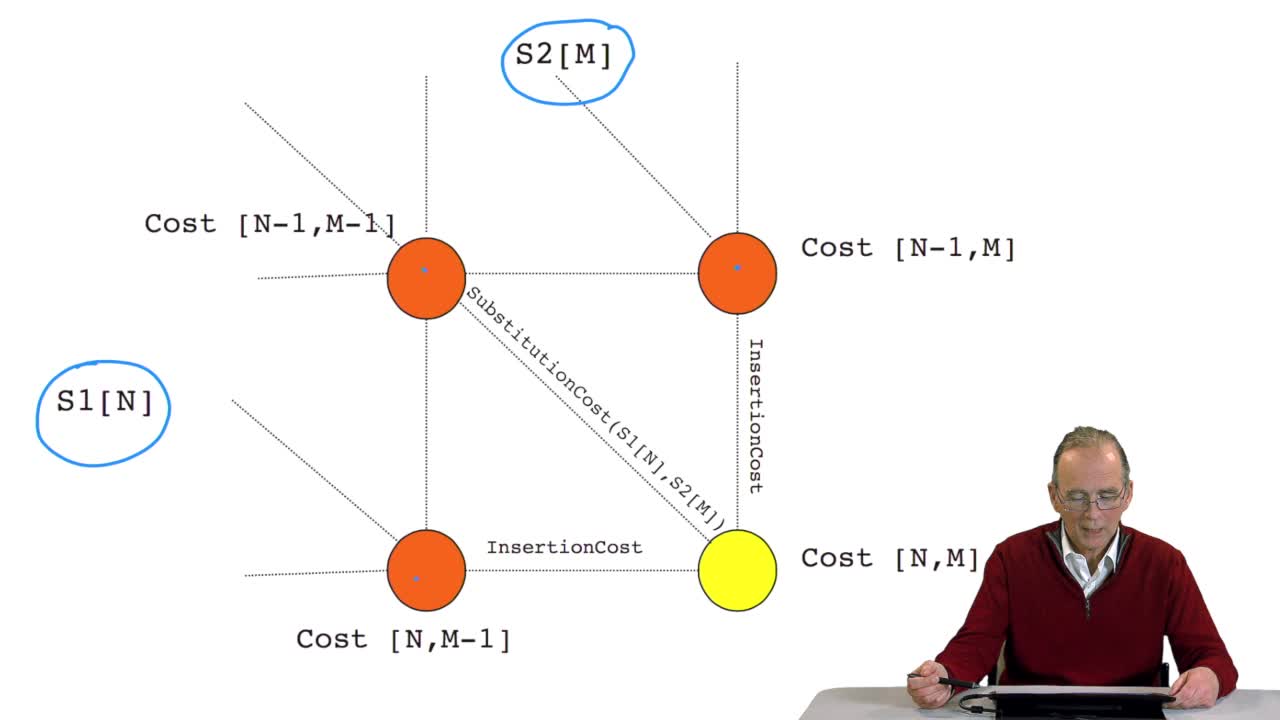
RechenmannFrançoisWe have seen how we can compute the cost of the path ending on the last node of our grid if we know the cost of the sub-path ending on the three adjacent nodes. It is time now to see more deeply why
-
4.1. How to predict gene/protein functions?
RechenmannFrançoisLast week we have seen that annotating a genome means first locating the genes on the DNA sequences that is the genes, the region coding for proteins. But this is indeed the first step,the next very
-
4.10. How efficient is this algorithm?
RechenmannFrançoisWe have seen the principle of an iterative algorithm in two paths for aligning and comparing two sequences of characters, here DNA sequences. And we understoodwhy the iterative version is much more
-
4.4. Aligning sequences is an optimization problem
RechenmannFrançoisWe have seen a nice and a quitesimple solution for measuring the similarity between two sequences. It relied on the so-called hammingdistance that is counting the number of differencesbetween two
-
4.8. A recursive algorithm
RechenmannFrançoisWe have seen how we can computethe optimal cost, the ending node of our grid if we know the optimal cost of the three adjacent nodes. This is this computation scheme we can see here using the notation






Avec les mêmes intervenants et intervenantes
-
1.7. DNA walk
RechenmannFrançoisWe will now design a more graphical algorithm which is called "the DNA walk". We shall see what does it mean "DNA walk". Walk on to DNA. Something like that, yes. But first, just have a look again at
-
2.6. Algorithms + data structures = programs
RechenmannFrançoisBy writing the Lookup GeneticCode Function, we completed our translation algorithm. So we may ask the question about the algorithm, does it terminate? Andthe answer is yes, obviously. Is it pertinent,
-
3.3. Searching for start and stop codons
RechenmannFrançoisWe have written an algorithm for finding genes. But you remember that we arestill to write the two functions for finding the next stop codonand the next start codon. Let's see how we can do that. We
-
4.1. How to predict gene/protein functions?
RechenmannFrançoisLast week we have seen that annotating a genome means first locating the genes on the DNA sequences that is the genes, the region coding for proteins. But this is indeed the first step,the next very
-
4.9. Recursion can be avoided: an iterative version
RechenmannFrançoisWe have written a recursive function to compute the optimal path that is an optimal alignment between two sequences. Here all the examples I gave were onDNA sequences, four letter alphabet. OK. The
-
1.2. At the heart of the cell: the DNA macromolecule
RechenmannFrançoisDuring the last session, we saw how at the heart of the cell there's DNA in the nucleus, sometimes of cells, or directly in the cytoplasm of the bacteria. The DNA is what we call a macromolecule, that
-
1.10. Overlapping sliding window
RechenmannFrançoisWe have made some drawings along a genomic sequence. And we have seen that although the algorithm is quite simple, even if some points of the algorithmare bit trickier than the others, we were able to
-
2.3. The genetic code
RechenmannFrançoisGenes code for proteins. What is the correspondence betweenthe genes, DNA sequences, and the structure of proteins? The correspondence isthe genetic code. Proteins have indeedsequences of amino acids.
-
3.6. Boyer-Moore algorithm
RechenmannFrançoisWe have seen how we can make gene predictions more reliable through searching for all the patterns,all the occurrences of patterns. We have seen, for example, howif we locate the RBS, Ribosome
-
4.4. Aligning sequences is an optimization problem
RechenmannFrançoisWe have seen a nice and a quitesimple solution for measuring the similarity between two sequences. It relied on the so-called hammingdistance that is counting the number of differencesbetween two
-
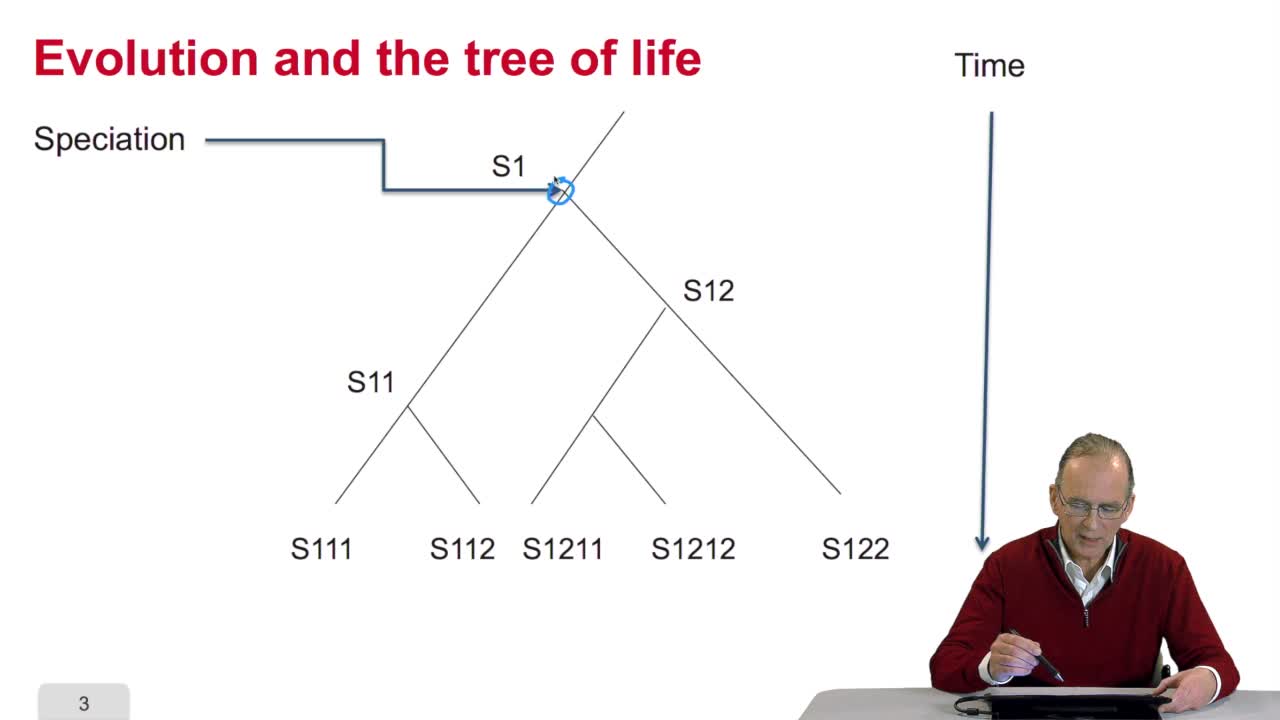
5.2. The tree, an abstract object
RechenmannFrançoisWhen we speak of trees, of species,of phylogenetic trees, of course, it's a metaphoric view of a real tree. Our trees are abstract objects. Here is a tree and the different components of this tree.
-
1.5. Counting nucleotides
RechenmannFrançoisIn this session, don't panic. We will design our first algorithm. This algorithm is forcounting nucleotides. The idea here is that as an input,you have a sequence of nucleotides, of bases, of letters,