Notice
3.7. Index et arbre des suffixes
- document 1 document 2 document 3
- niveau 1 niveau 2 niveau 3
Descriptif
Il y a donc deux approches pour améliorer la performance des algorithmes de recherche d'un motif dans une chaîne de caractères. La première approche consiste à pré-traiter le motif. On a vu un exemple de cette approche avec l'algorithme de Boyer-Moore. La deuxième approche consiste à pré-traiter le texte dans lequel nous recherchons les motifs. Et nous allons voir deux exemples de mise en oeuvre de cette approche. La première consiste à construire un index de mots de longueur fixe. De quoi s'agit-il ? Considérons cette chaîne de caractères, relativement courte ici, de longueur 14. Nous allons construire un index de tous les triplets qui apparaissent dans cette séquence. Voilà ce que ça donne. Vérifions. Ce triplet AA # ou # n'appartient pas à la séquence mais marque la fin de la séquence. On trouve bien une occurrence de ce triplet à la position 13. De même pour le triplet ACG, on trouve bien une occurrence, voire même l'occurrence, la seule de ACG à la position une, et ainsi de suite...
Intervention


Dans la même collection
-
3.6. L’algorithme de Boyer-Moore
RechenmannFrançoisParmentelatThierryVous avez compris que la recherche de motifs, c'est-à-dire de sous-chaînes de caractères dans une chaîne plus importante, était un composant important de beaucoup d'algorithmes de bio-informatique.
-
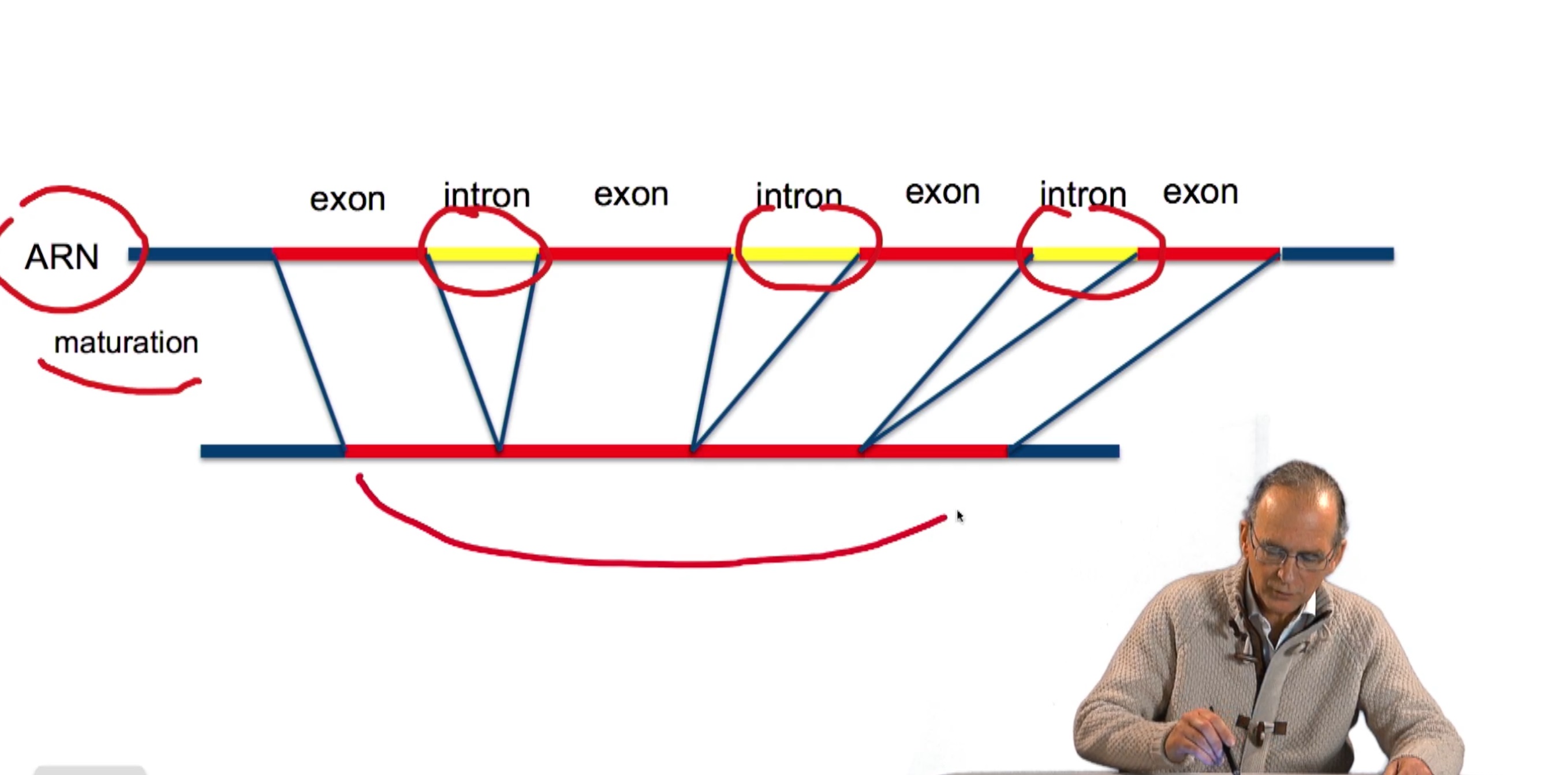
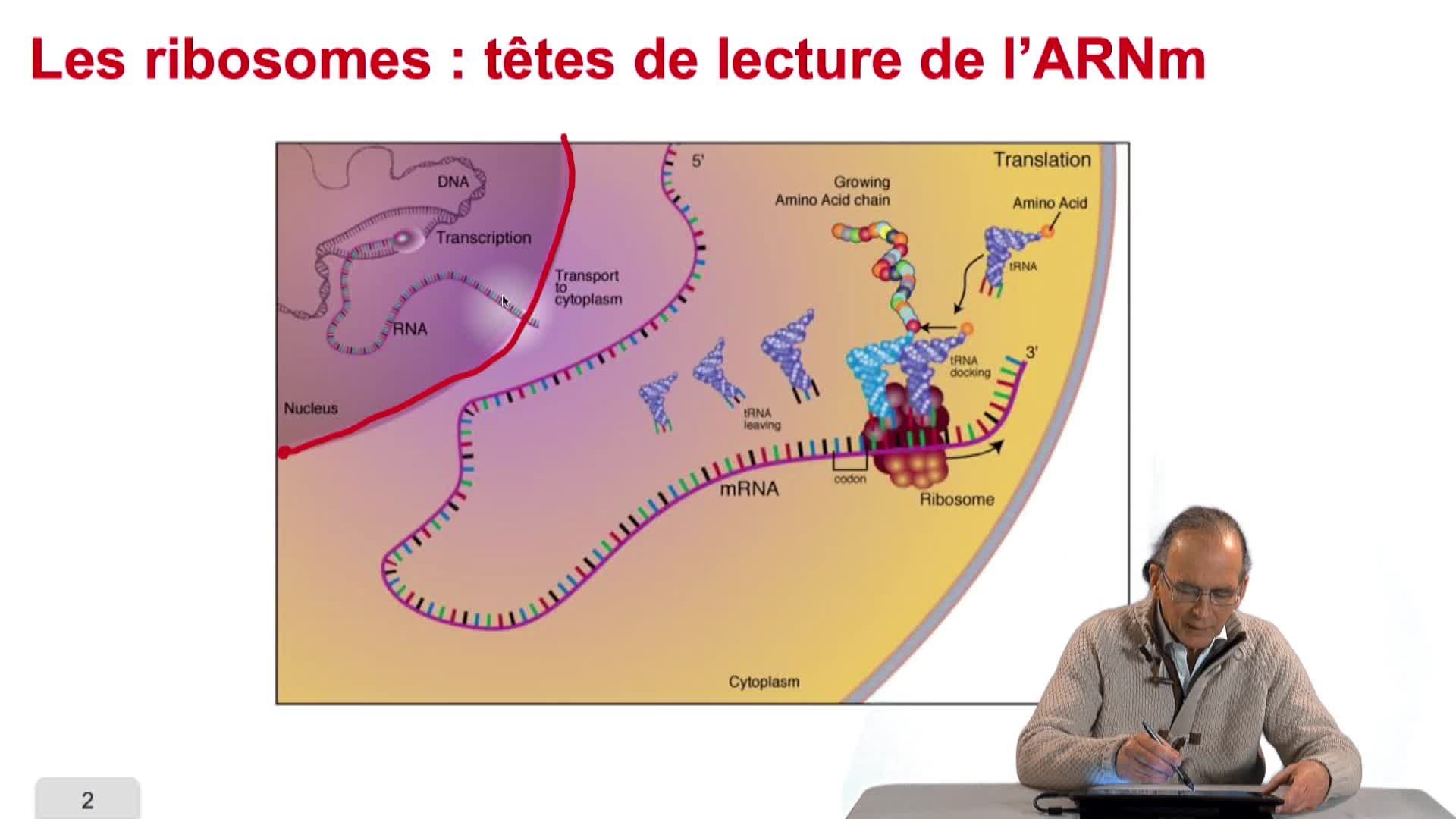
3.1. Tous les gènes se terminent sur un codon stop
RechenmannFrançoisParmentelatThierryUne fois la séquence d'un génome complet obtenue, débute la phase d'annotation. L'annotation elle-même consiste tout d'abord à rechercher la localisation, c'est-à-dire la position des gènes sur cette
-
3.10. La prédiction de gènes dans les génomes eucaryotes
RechenmannFrançoisParmentelatThierrySi nous disposons actuellement de prédicteurs de gènes dans les génomes procaryotes de très bonne efficacité, avec des prédictions relativement fiables, c'est en fait loin d'être le cas sur les
-
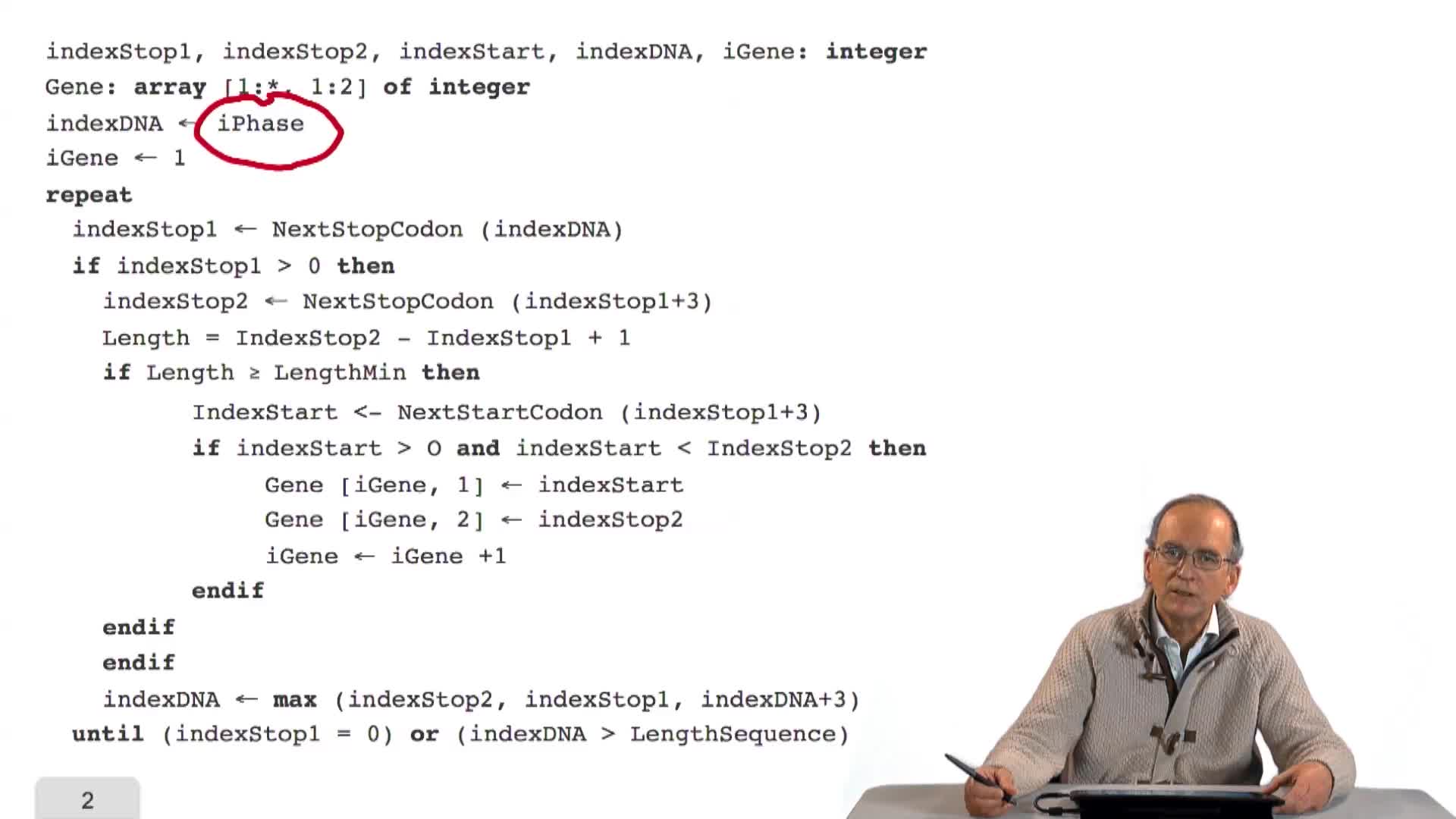
3.4. Prédiction de tous les gènes d’une séquence
RechenmannFrançoisParmentelatThierryEn combinant de façon adéquate la recherche des triplés Stop et Start sur un brin d'ADN, nous avons obtenu un algorithme qui prédit les gènes sur ce brin, mais également sur une phase. C'est-à-dire en
-
3.8. Des méthodes probabilistes à la rescousse
RechenmannFrançoisParmentelatThierryNous avons vu comment la qualité des prédictions de gènes dans un génome bactérien, pouvait être améliorée à travers la recherche d'occurrences de motifs particuliers liés au site de fixation du
-
3.2. Un algorithme simple de prédiction de gènes
RechenmannFrançoisParmentelatThierrySur la base des principes énoncés précédemment, nous allons écrire un premier algorithme de prédiction de gènes sur un texte génomique procaryote. Je rappelle ces principes. L'idée est la suivante :
-
3.5. Comment améliorer la qualité des prédictions ?
RechenmannFrançoisParmentelatThierryIl faut toujours le répéter et le souligner, les algorithmes qui déterminent des gènes déterminent des gènes candidats. Ce sont des prédictions de gènes. Donc la question est de savoir s'il est
-
3.9. Comment évaluer la qualité de prédiction des méthodes ?
RechenmannFrançoisParmentelatThierryNous avons vu qu'il était possible, ou du moins nous le pensions, améliorer la qualité de prédiction des gènes sur un génome bactérien en introduisant des démarches supplémentaires, de recherches de
-
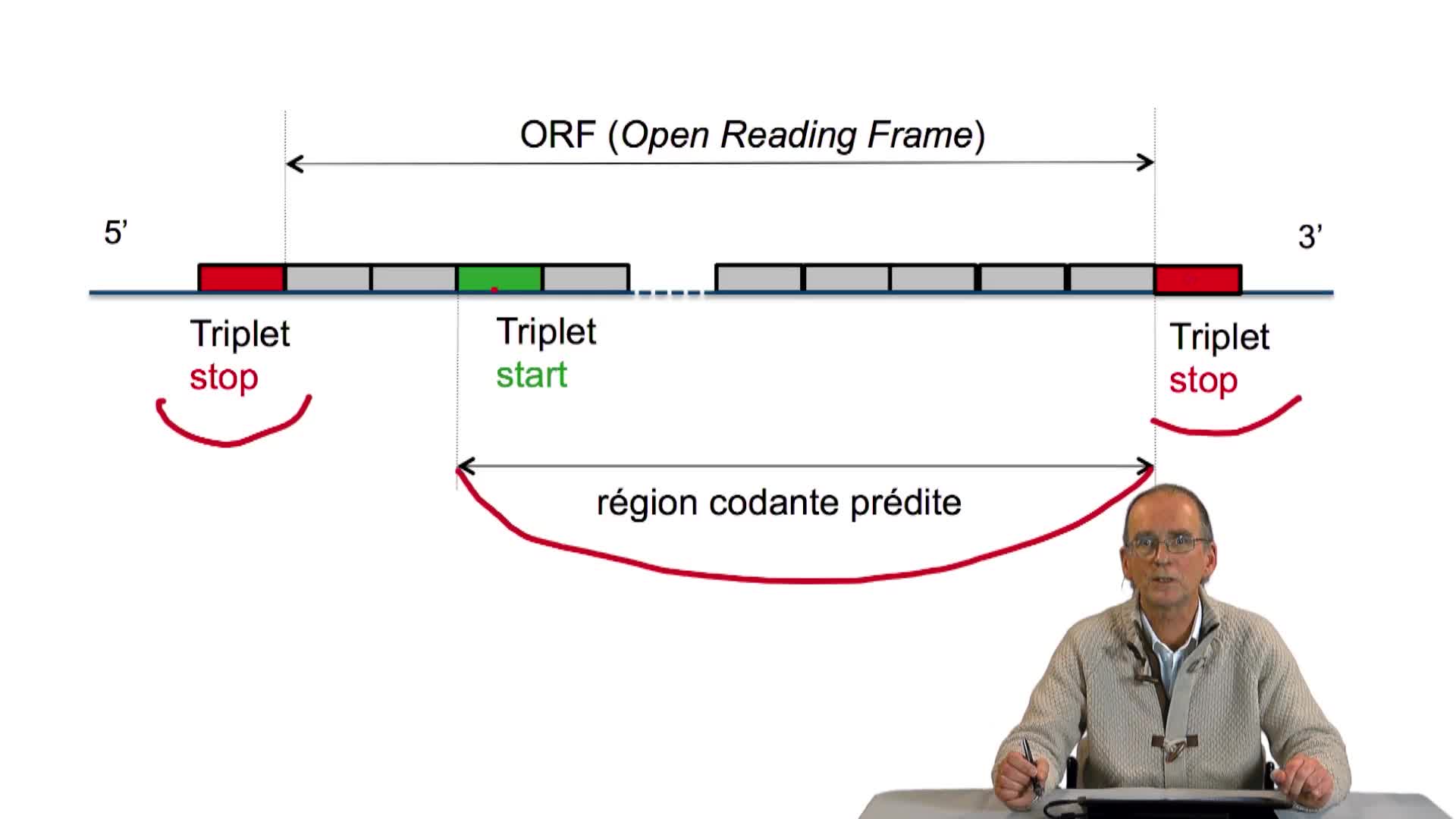
3.3. À la recherche des codons start et stop
RechenmannFrançoisParmentelatThierryNous avons écrit la structure, l'ossature d'un algorithme de prédiction de gènes dans un génome bactérien, en utilisant les principes que nous avions énoncés précédemment. Cet algorithme est incomplet





Avec les mêmes intervenants et intervenantes
-
1.8. Compressing the DNA walk
RechenmannFrançoisWe have written the algorithm for the circle DNA walk. Just a precision here: the kind of drawing we get has nothing to do with the physical drawing of the DNA molecule. It is a symbolic
-
2.7. The algorithm design trade-off
RechenmannFrançoisWe saw how to increase the efficiencyof our algorithm through the introduction of a data structure. Now let's see if we can do even better. We had a table of index and weexplain how the use of these
-
3.4. Predicting all the genes in a sequence
RechenmannFrançoisWe have written an algorithm whichis able to locate potential genes on a sequence but only on one phase because we are looking triplets after triplets. Now remember that the genes maybe located on
-
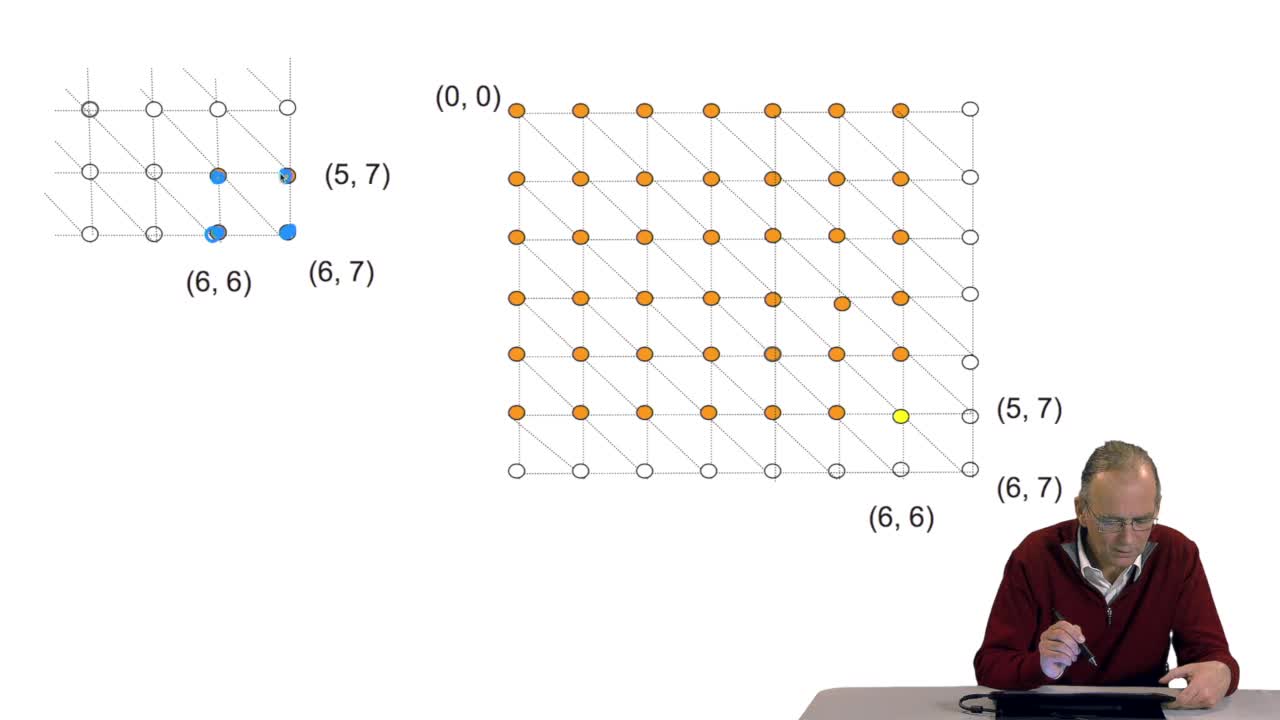
4.7. Alignment costs
RechenmannFrançoisWe have seen how we can compute the cost of the path ending on the last node of our grid if we know the cost of the sub-path ending on the three adjacent nodes. It is time now to see more deeply why
-
4.9. Recursion can be avoided: an iterative version
RechenmannFrançoisWe have written a recursive function to compute the optimal path that is an optimal alignment between two sequences. Here all the examples I gave were onDNA sequences, four letter alphabet. OK. The
-
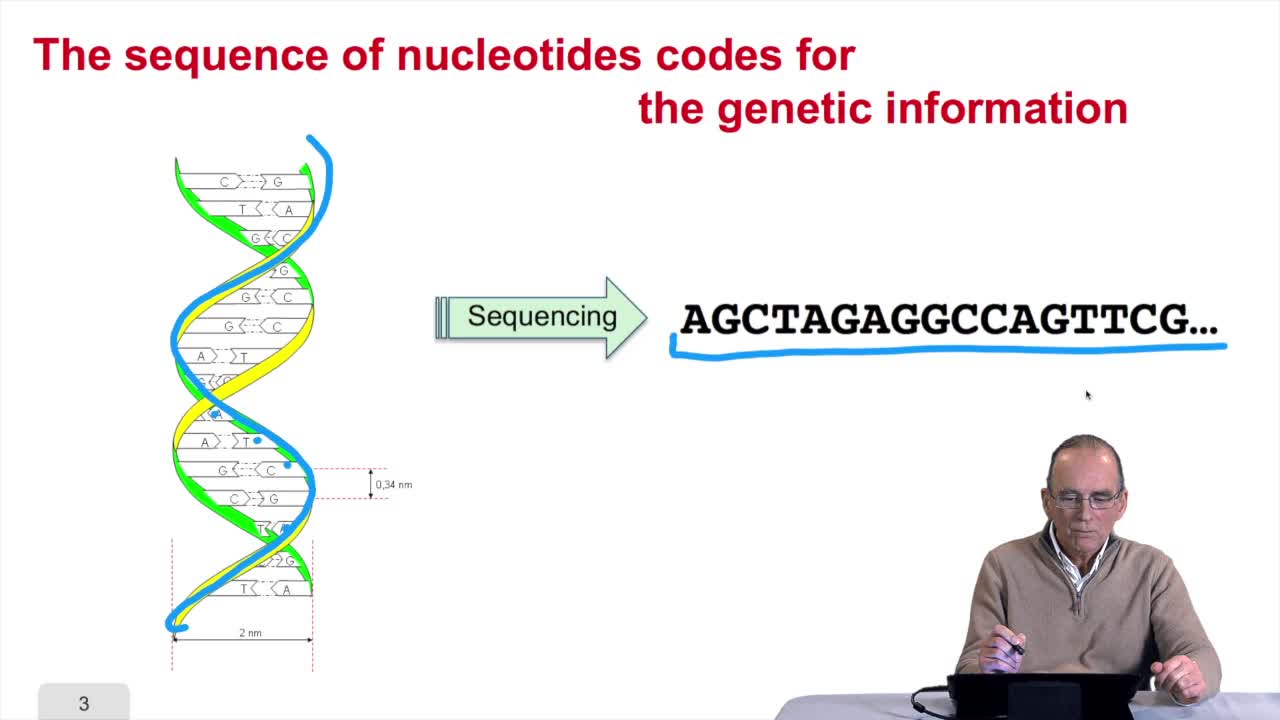
1.3. DNA codes for genetic information
RechenmannFrançoisRemember at the heart of any cell,there is this very long molecule which is called a macromolecule for this reason, which is the DNA molecule. Now we will see that DNA molecules support what is called
-
2.1. The sequence as a model of DNA
RechenmannFrançoisWelcome back to our course on genomes and algorithms that is a computer analysis ofgenetic information. Last week we introduced the very basic concept in biology that is cell, DNA, genome, genes
-
2.9. Whole genome sequencing
RechenmannFrançoisSequencing is anexponential technology. The progresses in this technologyallow now to a sequence whole genome, complete genome. What does it mean? Well let'stake two examples: some twenty years ago,
-
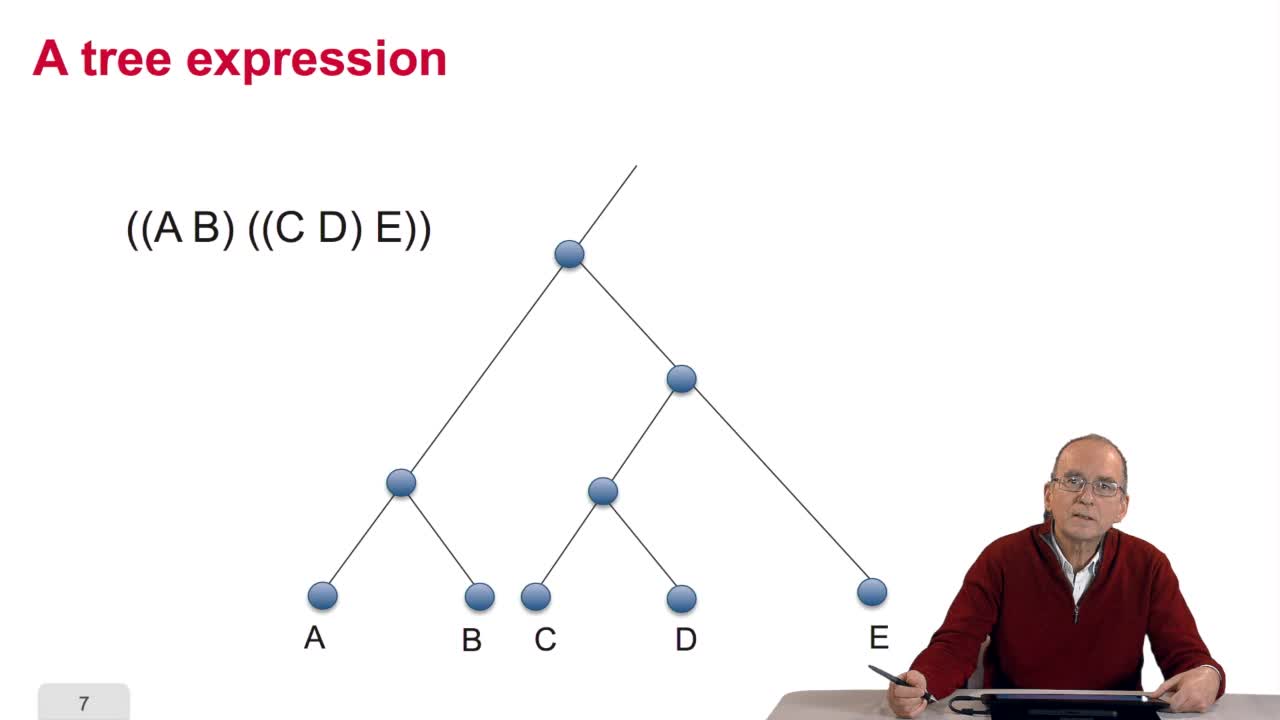
3.7. Index and suffix trees
RechenmannFrançoisWe have seen with the Boyer-Moore algorithm how we can increase the efficiency of spin searching through the pre-processing of the pattern to be searched. Now we will see that an alternative way of
-
4.4. Aligning sequences is an optimization problem
RechenmannFrançoisWe have seen a nice and a quitesimple solution for measuring the similarity between two sequences. It relied on the so-called hammingdistance that is counting the number of differencesbetween two
-
5.2. The tree, an abstract object
RechenmannFrançoisWhen we speak of trees, of species,of phylogenetic trees, of course, it's a metaphoric view of a real tree. Our trees are abstract objects. Here is a tree and the different components of this tree.
-
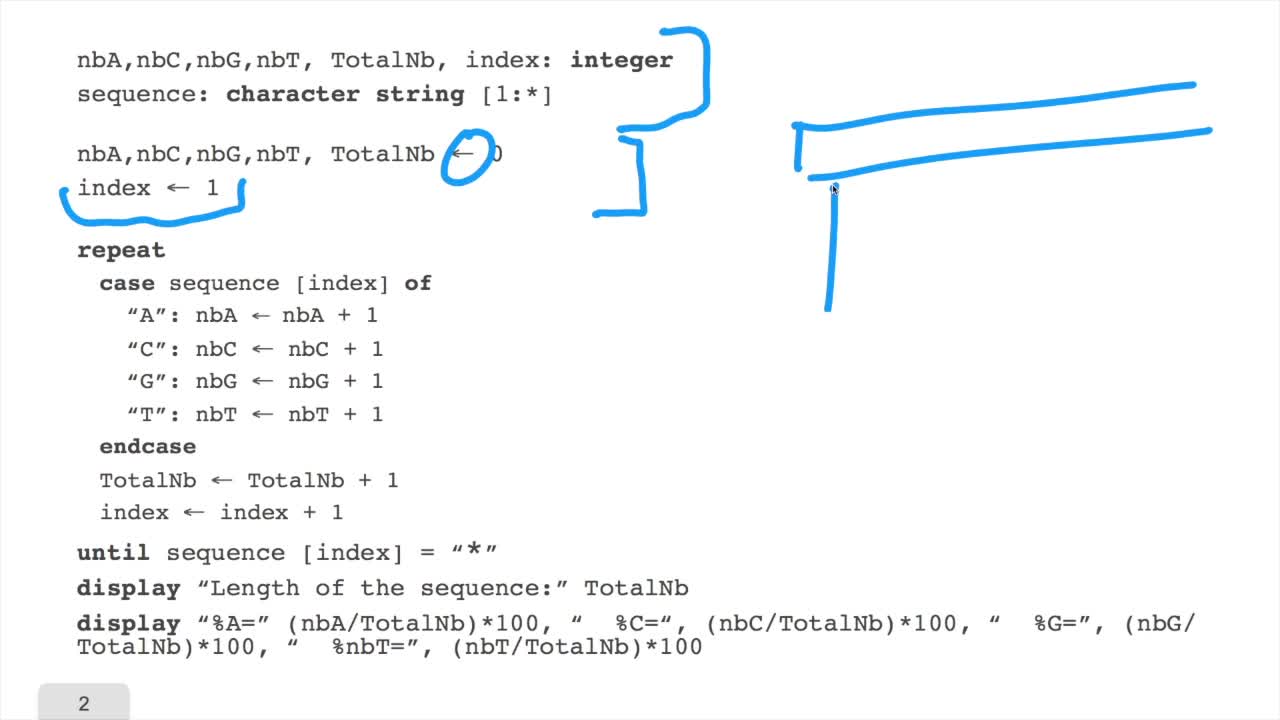
1.6. GC and AT contents of DNA sequence
RechenmannFrançoisWe have designed our first algorithmfor counting nucleotides. Remember, what we have writtenin pseudo code is first declaration of variables. We have several integer variables that are variables which
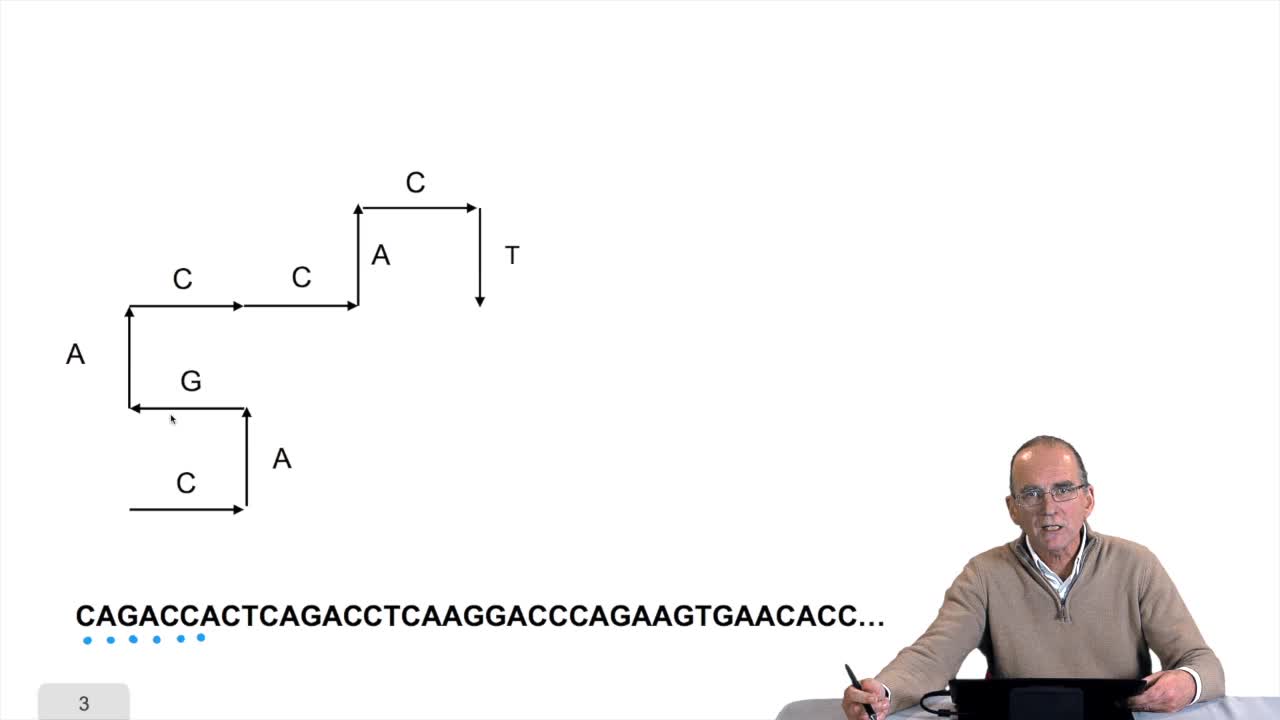






Sur le même thème
-
Le projet dnarXiv : Stockage de données sur des molécules d'ADN
LavenierDominiqueDuprazElsaLeblancJulienCoatrieuxGouenouDominique Lavenier, Elsa Dupraz, Julien Leblanc et Gouenou Coatrieux nous présentent le projet dnarXiv, un projet porté par le LabEx CominLabs qui explore le stockage de données sur des molécules d
-
Projection methods for community detection in complex networks
LitvakNellyCommunity detection is one of most prominent tasks in the analysis of complex networks such as social networks, biological networks, and the world wide web. A community is loosely defined as a group
-
Lara Croft. doing fieldwork under surveillance
Dall'AgnolaJasminLara Croft. Doing Fieldwork Under Surveillance Intervention de Jasmin Dall'Agnola (The George Washington University), dans le cadre du Colloque coorganisé par Anders Albrechtslund, professeur en
-
Containing predictive tokens in the EU
CzarnockiJanContaining Predictive Tokens in the EU – Mapping the Laws Against Digital Surveillance, intervention de Jan Czarnocki (KU Leuven), dans le cadre du Colloque coorganisé par Anders Albrechtslund,
-
Ivan Murit - Processus de création d'images
MuritIvanJe vais présenter une manière décalée d'aborder les outils d'impression. Pour cela nous ne partirons pas de l'envie d'imprimer une image préexistante, mais d'avant cela : comment se crée une forme
-
Le Creativ’Lab, au cœur de la robotique et de l’intelligence artificielle (ASR N°18 - LORIA)
HénaffPatrickLefebvreSylvainLe LORIA, laboratoire phare de la Grande Région dans le domaine de l’informatique, propose de rendre la recherche plus ouverte, plus collaborative, plus ambitieuse… en un mot, plus créative, à travers
-
Les algorithmes de Parcoursup
MathieuClaireL’objectif de la journée « Algorithmes d’aide à la décision publique » était de sensibiliser le grand public aux rôles des algorithmes d’aide à la décision publique utilisés par exemple pour l
-
Algorithmes d'aide à la décision publique / Ouverture
RéveillèreLaurentMaveyraud-TricoireSamuelBlancXavierBertrandYvesMainguenéMarcL’objectif de la journée « Algorithmes d’aide à la décision publique » était de sensibiliser le grand public aux rôles des algorithmes d’aide à la décision publique utilisés par exemple pour l
-
Quelques enjeux autour des algorithmes d'aide à la décision publique
TarissanFabienL’objectif de la journée « Algorithmes d’aide à la décision publique » était de sensibiliser le grand public aux rôles des algorithmes d’aide à la décision publique utilisés par exemple pour l
-
Un nouveau système de répartition des greffons cardiaques utilisant un algorithme
DorentRichardL’objectif de la journée « Algorithmes d’aide à la décision publique » était de sensibiliser le grand public aux rôles des algorithmes d’aide à la décision publique utilisés par exemple pour l
-
Règles, calcul et politique : investigation des choix de programmation inaperçus pour les aides au …
MerigouxDenisL’objectif de la journée « Algorithmes d’aide à la décision publique » était de sensibiliser le grand public aux rôles des algorithmes d’aide à la décision publique utilisés par exemple pour l
-
Algorithmes de décision publique : élaboration, évaluation et évolutions
MathieuClaireDorentRichardMerigouxDenisDauchetMaxKirchnerClaudeCattanJeanGimbertHugoL’objectif de la journée « Algorithmes d’aide à la décision publique » était de sensibiliser le grand public aux rôles des algorithmes d’aide à la décision publique utilisés par exemple pour l











