Notice
4.6. Si un chemin est optimal, tous ses chemins partiels sont optimaux
- document 1 document 2 document 3
- niveau 1 niveau 2 niveau 3
Descriptif
Nous cherchons à concevoir un algorithme capable de déterminer l'alignement optimal de 2 séquences. Et nous avons vu que ça revient à chercher un algorithme qui recherche un chemin optimal dans une grille. Chemin optimal, c'est-à-dire de coût de score minimal.
Pour bâtir cet algorithme, nous allons nous appuyer sur une propriété de ce chemin optimal qui est la suivante : si un chemin de longueur l est optimal, alors le chemin de longueur l-1 l'est aussi. Comment prouver cette propriété ? Très simplement en fait par l'absurde. C'est-à-dire qu'on va faire l'hypothèse contraire. C'est-à-dire que si le chemin de longueur L est optimal, il se peut que le chemin de longueur L-1, qu'il existe un chemin de longueur L-1 qui ne le soit pas. Et on arrivera à une contradiction. Ce qui va montrer par l'absurde, la véracité de cette affirmation-là. On voit également qu’un chemin de longueur L-1 correspond sur l'alignement à un alignement de longueur L-1 également. Correspondance, on l'avait vu, entre alignement et chemin...
Intervention / Responsable scientifique


Dans la même collection
-
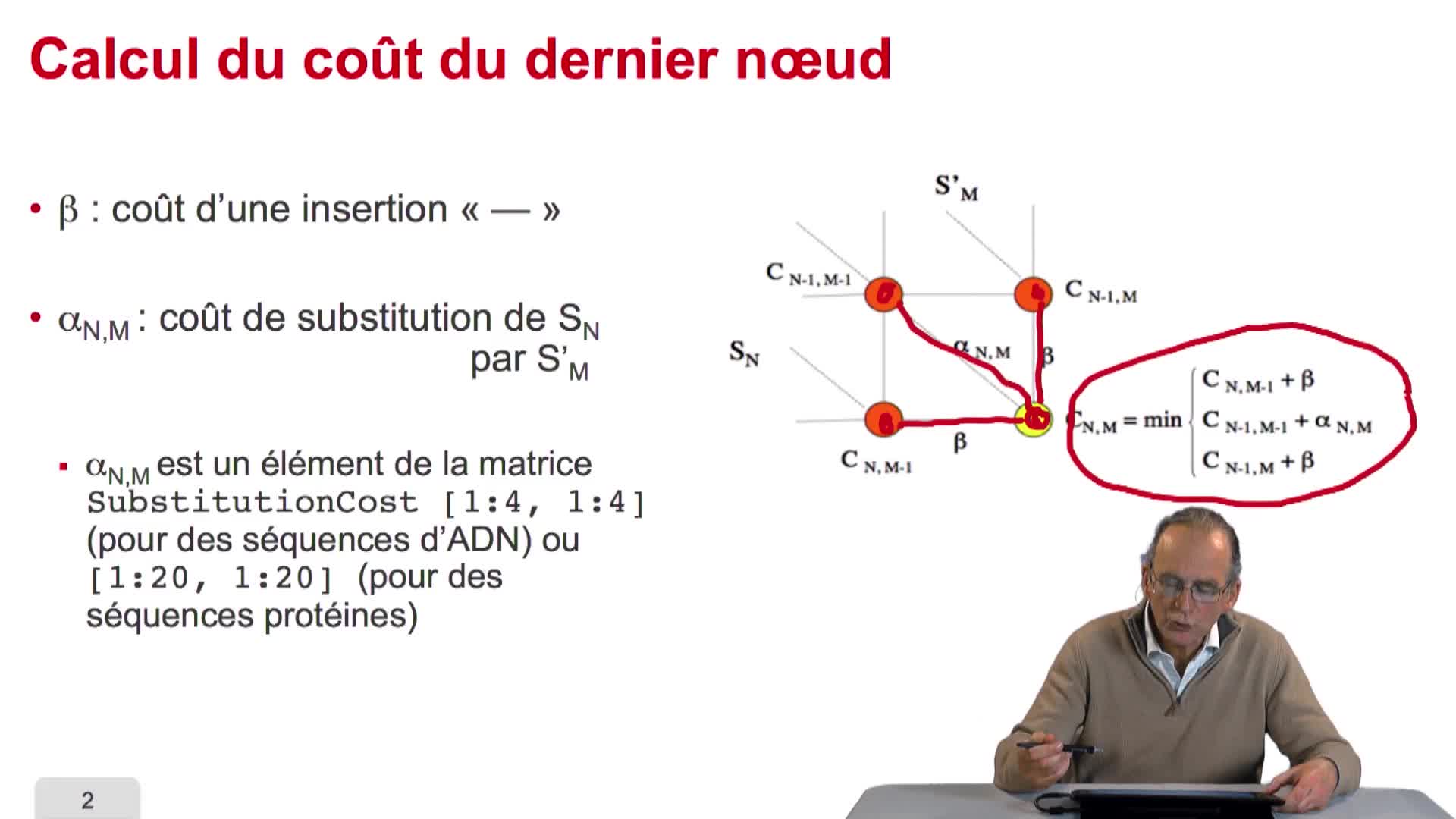
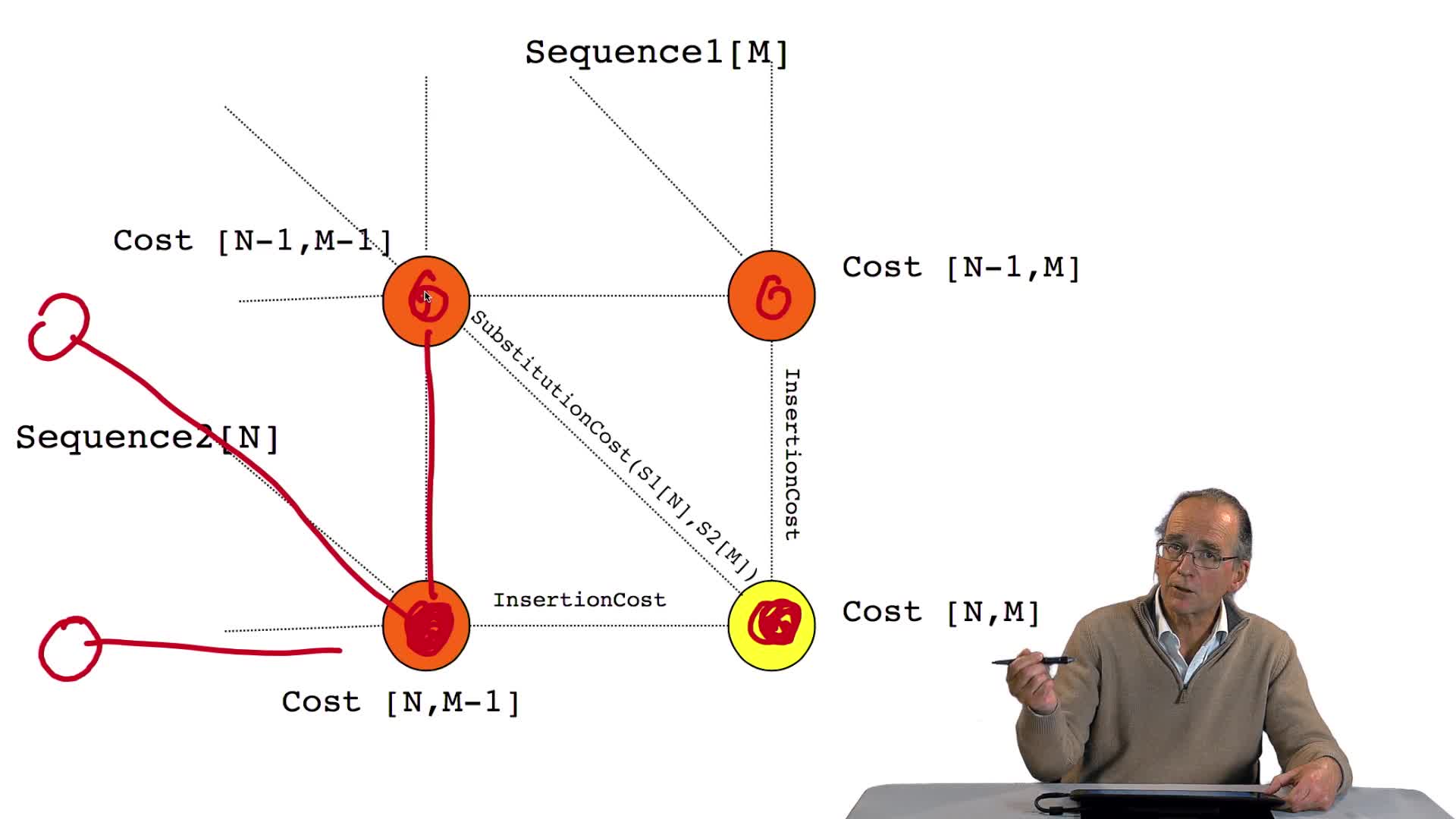
4.7. Coûts et alignement
RechenmannFrançoisParmentelatThierryNous avons vu l'ébauche de notre algorithme d'alignement optimal en considérant la possibilité de calculer le coût optimal, ou score optimal, de ce dernier noeud. Et nous avons vu que le coût de ce
-
4.1. Comment prédire les fonctions des gènes/protéines ?
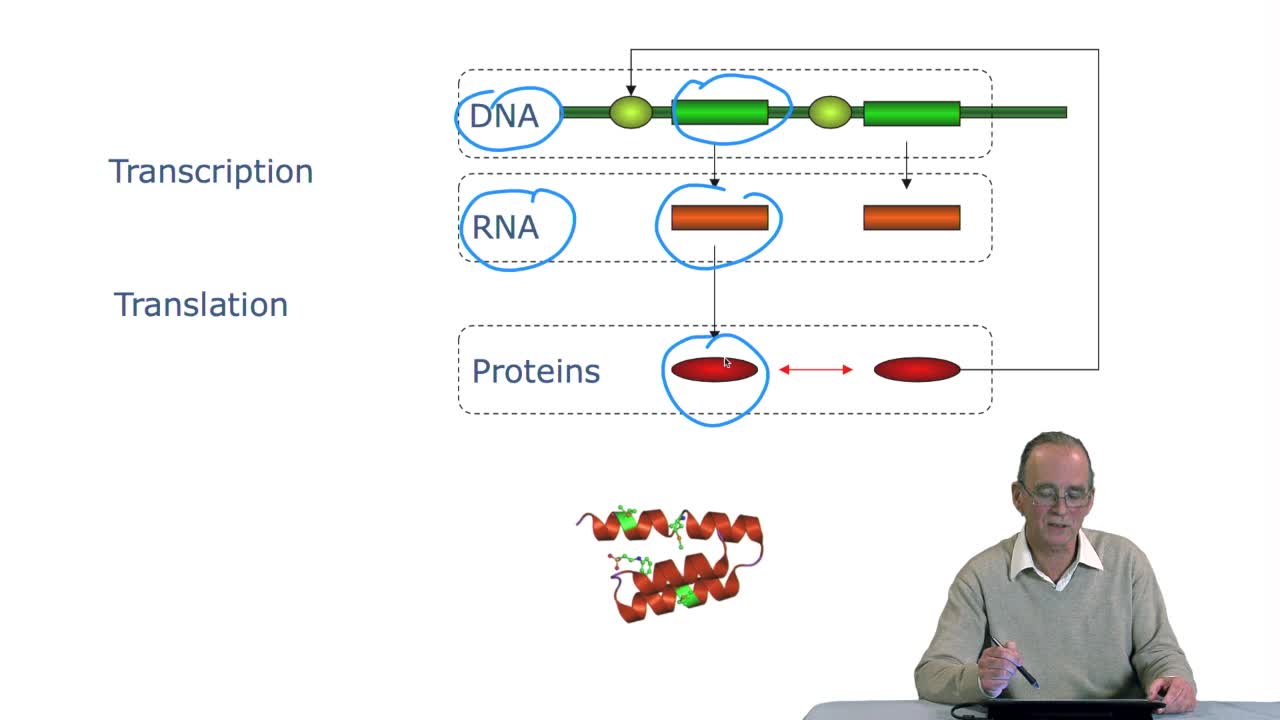
RechenmannFrançoisParmentelatThierryAprès avoir regardé dans les yeux, les semaines précédentes, l'ADN, vu comment cet ADN par séquençage produisait des textes, des séquences génomiques, étudié la relation entre gènes et protéines,
-
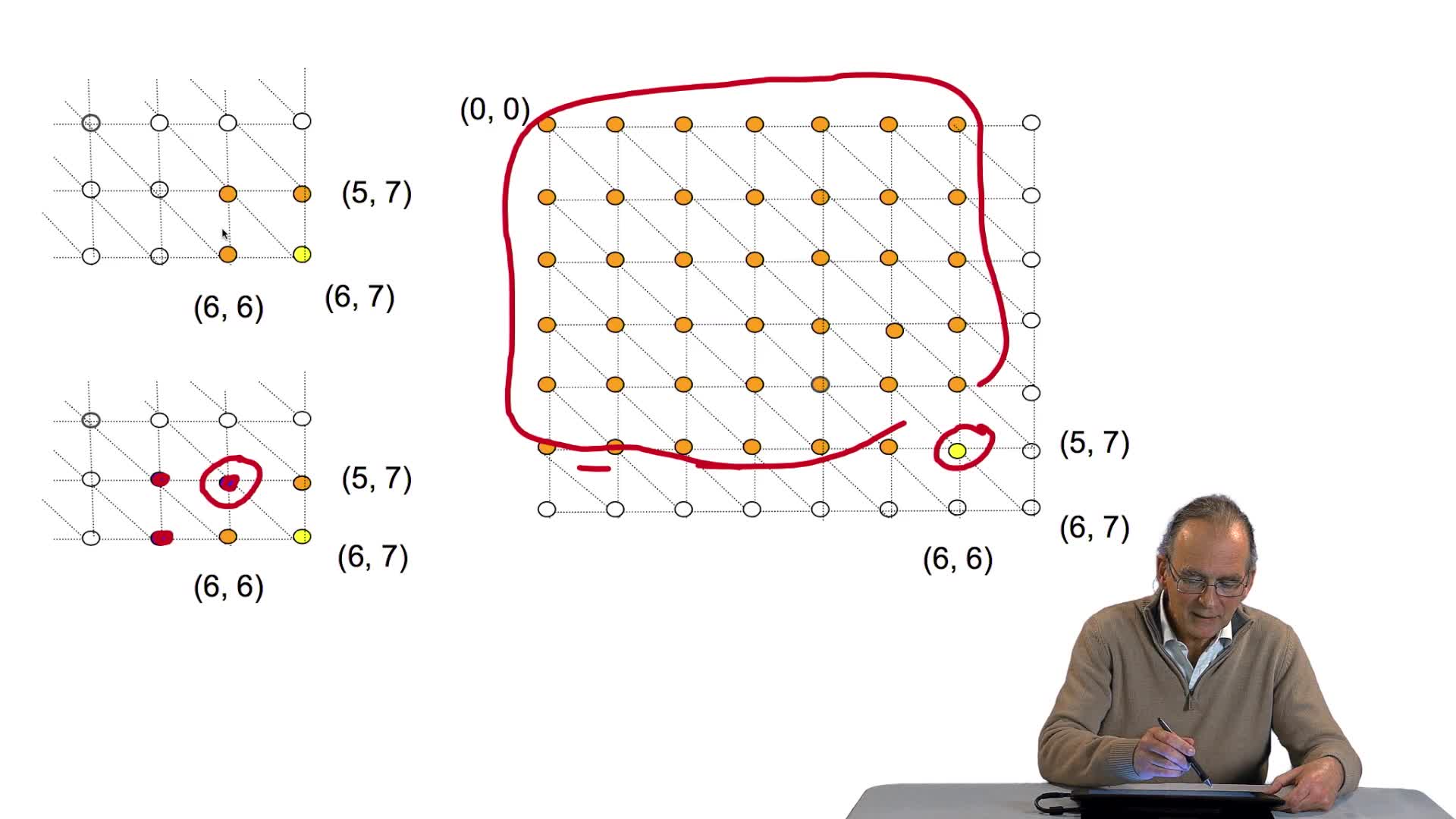
4.10. Cet algorithme est-il efficace ?
RechenmannFrançoisParmentelatThierryLa version itérative de notre algorithme d'alignement optimal de séquences est indéniablement beaucoup plus efficace que sa version récursive, puisque nous avons vu qu'il permettait d'éviter que le
-
4.4. L’alignement de séquences devient un problème d’optimisation
RechenmannFrançoisParmentelatThierryLa distance de Hamming nous donne une première possibilité de mesurer la similarité entre 2 séquences. Mais elle ne reflète pas suffisamment la réalité biologique. Qu'est-ce que j'entends par là ? On
-
4.8. Un algorithme récursif
RechenmannFrançoisParmentelatThierryNous avons désormais en main tous les éléments pour écrire notre algorithme de détermination d'un alignement optimal, ici d'un chemin optimal. Avec les notations que nous avons introduites, je vous
-
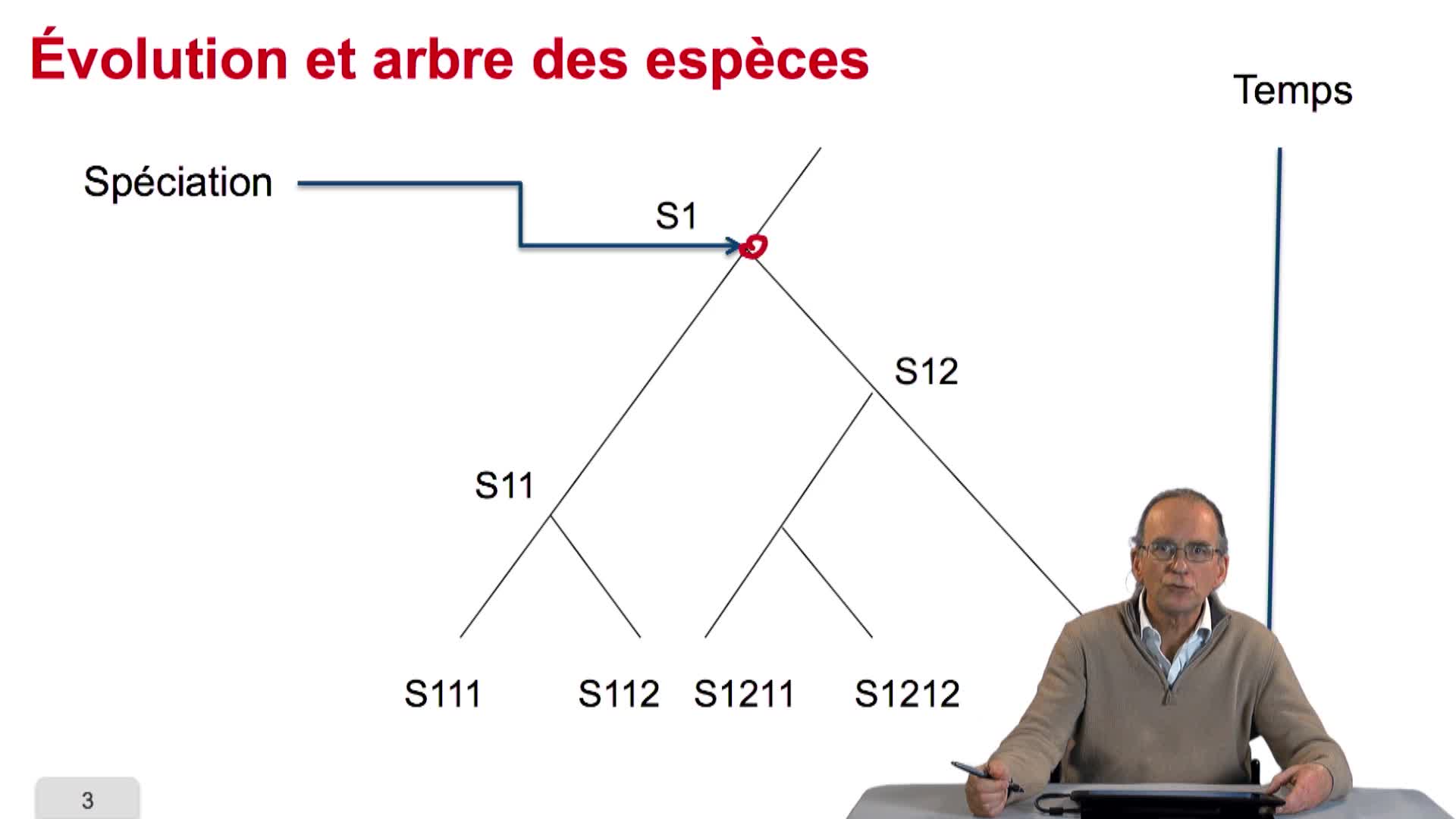
4.2. Évolution et similarité de séquences
RechenmannFrançoisParmentelatThierryAvant de chercher à quantifier ce qu'est la similarité de séquence, on peut se poser la question même de savoir pourquoi des séquences de génome sont similaires entre organismes. La réponse tient dans
-
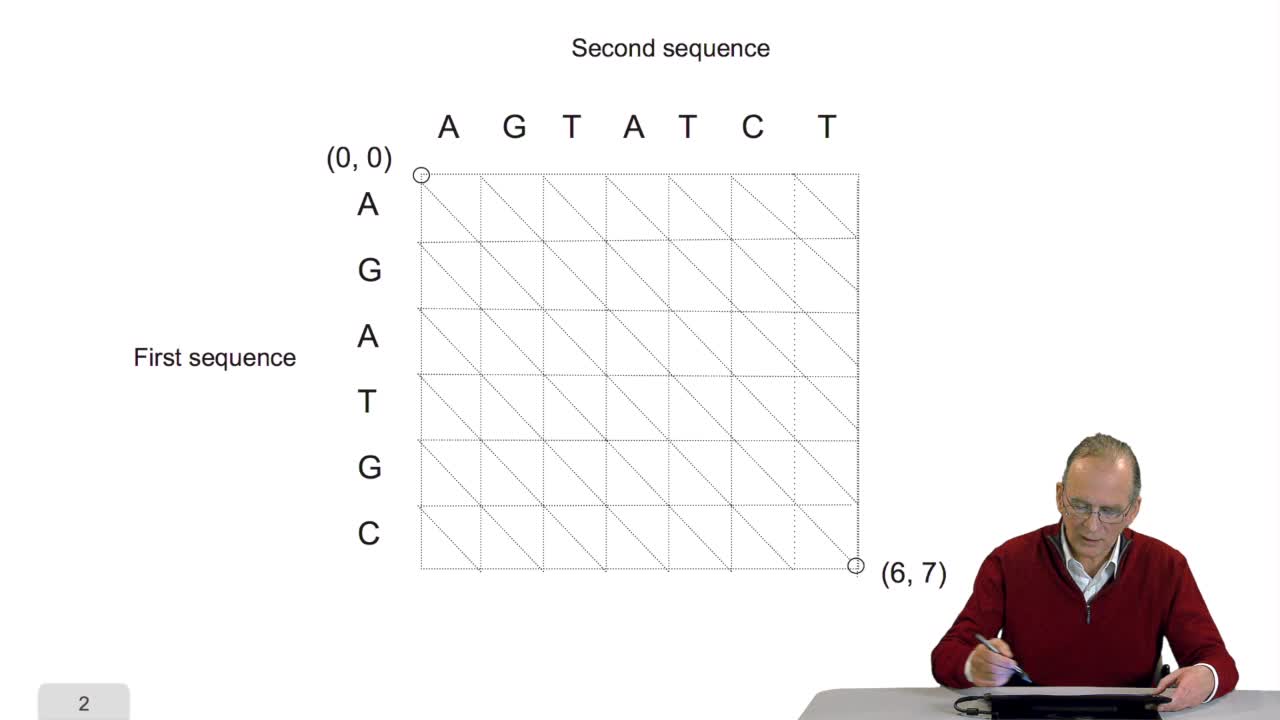
4.5. Un alignement de séquences vu comme un chemin dans une grille
RechenmannFrançoisParmentelatThierryPour comparer deux séquences entre elles, il faut donc les aligner. Aligner ces deux séquences suppose faire des hypothèses d'insertion, délétion, aux bons endroits. Ça signifie, d'un point de vue
-
4.9. Éviter la récursivité : une version itérative
RechenmannFrançoisParmentelatThierryLa fonction récursive que nous avons obtenue est d'un code assez compact et plutôt élégant, mais effectivement peu efficace. Pourquoi ? Rappelons son fonctionnement. Cette fonction est d'abord appelée
-
4.3. Quantifier la similarité de deux séquences
RechenmannFrançoisParmentelatThierryLe principe est donc de rechercher, dans les bases de données, des séquences similaires à celles que nous sommes en train d'étudier. Nous faisons aussi l'hypothèse que plus les séquences sont





Avec les mêmes intervenants et intervenantes
-
1.7. DNA walk
RechenmannFrançoisWe will now design a more graphical algorithm which is called "the DNA walk". We shall see what does it mean "DNA walk". Walk on to DNA. Something like that, yes. But first, just have a look again at
-
2.6. Algorithms + data structures = programs
RechenmannFrançoisBy writing the Lookup GeneticCode Function, we completed our translation algorithm. So we may ask the question about the algorithm, does it terminate? Andthe answer is yes, obviously. Is it pertinent,
-
3.3. Searching for start and stop codons
RechenmannFrançoisWe have written an algorithm for finding genes. But you remember that we arestill to write the two functions for finding the next stop codonand the next start codon. Let's see how we can do that. We
-
4.1. How to predict gene/protein functions?
RechenmannFrançoisLast week we have seen that annotating a genome means first locating the genes on the DNA sequences that is the genes, the region coding for proteins. But this is indeed the first step,the next very
-
4.10. How efficient is this algorithm?
RechenmannFrançoisWe have seen the principle of an iterative algorithm in two paths for aligning and comparing two sequences of characters, here DNA sequences. And we understoodwhy the iterative version is much more
-
5.7. The application domains in microbiology
RechenmannFrançoisBioinformatics relies on many domains of mathematics and computer science. Of course, algorithms themselves on character strings are important in bioinformatics, we have seen them. Algorithms and
-
1.2. At the heart of the cell: the DNA macromolecule
RechenmannFrançoisDuring the last session, we saw how at the heart of the cell there's DNA in the nucleus, sometimes of cells, or directly in the cytoplasm of the bacteria. The DNA is what we call a macromolecule, that
-
1.10. Overlapping sliding window
RechenmannFrançoisWe have made some drawings along a genomic sequence. And we have seen that although the algorithm is quite simple, even if some points of the algorithmare bit trickier than the others, we were able to
-
2.3. The genetic code
RechenmannFrançoisGenes code for proteins. What is the correspondence betweenthe genes, DNA sequences, and the structure of proteins? The correspondence isthe genetic code. Proteins have indeedsequences of amino acids.
-
3.6. Boyer-Moore algorithm
RechenmannFrançoisWe have seen how we can make gene predictions more reliable through searching for all the patterns,all the occurrences of patterns. We have seen, for example, howif we locate the RBS, Ribosome
-
4.5. A sequence alignment as a path
RechenmannFrançoisComparing two sequences and thenmeasuring their similarities is an optimization problem. Why? Because we have seen thatwe have to take into account substitution and deletion. During the alignment, the
-
5.5. Differences are not always what they look like
RechenmannFrançoisThe algorithm we have presented works on an array of distance between sequences. These distances are evaluated on the basis of differences between the sequences. The problem is that behind the










Sur le même thème
-
La voix, une donnée identifiante à protéger
VincentEmmanuelEmmanuel Vincent, chercheur au Centre Inria de l'Université de Lorraine et au Loria (Laboratoire lorrain de recherche en informatique et ses applications), présente sa recherche sur l'anonymisation de
-
Podcast 1/4 d'heure avec : Emmanuel Vincent, chercheur au Centre Inria de l'Université de Lorraine …
VincentEmmanuelRencontre avec Emmanuel Vincent - chercheur au Centre Inria de l'Université de Lorraine et Loria (Laboratoire lorrain de recherche en informatique et ses applications).
-
Stockage de données numériques sur ADN synthétique : Introduction au domaine
AntoniniMarcDuprazElsaLavenierDominiquePrésentation globale des différentes étapes du stockage de données sur des molécules d'ADN synthétique
-
Stockage de données numériques sur ADN synthétique : Production des données: synthèse, séquençage
LavenierDominiqueBarbryPascalDescription des opérations d'écriture et de lecture des molécules d'ADN : synthèse et séquençage.
-
Stockage de données numériques sur ADN synthétique : Reconstruction des données
LavenierDominiqueTraitement des données après séquençage
-
Stockage de données numériques sur ADN synthétique : Codage Canal
DuprazElsaTechniques de codage pour le stockage de données sur ADN
-
Stockage de données numériques sur ADN synthétique : Codage Source
AntoniniMarcCodage source pour le stockage de données sur ADN synthétique
-
Stockage de données numériques sur ADN synthétique : Théorie de l'information
Kas HannaSergeQuelle quantité d'information peut-on stocker et récupérer de manière fiable dans l'ADN ?
-
The tree of life
AbbySophieLes Rencontres Exobiologiques pour Doctorants (RED) sont une école de formation sur les « bases de l'astrobiologie ». L’édition 2025 s’est tenue du 16 au 21 mars au Parc Ornithologique du Teich.
-
Machines algorithmiques, mythes et réalités
MazenodVincentVincent Mazenod, informaticien, partage le fruit de ses réflexions sur l'évolution des outils numériques, en lien avec les problématiques de souveraineté, de sécurité et de vie privée...
-
Désassemblons le numérique - #Episode11 : Les algorithmes façonnent-ils notre société ?
SchwartzArnaudLima PillaLaércioEstériePierreSalletFrédéricFerbosAudeRoumanosRayyaChraibi KadoudIkramUn an après le tout premier hackathon sur les méthodologies d'enquêtes journalistiques sur les algorithmes, ce nouvel épisode part à la rencontre de différents points de vue sur les algorithmes.
-
Les machines à enseigner. Du livre à l'IA...
BruillardÉricQue peut-on, que doit-on déléguer à des machines ? C'est l'une des questions explorées par Éric Bruillard qui, du livre aux IA génératives, expose l'évolution des machines à enseigner...











