Notice
3.3. À la recherche des codons start et stop
- document 1 document 2 document 3
- niveau 1 niveau 2 niveau 3
Descriptif
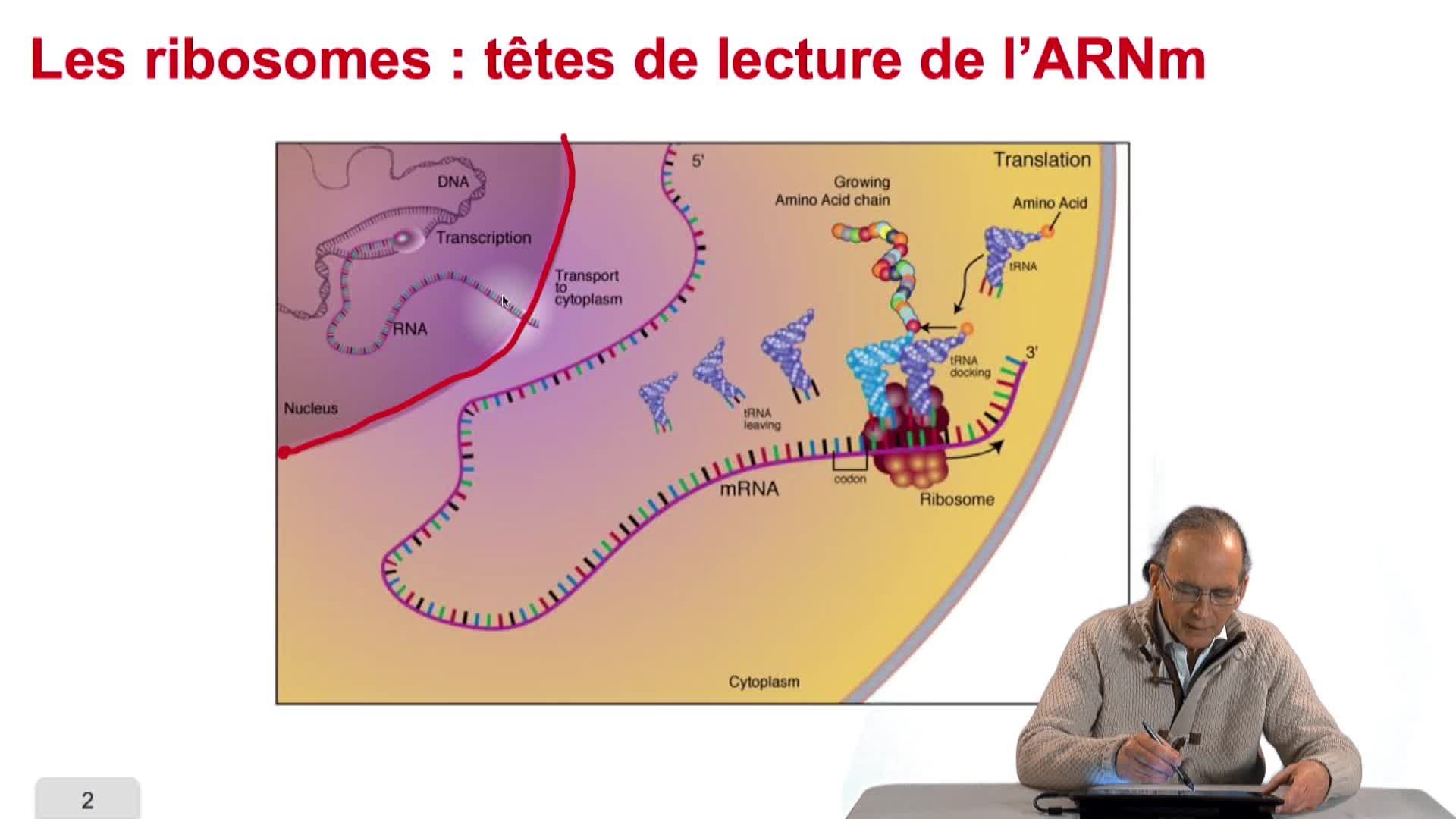
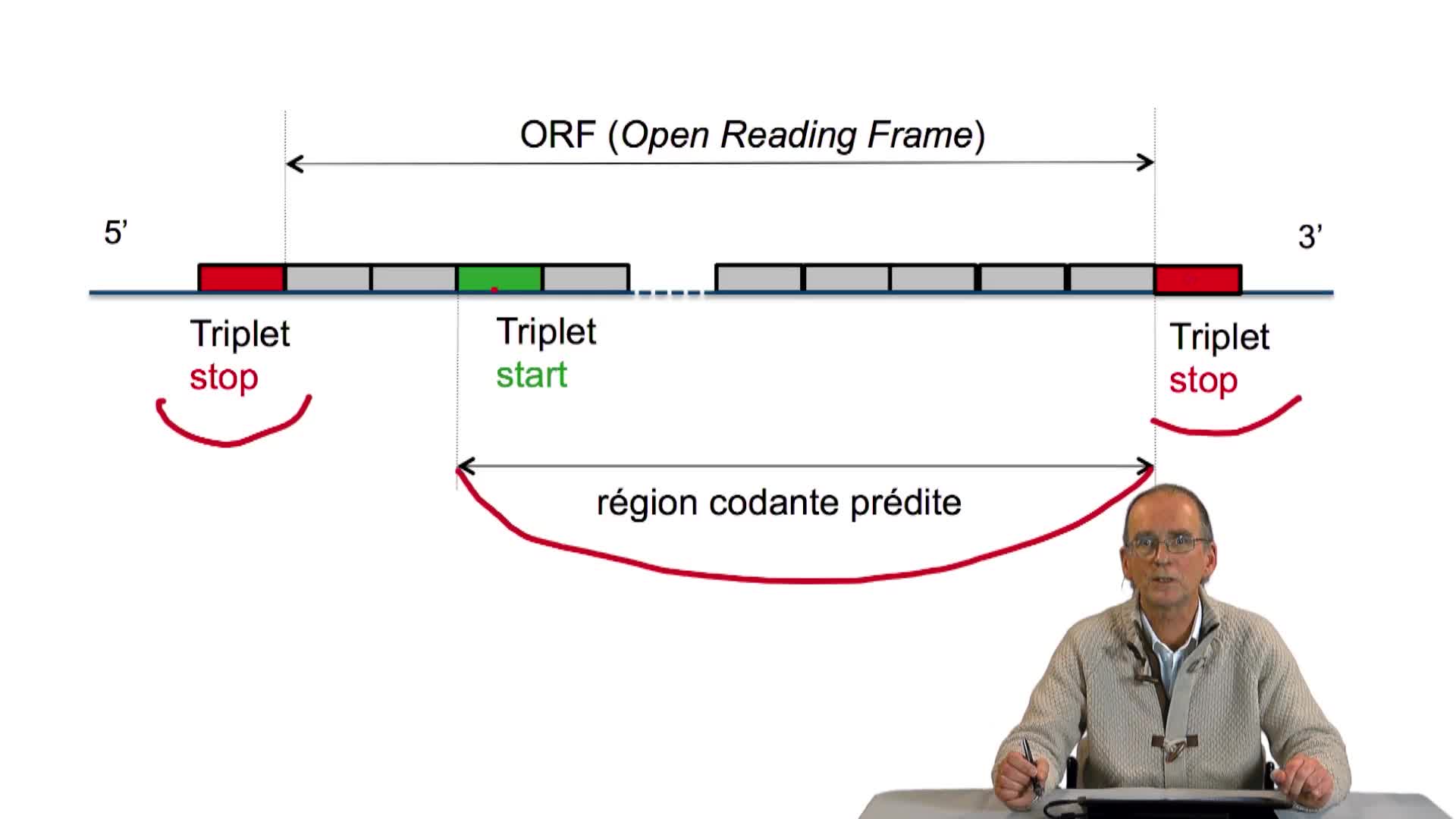
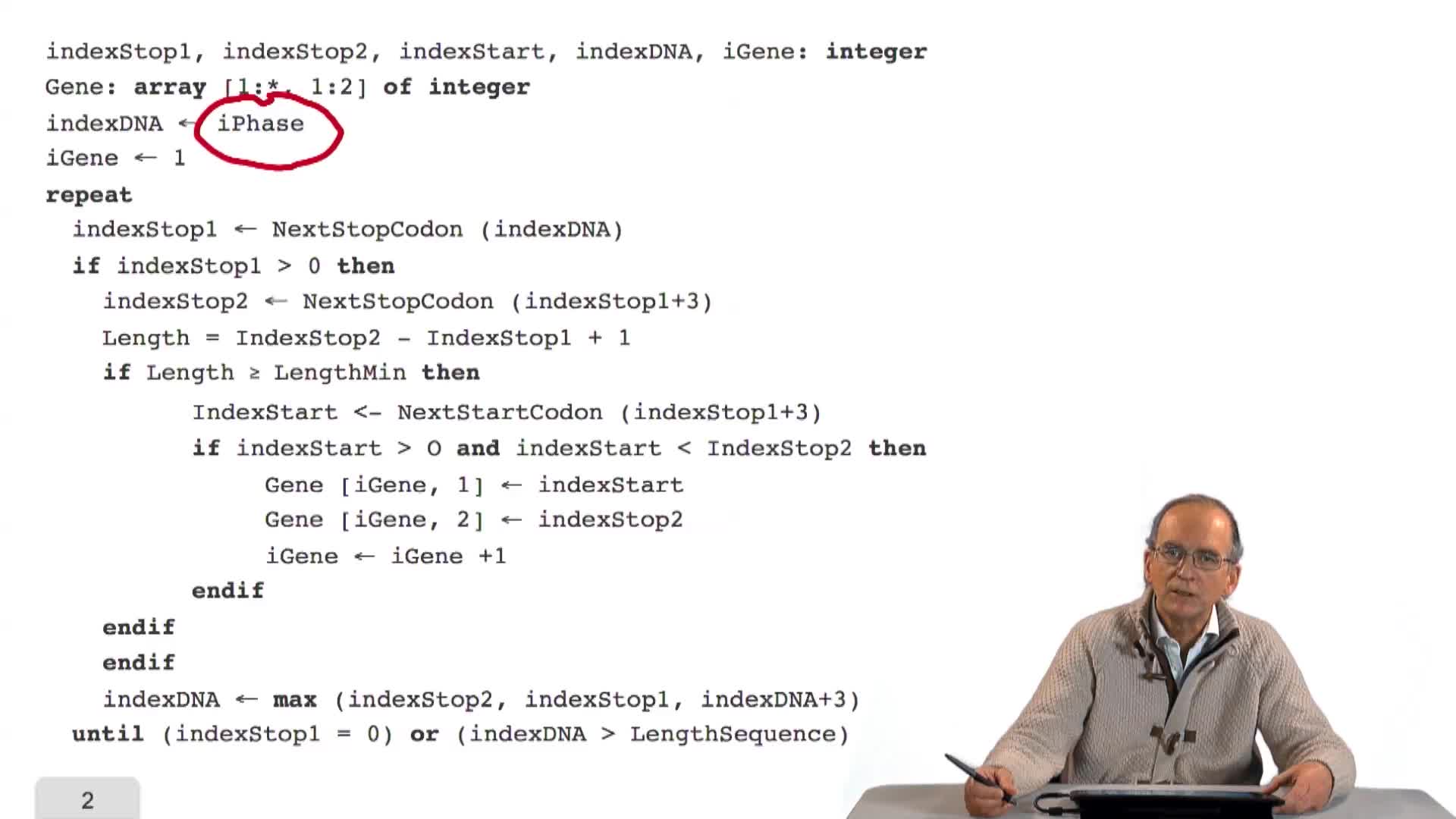
Nous avons écrit la structure, l'ossature d'un algorithme de prédiction de gènes dans un génome bactérien, en utilisant les principes que nous avions énoncés précédemment. Cet algorithme est incomplet puisque pour l'instant, nous avons repoussé l'écriture des 2 fonctions nécessaires à la recherche des occurrences des triplets Stop et Start. C'est donc ce que nous allons faire maintenant.
Comment faire pour rechercher l'occurrence d'un triplet ? En fait l'algorithme est très simple, très naïf, il consiste à comparer chaque lettre du triplet à chaque lettre de la séquence, et faire progresser, si aucune correspondance n'est trouvée, faire correspondre le motif le long de la séquence jusqu'à avoir trouvé une occurrence. Regardons ce qui se passe.
Ici, c'est simple, on compare le T avec le A, il n'y a pas de correspondance donc on avance directement au triplet suivant, ce n'est pas la peine de regarder les autres lettres...
ERRATUM
Une erreur s'est glissée dans le code du transparent 8, cf. correction détaillée dans l'onglet Erratum.
Intervention / Responsable scientifique


Thème
Documentation
Erratum
Une erreur s'est glissée dans le code du transparent 8, cf. correction indiquée en rouge ci-dessous :

Dans la même collection
-
3.7. Index et arbre des suffixes
RechenmannFrançoisParmentelatThierryIl y a donc deux approches pour améliorer la performance des algorithmes de recherche d'un motif dans une chaîne de caractères. La première approche consiste à pré-traiter le motif. On a vu un exemple
-
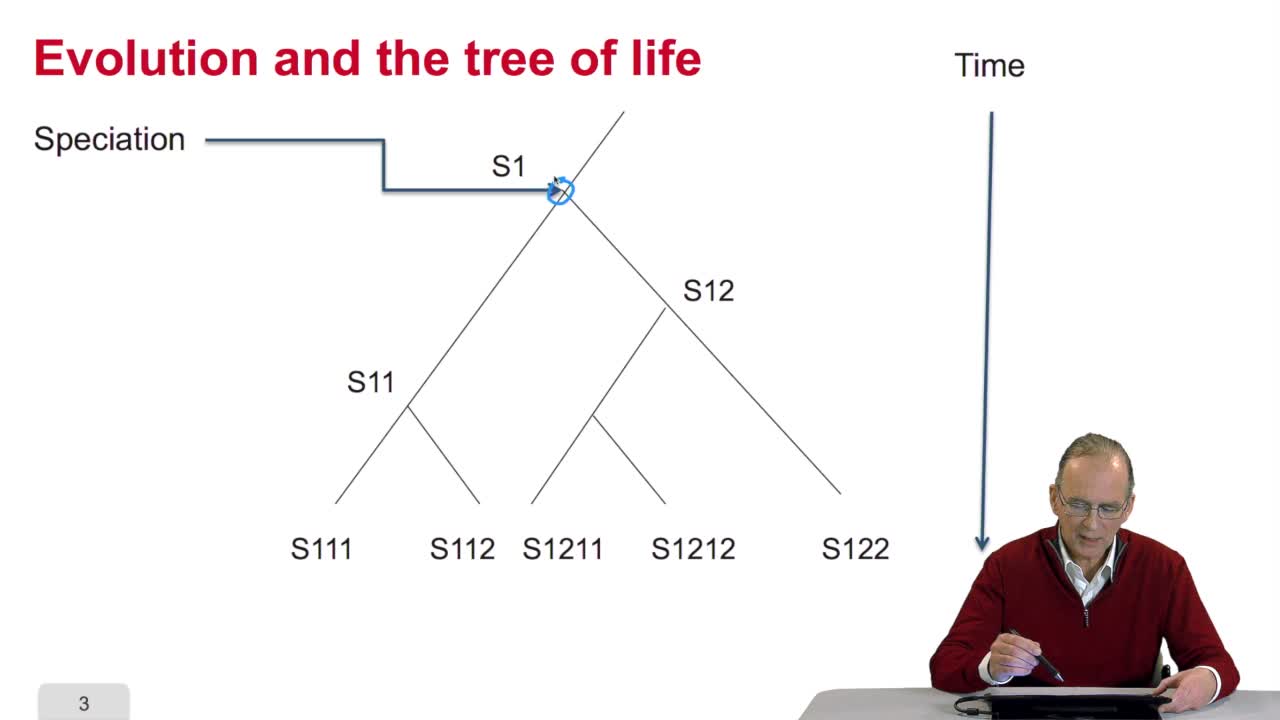
3.1. Tous les gènes se terminent sur un codon stop
RechenmannFrançoisParmentelatThierryUne fois la séquence d'un génome complet obtenue, débute la phase d'annotation. L'annotation elle-même consiste tout d'abord à rechercher la localisation, c'est-à-dire la position des gènes sur cette
-
3.10. La prédiction de gènes dans les génomes eucaryotes
RechenmannFrançoisParmentelatThierrySi nous disposons actuellement de prédicteurs de gènes dans les génomes procaryotes de très bonne efficacité, avec des prédictions relativement fiables, c'est en fait loin d'être le cas sur les
-
3.5. Comment améliorer la qualité des prédictions ?
RechenmannFrançoisParmentelatThierryIl faut toujours le répéter et le souligner, les algorithmes qui déterminent des gènes déterminent des gènes candidats. Ce sont des prédictions de gènes. Donc la question est de savoir s'il est
-
3.8. Des méthodes probabilistes à la rescousse
RechenmannFrançoisParmentelatThierryNous avons vu comment la qualité des prédictions de gènes dans un génome bactérien, pouvait être améliorée à travers la recherche d'occurrences de motifs particuliers liés au site de fixation du
-
3.2. Un algorithme simple de prédiction de gènes
RechenmannFrançoisParmentelatThierrySur la base des principes énoncés précédemment, nous allons écrire un premier algorithme de prédiction de gènes sur un texte génomique procaryote. Je rappelle ces principes. L'idée est la suivante :
-
3.6. L’algorithme de Boyer-Moore
RechenmannFrançoisParmentelatThierryVous avez compris que la recherche de motifs, c'est-à-dire de sous-chaînes de caractères dans une chaîne plus importante, était un composant important de beaucoup d'algorithmes de bio-informatique.
-
3.9. Comment évaluer la qualité de prédiction des méthodes ?
RechenmannFrançoisParmentelatThierryNous avons vu qu'il était possible, ou du moins nous le pensions, améliorer la qualité de prédiction des gènes sur un génome bactérien en introduisant des démarches supplémentaires, de recherches de
-
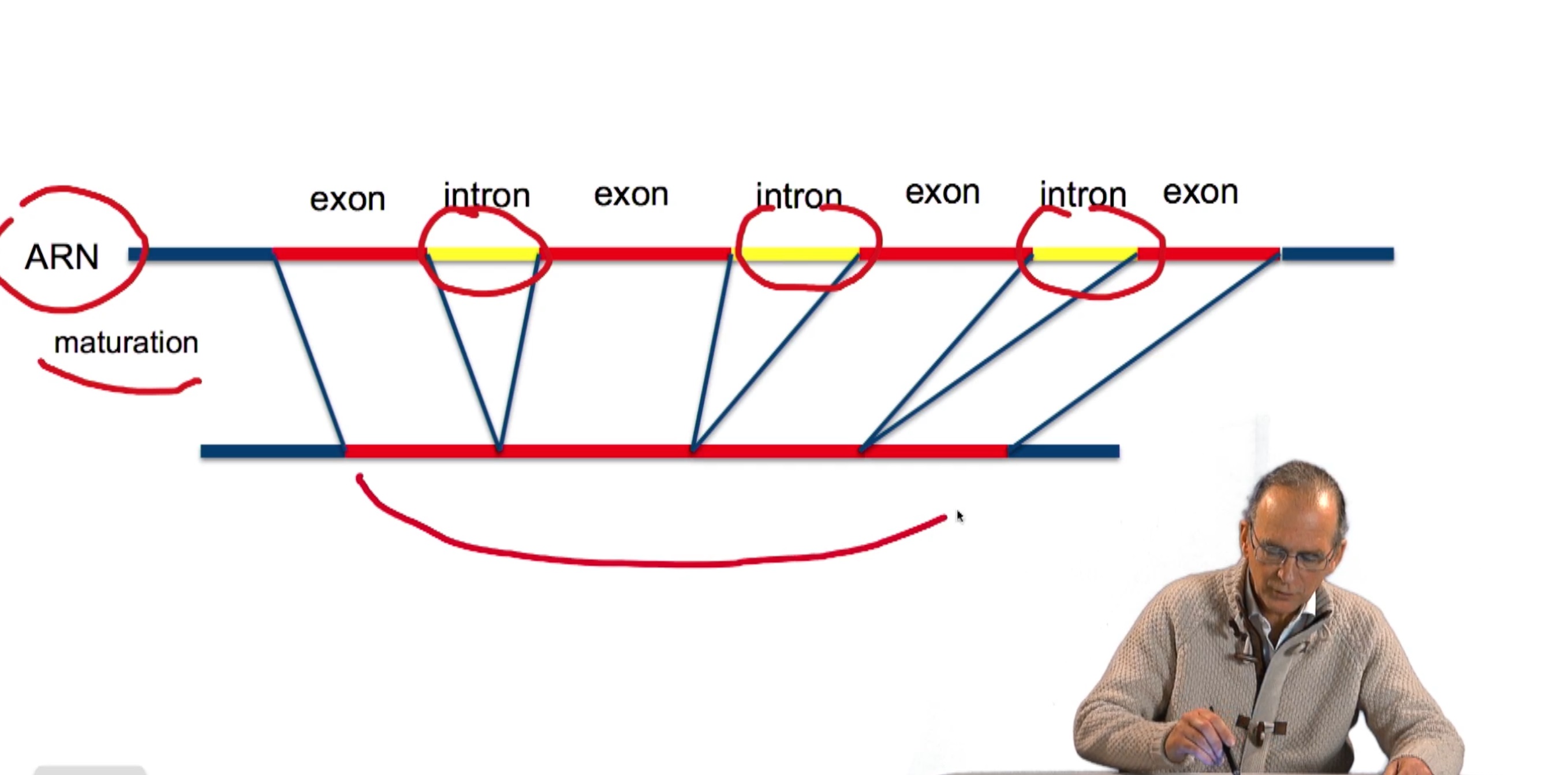
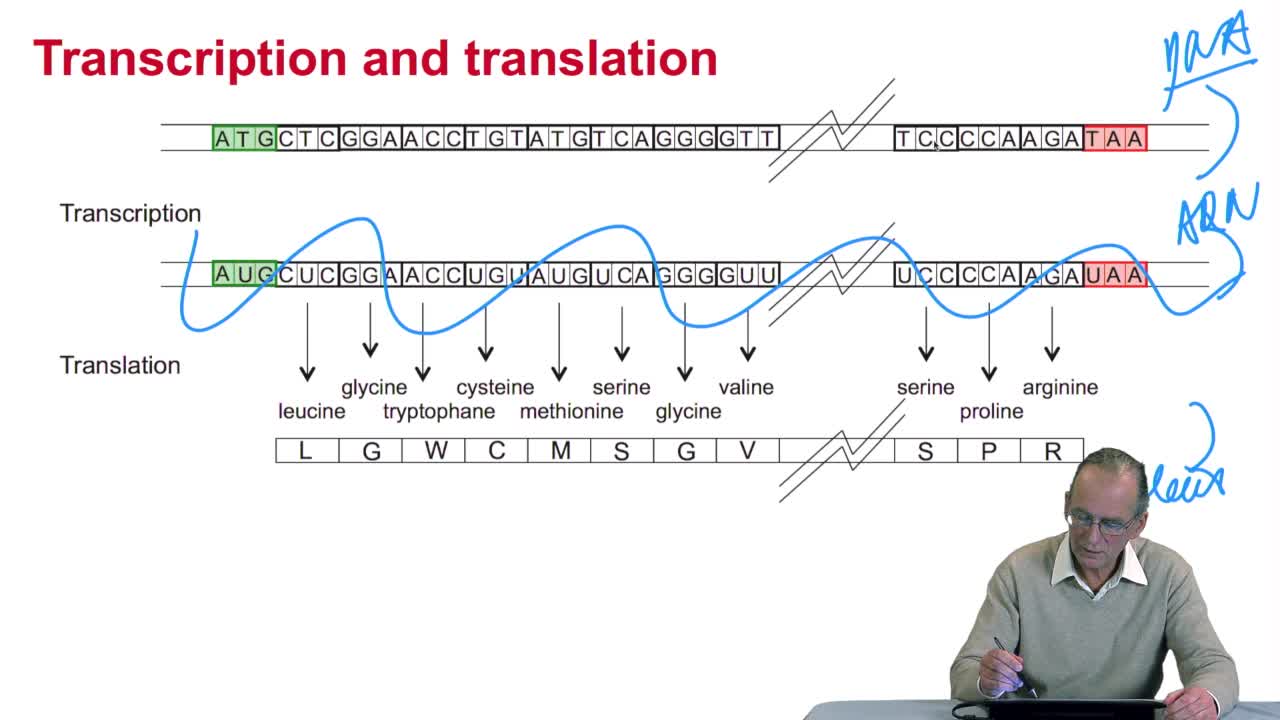
3.4. Prédiction de tous les gènes d’une séquence
RechenmannFrançoisParmentelatThierryEn combinant de façon adéquate la recherche des triplés Stop et Start sur un brin d'ADN, nous avons obtenu un algorithme qui prédit les gènes sur ce brin, mais également sur une phase. C'est-à-dire en





Avec les mêmes intervenants et intervenantes
-
1.5. Counting nucleotides
RechenmannFrançoisIn this session, don't panic. We will design our first algorithm. This algorithm is forcounting nucleotides. The idea here is that as an input,you have a sequence of nucleotides, of bases, of letters,
-
2.4. A translation algorithm
RechenmannFrançoisWe have seen that the genetic codeis a correspondence between the DNA or RNA sequences and aminoacid sequences that is proteins. Our aim here is to design atranslation algorithm, we make the
-
3.1. All genes end on a stop codon
RechenmannFrançoisLast week we studied genes and proteins and so how genes, portions of DNA, are translated into proteins. We also saw the very fast evolutionof the sequencing technology which allows for producing
-
3.9. Benchmarking the prediction methods
RechenmannFrançoisIt is necessary to underline that gene predictors produce predictions. Predictions mean that you have no guarantees that the coding sequences, the coding regions,the genes you get when applying your
-
4.2. Why gene/protein sequences may be similar?
RechenmannFrançoisBefore measuring the similaritybetween the sequences, it's interesting to answer the question: why gene or protein sequences may be similar? It is indeed veryinteresting because the answer is related
-
5.4. The UPGMA algorithm
RechenmannFrançoisWe know how to fill an array with the values of the distances between sequences, pairs of sequences which are available in the file. This array of distances will be the input of our algorithm for
-
1.8. Compressing the DNA walk
RechenmannFrançoisWe have written the algorithm for the circle DNA walk. Just a precision here: the kind of drawing we get has nothing to do with the physical drawing of the DNA molecule. It is a symbolic
-
2.7. The algorithm design trade-off
RechenmannFrançoisWe saw how to increase the efficiencyof our algorithm through the introduction of a data structure. Now let's see if we can do even better. We had a table of index and weexplain how the use of these
-
3.4. Predicting all the genes in a sequence
RechenmannFrançoisWe have written an algorithm whichis able to locate potential genes on a sequence but only on one phase because we are looking triplets after triplets. Now remember that the genes maybe located on
-
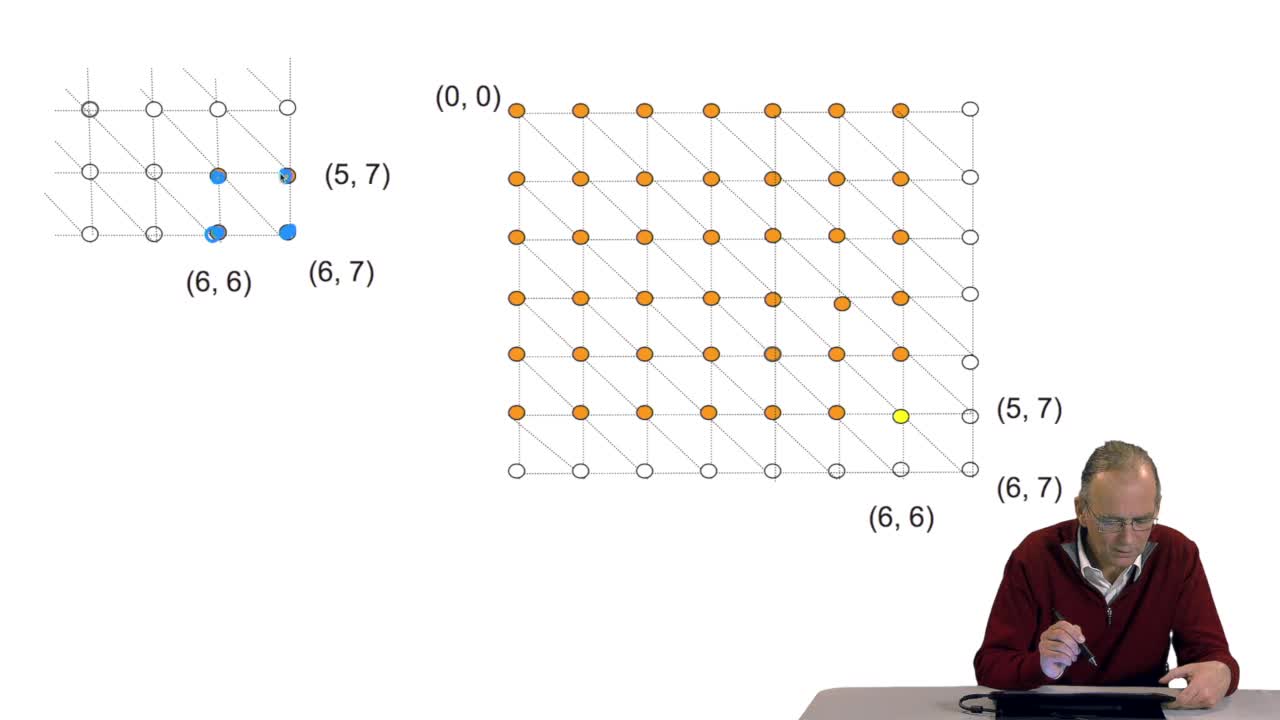
4.7. Alignment costs
RechenmannFrançoisWe have seen how we can compute the cost of the path ending on the last node of our grid if we know the cost of the sub-path ending on the three adjacent nodes. It is time now to see more deeply why
-
4.9. Recursion can be avoided: an iterative version
RechenmannFrançoisWe have written a recursive function to compute the optimal path that is an optimal alignment between two sequences. Here all the examples I gave were onDNA sequences, four letter alphabet. OK. The
-
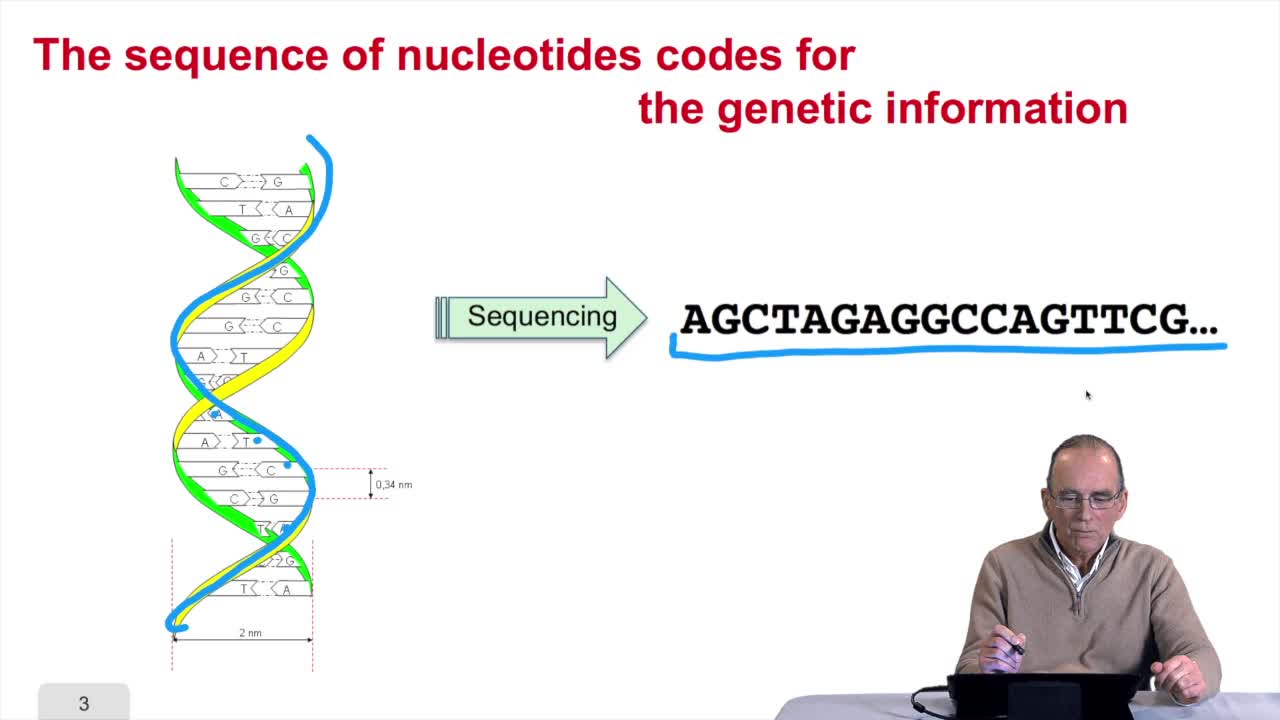
1.3. DNA codes for genetic information
RechenmannFrançoisRemember at the heart of any cell,there is this very long molecule which is called a macromolecule for this reason, which is the DNA molecule. Now we will see that DNA molecules support what is called




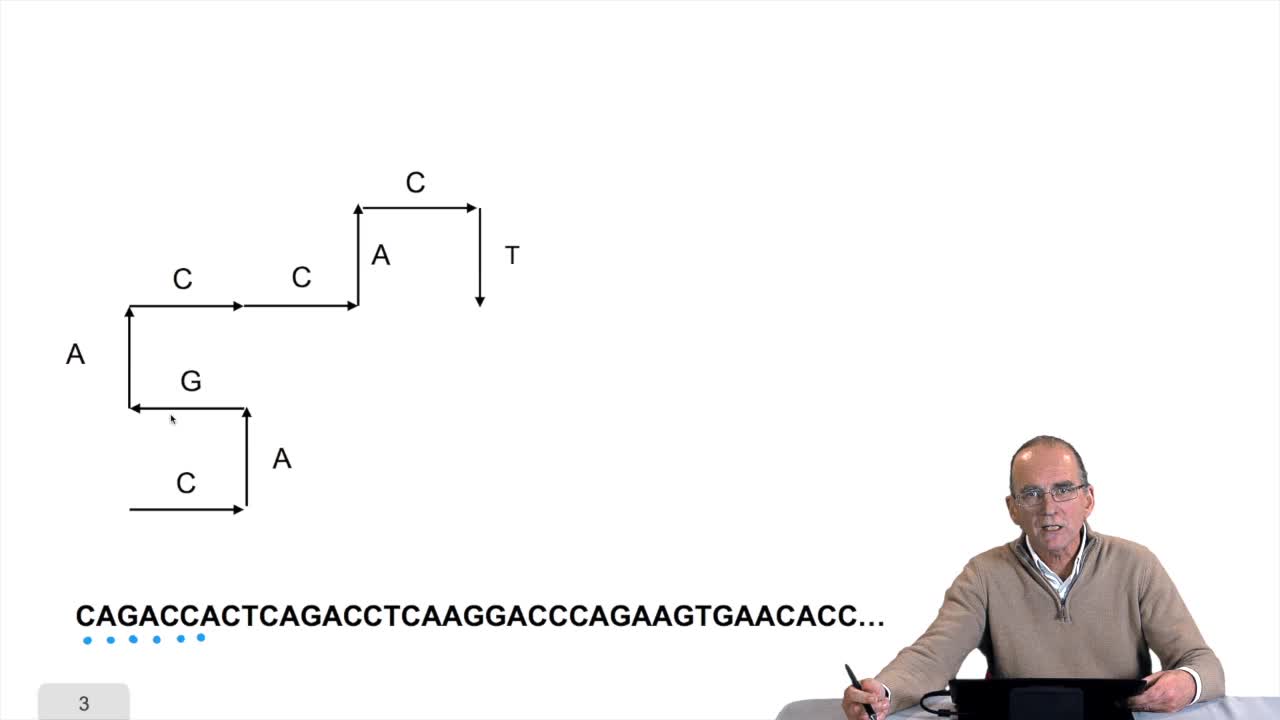



Sur le même thème
-
The tree of life
AbbySophieLes Rencontres Exobiologiques pour Doctorants (RED) sont une école de formation sur les « bases de l'astrobiologie ». L’édition 2025 s’est tenue du 16 au 21 mars au Parc Ornithologique du Teich.
-
Machines algorithmiques, mythes et réalités
MazenodVincentVincent Mazenod, informaticien, partage le fruit de ses réflexions sur l'évolution des outils numériques, en lien avec les problématiques de souveraineté, de sécurité et de vie privée...
-
Désassemblons le numérique - #Episode11 : Les algorithmes façonnent-ils notre société ?
SchwartzArnaudLima PillaLaércioEstériePierreSalletFrédéricFerbosAudeRoumanosRayyaChraibi KadoudIkramUn an après le tout premier hackathon sur les méthodologies d'enquêtes journalistiques sur les algorithmes, ce nouvel épisode part à la rencontre de différents points de vue sur les algorithmes.
-
Les machines à enseigner. Du livre à l'IA...
BruillardÉricQue peut-on, que doit-on déléguer à des machines ? C'est l'une des questions explorées par Éric Bruillard qui, du livre aux IA génératives, expose l'évolution des machines à enseigner...
-
Désassemblons le numérique - #Episode9 : Bientôt des supercalculateurs dans nos piscines ?
BeaumontOlivierBouzelRémiDes supercalculateurs feraient-ils bientôt leur apparition dans les piscines municipales pour les chauffer ? Réponses d'Olivier Beaumont, responsable de l'équipe-projet Topal, et Rémi Bouzel,
-
Le projet dnarXiv : Stockage de données sur des molécules d'ADN
LavenierDominiqueDuprazElsaLeblancJulienCoatrieuxGouenouDominique Lavenier, Elsa Dupraz, Julien Leblanc et Gouenou Coatrieux nous présentent le projet dnarXiv, un projet porté par le LabEx CominLabs qui explore le stockage de données sur des molécules d
-
Projection methods for community detection in complex networks
LitvakNellyCommunity detection is one of most prominent tasks in the analysis of complex networks such as social networks, biological networks, and the world wide web. A community is loosely defined as a group
-
Lara Croft. doing fieldwork under surveillance
Dall'AgnolaJasminLara Croft. Doing Fieldwork Under Surveillance Intervention de Jasmin Dall'Agnola (The George Washington University), dans le cadre du Colloque coorganisé par Anders Albrechtslund, professeur en
-
Containing predictive tokens in the EU
CzarnockiJanContaining Predictive Tokens in the EU – Mapping the Laws Against Digital Surveillance, intervention de Jan Czarnocki (KU Leuven), dans le cadre du Colloque coorganisé par Anders Albrechtslund,
-
Ivan Murit - Processus de création d'images
MuritIvanJe vais présenter une manière décalée d'aborder les outils d'impression. Pour cela nous ne partirons pas de l'envie d'imprimer une image préexistante, mais d'avant cela : comment se crée une forme
-
Le Creativ’Lab, au cœur de la robotique et de l’intelligence artificielle (ASR N°18 - LORIA)
HénaffPatrickLefebvreSylvainLe LORIA, laboratoire phare de la Grande Région dans le domaine de l’informatique, propose de rendre la recherche plus ouverte, plus collaborative, plus ambitieuse… en un mot, plus créative, à travers
-
Les algorithmes de Parcoursup
MathieuClaireL’objectif de la journée « Algorithmes d’aide à la décision publique » était de sensibiliser le grand public aux rôles des algorithmes d’aide à la décision publique utilisés par exemple pour l











